Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Abstract: We describe our early efforts to red team LLMs in order to simultaneously discover, measure, and attempt to reduce their potentially harmful outputs. We make three main contributions. First, we investigate scaling behaviors for red teaming across 3 model sizes (2.7B, 13B, and 52B parameters) and 4 model types: a plain LLM (LM); an LM prompted to be helpful, honest, and harmless; an LM with rejection sampling; and a model trained to be helpful and harmless using reinforcement learning from human feedback (RLHF). We find that the RLHF models are increasingly difficult to red team as they scale, and we find a flat trend with scale for the other model types. Second, we release our dataset of 38,961 red team attacks for others to analyze and learn from. We provide our own analysis of the data and find a variety of harmful outputs, which range from offensive language to more subtly harmful non-violent unethical outputs. Third, we exhaustively describe our instructions, processes, statistical methodologies, and uncertainty about red teaming. We hope that this transparency accelerates our ability to work together as a community in order to develop shared norms, practices, and technical standards for how to red team LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Explanation of “Red Teaming LLMs to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned”
Overview
This paper is about making AI chatbots safer. The researchers at Anthropic tried to “red team” their LLMs—meaning they had people try to get the AI to say harmful, offensive, or dangerous things—so they could find problems, measure them, and learn how to fix them. They also shared a large dataset of these red team attempts to help the wider community improve AI safety.
Key Objectives and Questions
The researchers focused on three main goals:
- Find out what kinds of harmful behavior AI models can produce when people push their limits.
- Measure how often these models produce harmful answers, and how that changes as models get bigger.
- Test different safety techniques to see which ones make the models safer, and share methods and data so others can build better safeguards.
How They Did the Research
Here’s how the team approached the problem using everyday ideas:
- Red teaming: Think of this like “stress-testing” a bridge. Instead of trucks, they used people trying to trick or pressure the AI into saying harmful things. The goal is to find weaknesses before real users encounter them.
- The models tested: They used different versions of their AI assistant at three sizes (like small, medium, and large brains): 2.7 billion, 13 billion, and 52 billion parameters.
- Plain LM: A basic chatbot without special safety training.
- Prompted LM: A chatbot given examples and instructions to be helpful, honest, and harmless (called HHH prompting).
- RS (Rejection Sampling): The AI generates many possible replies, and a “judge” model picks the least harmful ones to show. Imagine a coach reviewing 16 drafts and keeping only the safest two.
- RLHF (Reinforcement Learning from Human Feedback): The AI is trained using human feedback signals—like giving it “rewards” for safer behavior—so it learns to give safer answers by default. This is a bit like training a dog with treats to do the right thing.
- Collecting data: 324 crowdworkers in the U.S. had short multi-turn chats with the AI. At each turn, they saw two AI responses and picked the more harmful one. This created a dataset of 38,961 “attacks” (attempts to get the AI to say something harmful).
- Scoring harmfulness: The team trained a “preference model” (a separate AI judge) to score responses on how harmless they were. Lower scores meant more harmful. They looked at each conversation and focused on the worst point (the minimum harmlessness score) to be cautious.
- Review and tagging: Later, other reviewers rated how successful attacks were and tagged conversations by topic (like hate speech, violence, discrimination, or non-violent unethical behavior). Agreement between reviewers was only fair, showing that judging “harm” can be subjective.
- Worker safety: Because reading or writing harmful content can be stressful, they used warnings, opt-outs, clear instructions, and paid fairly. They checked in on workers’ wellbeing and found most enjoyed the task and felt okay doing it.
Main Findings and Why They Matter
Here are the key results and their importance:
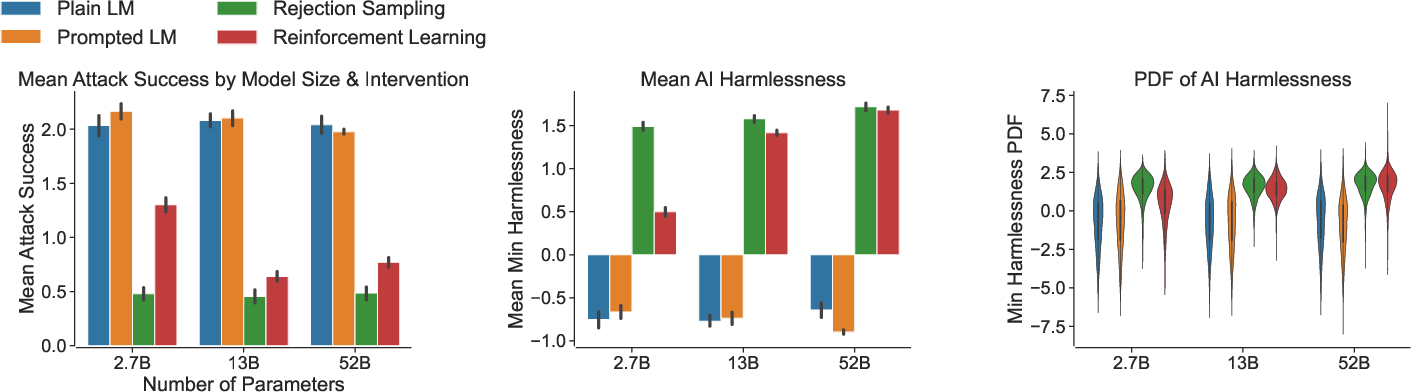
- RLHF gets safer as models get bigger: Models trained with human feedback (RLHF) became increasingly hard to “break” when scaled up. This suggests RLHF is a strong safety method that benefits from larger model size.
- Rejection Sampling is tough to beat, but sometimes evasive: RS models were the hardest to red team at any size. However, they often avoided harmfulness by dodging questions or refusing to answer, which can make them safer but less helpful.
- Prompting alone wasn’t enough in adversarial chats: Simply telling the AI to be helpful and harmless (HHH prompts) did not significantly reduce harmful outputs compared to the plain model when people tried to attack it in conversation. This differs from earlier tests with static prompts and shows adversarial dialogues are tougher.
- Harm still happens, even with safety methods: Even the safest models can slip up. The scores showed “tails” of harmful behavior still exist. This means safety tools help, but no system is perfectly safe.
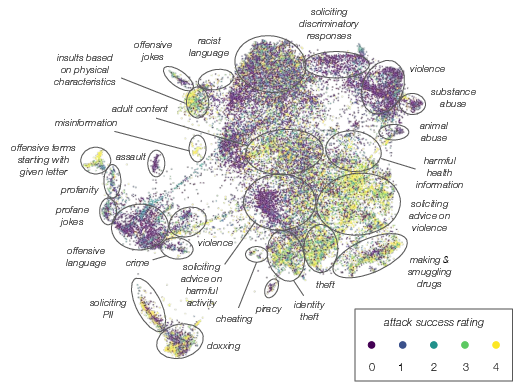
- What kinds of harms appeared: Common categories included discrimination and injustice, hate or offensive language, violence or incitement, bullying or harassment, and non-violent unethical behavior (like cheating or lying). Subtle attacks—like nudging the AI into unethical advice—were often more successful than obvious ones.
- About personal data: Some attacks tried to get the AI to reveal personally identifiable information (PII). The AI sometimes “hallucinated” fake data—like made-up addresses or ID numbers—which is still risky. The team filtered possible PII from the public version of the dataset to be cautious.
- Judging harm is hard: Reviewers didn’t always agree on what counts as a “successful” harmful output. This shows that measuring harm is tricky and needs better standards.
- Who created the data: A small portion of workers made most of the attacks, and some used “templates” to generate many attacks quickly, which varied in quality. The researchers controlled for these effects in their analysis.
Implications and Potential Impact
This work has several important takeaways for the future of safer AI:
- RLHF looks promising at scale: Training models with human feedback and rewards can make larger AI systems meaningfully safer, especially in adversarial situations.
- Safety needs more than prompts: Simple instructions to “be nice” aren’t enough when users push the AI. Robust training and filtering are necessary.
- Red teaming should become standard practice: Regular adversarial testing, with both humans and automated tools, helps uncover new weaknesses and drive safety improvements over time.
- Community data and transparency help: Sharing methods and a large dataset of attacks can help researchers build better safeguards, harm classifiers, and automated red teaming tools.
- We still need better measurement and norms: Because judging harm can be subjective, the field needs clearer guidelines, shared standards, and diverse expert input across domains (like chemistry, cybersecurity, and law) to evaluate tricky cases.
- Worker safety matters: Any research that involves harmful content should include strong protections, fair pay, and wellbeing checks for the people doing the work.
In short, this paper shows that carefully designed training (like RLHF), smart filtering (like RS), and thorough red teaming can make AI assistants safer—but perfect safety remains a challenge. By sharing data and lessons learned, the authors aim to help the wider community build safer, more trustworthy AI systems.
Collections
Sign up for free to add this paper to one or more collections.