- The paper demonstrates a weakly supervised method that achieves improved strict F1 scores, with JobBERT reaching 49.44 on SkillSpan.
- It integrates the ESCO taxonomy with advanced embeddings from RoBERTa and JobBERT using strategies like WSE, AOC, and ISO.
- This approach reduces annotation costs while offering scalability and potential for multilingual applications in job matching.
Introduction
The task of automatic Skill Extraction (SE) is crucial for deriving insights into labor market demands and enhancing job matching efficiency. Traditional methods for SE heavily rely on supervised learning, requiring annotated corpora, which is often costly and time-consuming to produce. This paper addresses these limitations by introducing a weakly supervised approach that leverages the European Skills, Competences, Qualifications, and Occupations (ESCO) taxonomy to identify similar skills in job advertisements through latent representations.
Methodology
The proposed method exploits the ESCO taxonomy to embed skill phrases and job posting n-grams into a shared vector space using LLMs such as RoBERTa and JobBERT (Figure 1). This enables the assignment of skill labels to job postings based on the similarity between the embeddings of n-grams and known ESCO skills.
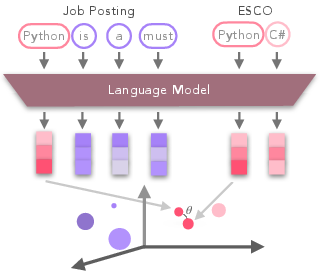
Figure 1: Weakly Supervised Skill Extraction embodies the synergy of ESCO skills and embedded n-grams through LLMs.
Several encoding strategies for skill representation are explored, including:
- Span in Isolation (ISO): Skills are encoded independently without context.
- Average over Contexts (AOC): Skills are encoded using surrounding context from the job postings dataset.
- Weighted Span Embedding (WSE): Skills are encoded with inverse document frequency (IDF) weighted sums.
These representations are then matched with n-grams derived from job descriptions, ranked by cosine similarity.
Data and Analysis
The analysis utilizes datasets from SkillSpan and modified Sayfullina, with an emphasis on the linguistic characteristics of ESCO skills, which predominantly consist of verb-noun phrases (Figure 2). These insights drive the n-gram selection and inform the matching process with ESCO-based embeddings.
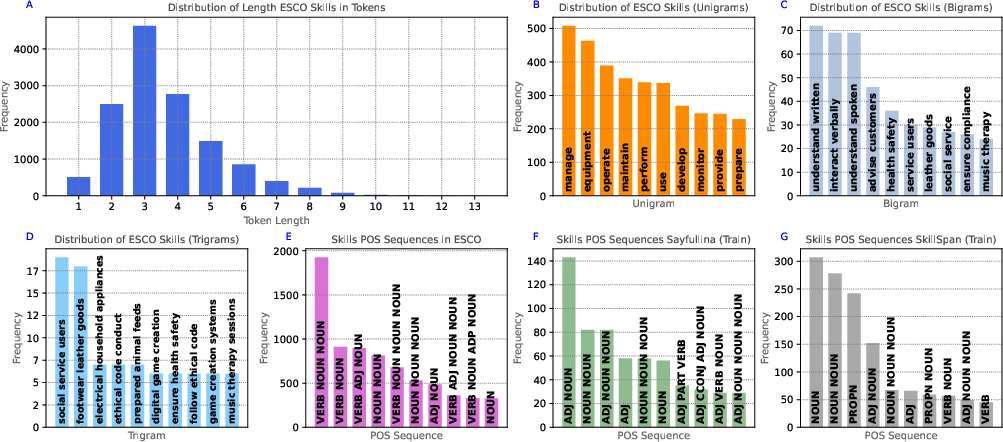
Figure 2: Surface-level Statistics of ESCO, detailing token lengths and common linguistic patterns.
Results
The weak supervisory approach is benchmarked against traditional baselines. Results indicate that RoBERTa and JobBERT equipped with advanced skill representation methods like WSE significantly outperform exact and lemmatized matching in strict F1 metrics across both SkillSpan and Sayfullina datasets. Notably, JobBERT achieves a strict F1 of 49.44 on SkillSpan, demonstrating its effectiveness over RoBERTa in handling more complex domains.

Figure 3: Comparative performance of various methods on different datasets, highlighting the improvements achieved through advanced embedding strategies.
Discussion
The research highlights the potential of leveraging latent representation-based weak supervision to bypass the intensive annotation process traditionally required for SE. The superior performance, particularly in loose F1 metrics, suggests that the approach captures partial matches effectively, critical in complex skill extraction scenarios. Such methods could scale to multilingual contexts, leveraging ESCO's multilingual capabilities.
Conclusion
The integration of ESCO taxonomy with weakly supervised latent representation learning presents a viable alternative to supervised skill extraction in job postings. The approach aligns well with evolving job market dynamics, offering a scalable solution capable of addressing the variability and complexity inherent in skill extraction tasks.
Future developments could explore multilingual applications and the integration of refined methods such as post-editing or candidate filtering to enhance accuracy further. The research lays the groundwork for more efficient AI-driven solutions in employment and economic forecasting domains.

