- The paper demonstrates that restricting TAPT to the embedding layer maintains performance while reducing computational parameters by 78%.
- It introduces a novel approach that freezes BERT encoder layers, focusing adaptation on task-specific dense layers for efficiency.
- Experimental results on IMDB, AG-News, Emotion, and BBC-News show sustained or improved accuracy despite a significant reduction in training overhead.
Towards Simple and Efficient Task-Adaptive Pre-training for Text Classification
Introduction
Large-scale Pre-trained LLMs (PLMs) play a critical role in modern NLP by leveraging massive generic datasets to learn contextual representations through masked language modeling (MLM) and next sentence prediction (NSP). Pre-training provides the linguistic foundation essential for a diverse range of downstream tasks, such as text classification. While initial pre-training is crucial for understanding language semantics, further customization through Domain Adaptive Pre-training (DAPT) and Task-Adaptive Pre-training (TAPT) is necessary to align models with specific domain vocabularies.
This paper investigates the potential to enhance the efficiency of task adaptation in BERT-based models by limiting intermediate pre-training (TAPT) to the embedding layer, thus drastically reducing the number of parameters involved in training and the corresponding computational overhead. It demonstrates that selective pre-training maintains performance while significantly cutting computational costs.
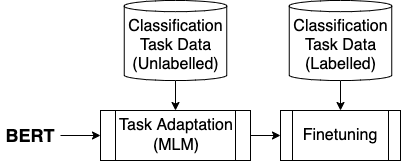
Figure 1: Representation of standard TAPT flow where pre-trained BERT is adapted to the target task using un-supervised MLM on task-specific data, followed by task-specific supervised finetuning.
Methodology
The standard TAPT process involves adapting a PLM to a target task using unsupervised data and subsequently fine-tuning it with supervised task data. The novel approach taken in this study involves freezing the BERT encoder layers during TAPT, updating only the embedding and task-specific dense layers. This strategy aims to specialize the representation to the domain-specific vocabulary without deleteriously affecting the pre-trained linguistic features.
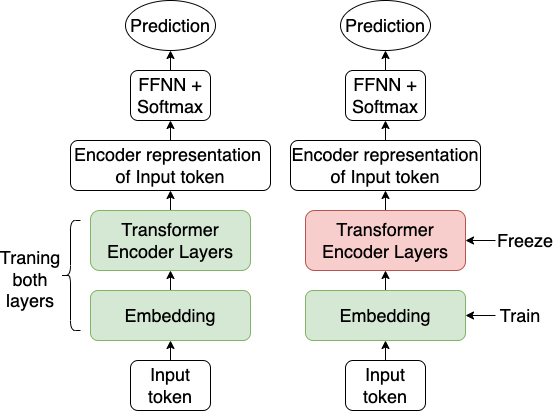
Figure 2: The left model depicts the standard TAPT flow, whereas the right model indicates the proposed TAPT approach where BERT encoder layers are frozen during intermediate pre-training.
Experimentation Setup
The experimental evaluation was conducted on four benchmark datasets: IMDB, AG-News, Emotion, and BBC-News, utilizing the BERT model with a focus on measuring the effects of training only the embedding layers during TAPT and different configurations during final finetuning.
Results
The proposed approach exhibits comparable performance to standard TAPT in terms of accuracy. The significant reduction of parameters—by 78%—translates into reduced training time and computational costs. Detailed results across various datasets reveal a slight improvement or parity in accuracy when employing the restricted TAPT setup.
Tables and metrics outline the tangible benefits of this task adaptation approach. Notably, the method shows that trainable parameter reduction during TAPT leads not only to computational efficiency but also to sustained or improved model accuracy across diverse test cases.
Implications and Future Directions
The efficient adaptation strategy proposed holds significant implications for resource-constrained scenarios in NLP model deployment. By minimizing computational demands, the approach is attractive for integrating PLMs in environments with limited processing power or energy resources, encouraging broader dissemination and application.
In theory, this efficient strategy does not compromise the model's ability to retain language characteristics, thus sidestepping issues of catastrophic forgetting. Future research directions could explore the scalability of such methods to other architectures beyond BERT and the real-world effects on model robustness.
Conclusion
The study underscores the potential for more efficient domain and task adaptation strategies in PLMs, with a focus on BERT. By restricting the training process during TAPT to only the embedding layer, it effectively balances adaptation performance and computational efficiency. The findings challenge traditional notions of extensive parameter training during intermediate pre-training, paving the way for more adaptive, eco-friendly NLP model deployment. This method not only maintains accuracy but also substantially reduces the environmental and financial impacts of model training.

