- The paper introduces TD3 as a continuous action space DRL method that overcomes the limitations of discrete trading approaches.
- It details an actor-critic architecture with dual critic networks to mitigate overestimation and enhance decision-making.
- Experiments on the Amazon and Bitcoin markets show improved risk-adjusted returns and greater trading flexibility.
Algorithmic Trading Using Continuous Action Space Deep Reinforcement Learning
This paper investigates a novel approach to algorithmic trading using continuous action space deep reinforcement learning (DRL). It introduces Twin-Delayed Deep Deterministic Policy Gradient (TD3) as a solution to address the limitations of discrete action space reinforcement learning algorithms in financial markets.
Introduction to Algorithmic Trading
Algorithmic trading involves using pre-programmed computer systems to execute trading strategies based on historical data analysis. The traditional approaches often rely on discrete action space algorithms, which restrict trading operations to predefined quantities of assets. This paper proposes TD3, which operates in a continuous action space, allowing traders to dynamically decide both the position and the number of shares to trade.
Reinforcement Learning and Its Application
Reinforcement Learning (RL) is a machine learning paradigm where an agent learns to make decisions by interacting with its environment to maximize a cumulative reward signal. Key components include states, actions, and reward functions. In this research, the RL framework is applied to trading strategies where the state space comprises percentage changes in the daily close prices of assets such as Amazon and Bitcoin (Figure 1).
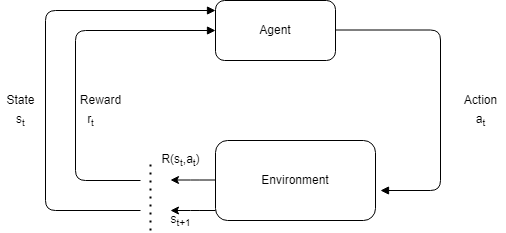
Figure 1: The RL process and components.
The continuous action space facilitates more flexible trading decisions, as opposed to rigid discrete choices, thus potentially enhancing profitability by adapting more fluidly to market conditions.
Technical Implementation of TD3
The implementation of TD3 is detailed, highlighting how it overcomes the limitations of previous DRL algorithms like the Deep Q-Network (DQN). TD3 uses an actor-critic architecture with two critic networks to mitigate overestimation problems prevalent in deterministic policy gradients. The model's robustness is further enhanced by using exploration and policy noise decays that adjust over training episodes.
The environment for this RL problem is defined using a continuous action space within the interval [−1,1], where actions reflect the proportion of cash dedicated to taking long or short positions. This setup affords flexibility in adjusting trading volumes based on market dynamics.
Experimental Results
Amazon Stock Market
In experiments with Amazon data, the continuous TD3 algorithm exhibits superior performance over discrete action approximation methods (Sign and D3) in terms of Return and Sharpe ratio (Figure 2).
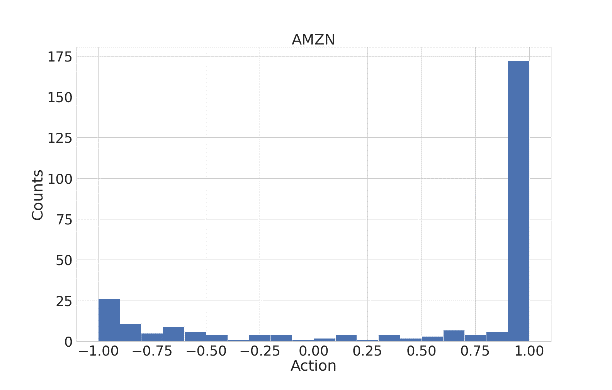
Figure 2: The histogram of Amazon market actions in the TD3 algorithm.
The statistical tests confirm that TD3 consistently provides better results, showcasing the advantages of continuous action spaces in achieving higher profitability and risk-adjusted returns.
Bitcoin Cryptocurrency Market
Results for the Bitcoin market further validate TD3's effectiveness. The discrete nature of actions due to the market characteristics did not hinder TD3's performance, indicating its adaptability across different financial assets (Figure 3).
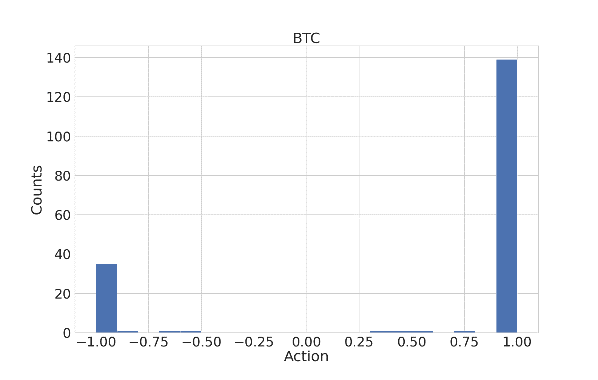
Figure 3: The histogram of Bitcoin market actions in the TD3 algorithm.
Comparative analysis with baseline models demonstrates TD3's superior performance, proving the efficacy of DRL approaches in algorithmic trading.
Conclusion
The research presents a compelling case for adopting continuous action space DRL models like TD3 in algorithmic trading. It illustrates how flexible position and share selection can substantially improve trading outcomes over traditional discrete RL methods. The robustness of TD3 in both stock and cryptocurrency markets serves as a testament to the potential of such algorithms.
Future work should consider refining reward functions and integrating ensemble learning techniques to further enhance algorithmic trading strategies. Additionally, expanding the variety and sources of input data could provide even more nuanced trading signals, making these models closer to real-world trading scenarios.
In summary, this paper lays a solid foundation for leveraging continuous action space DRL in commercial trading applications, offering a promising direction for future AI-driven financial market strategies.

