- The paper introduces a dynamic, input-aware checkpointing strategy that leverages an online memory prediction model for efficient GPU training.
- It employs a quadratic regression-based memory estimator and a caching memory scheduler to minimize overhead and adapt to varying input sizes.
- Evaluation on NLP tasks shows improved training throughput and lower memory consumption compared to static checkpointing planners, while preserving convergence.
Introduction
Mimose introduces a dynamic, input-aware checkpointing strategy designed to enhance GPU memory utilization during deep learning (DL) model training. By leveraging a novel online memory prediction model, Mimose addresses the challenges posed by the fluctuating input tensor sizes commonly encountered due to diverse datasets and data augmentation practices. These fluctuations necessitate an adaptable checkpointing strategy that can optimize memory usage without incurring significant computational overhead.
The training process in DL models often involves input tensor dynamics caused by varying dataset characteristics and data augmentation techniques. For instance, datasets like SWAG, SQuAD, and GLUE-QQP exhibit distinct input size distributions that, in turn, influence GPU memory requirements.
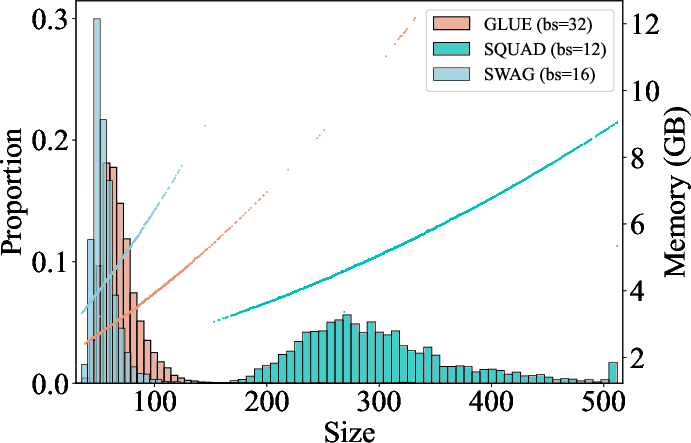
Figure 1: Input size distributions of SWAG, SQuAD, GLUE-QQP datasets (left y-axis) and GPU memory footprints (right y-axis) when training Bert-base with batch size set to 16, 12, 32, respectively.
Traditional static checkpointing planners rigidly adhere to a conservative memory allocation strategy based on the maximum anticipated input size, leading to inefficiencies when processing smaller inputs. On the other hand, while dynamic planners such as DTR provide real-time adjustments, they often incur excessive overhead by regenerating checkpoint plans for repeated inputs, resulting in a notable computational cost (Figure 2).
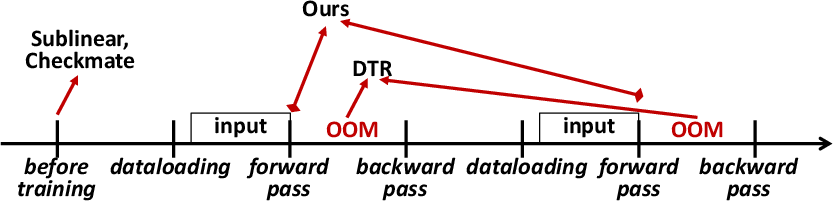
Figure 2: Comparison across prior checkpointing planners, where x-axis indicates the timeline. The red arrow indicates the moment of checkpointing plan generation.
Mimose Architecture and Methodology
Mimose is architectured around three key components: a shuttling online collector, a lightning memory estimator, and a responsive memory scheduler. These components collectively facilitate the agile and efficient generation of checkpointing plans suitable for input tensors of varying sizes.
Shuttling Online Collector
The shuttling online collector operates by executing forward layer computations twice. This strategy allows it to collect per-layer memory usage data without exceeding the GPU's memory capacity. To address the PyTorch eager execution model's semantics, a data filter is applied to ensure the integrity of collected memory usage statistics.
Lightning Memory Estimator
The memory estimator leverages a quadratic polynomial regression model, which has been empirically validated to accurately predict the memory usage characteristics of activation tensors under varying input conditions. Its use of regression models achieves a balance between prediction accuracy and computational efficiency, with negligible latency and error rates.
Responsive Memory Scheduler
The memory scheduler incorporates a caching mechanism, reusing previously computed checkpointing plans for similar input sizes to minimize redundant computations. It applies a greedy algorithm to determine the optimal layers for checkpointing, preferring checkpoints earlier in the forward pass to mitigate peak memory consumption during backward passes (Figure 3).
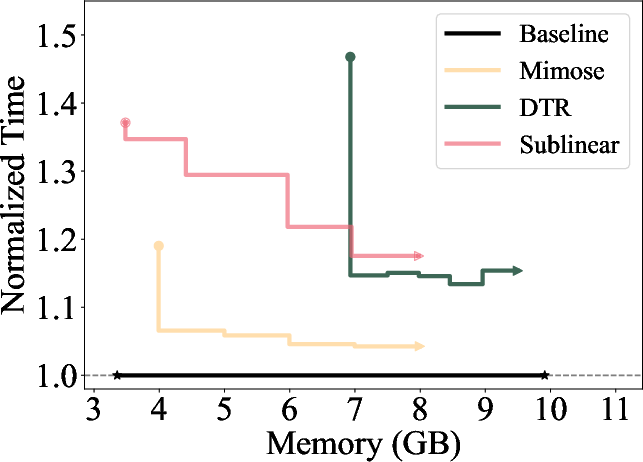
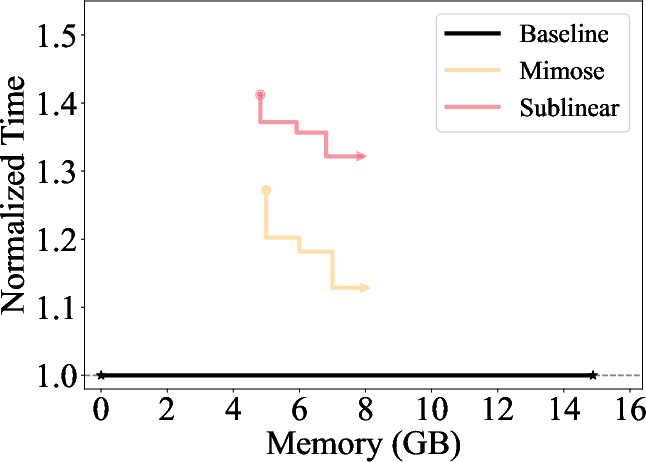
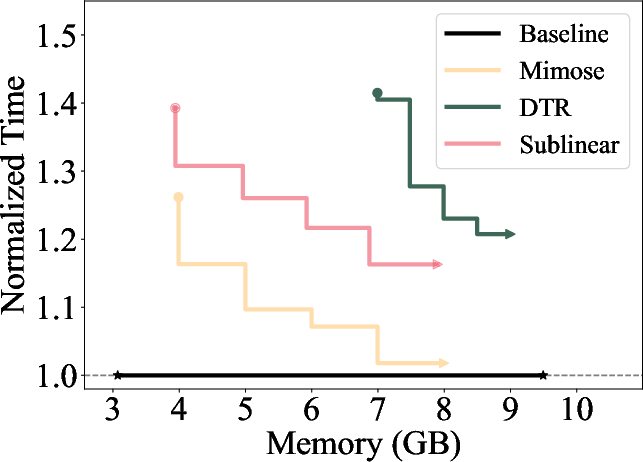
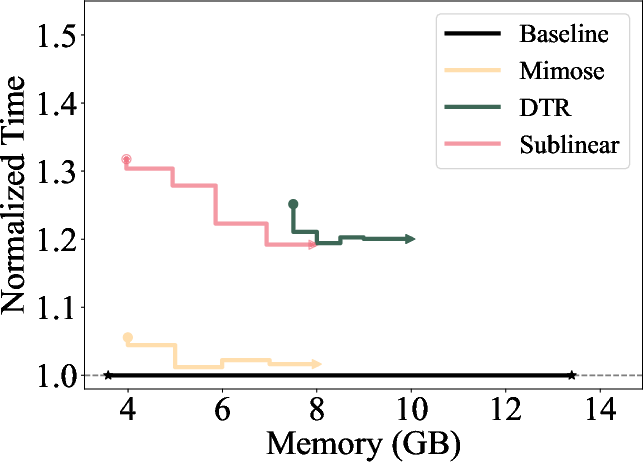
Figure 3: Single-epoch times for different methods normalized to Baseline (original PyTorch without memory limit), where x-axis represents the memory budget.
Evaluation and Results
Mimose was evaluated across several NLP tasks, demonstrating consistent improvements in training throughput compared to existing planners like Sublinear and DTR. Notably, Mimose's ability to adapt checkpoint plans to current input conditions resulted in significant reductions in training time, even under constrained memory budgets, as depicted in the memory consumption analysis (Figure 4).
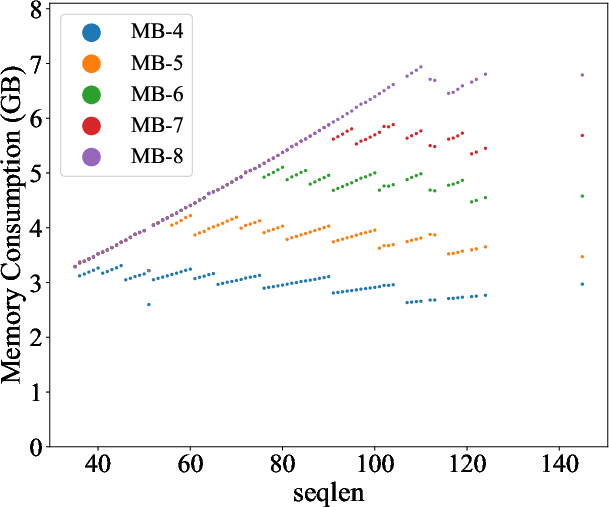
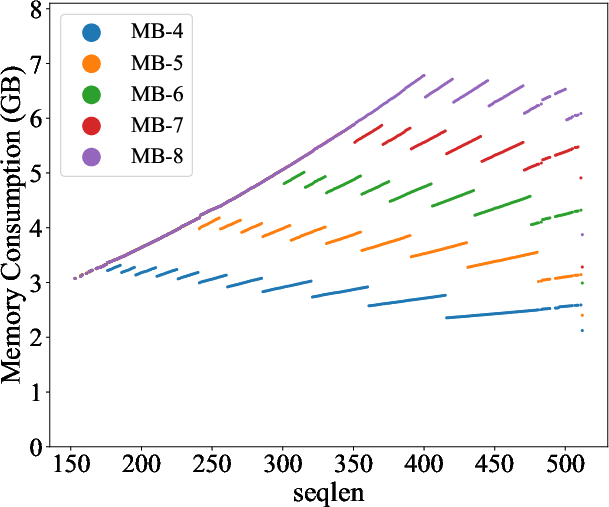
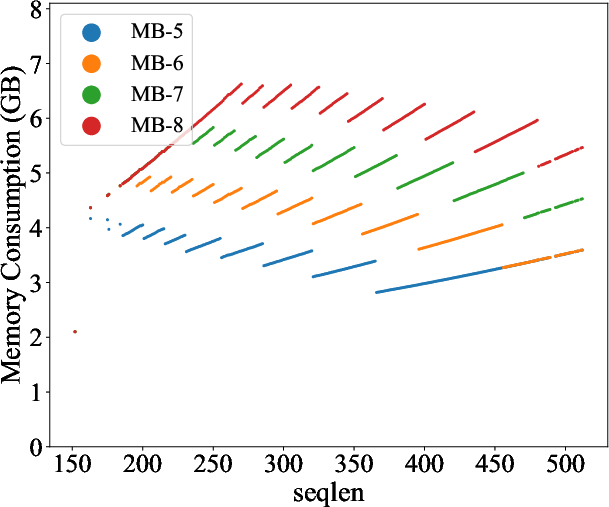
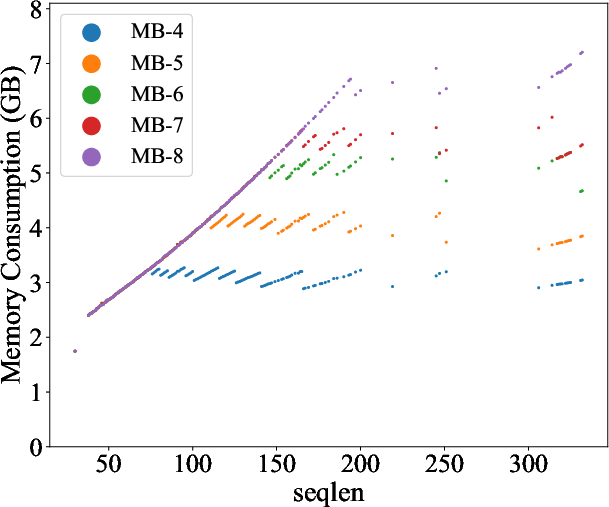
Figure 4: The memory consumption of Mimose processing varying sequence lengths, where MB-X refers to the memory budget of X GB.
In terms of convergence, Mimose maintained parity with the baseline without checkpointing, affirming its effectiveness in preserving model learning dynamics and ensuring consistent training outcomes.
Conclusion
Mimose's innovative approach to dynamic, input-aware checkpointing on GPUs represents a significant advancement in memory management for DL training tasks. By effectively harnessing input tensor dynamics, Mimose enhances GPU memory utilization while minimizing the overhead associated with checkpoint plan generation and application. Its superior performance across a range of NLP tasks underscores its potential as a robust solution for efficient model training under constrained memory environments. The implications for future work include extending Mimose's applicability to broader model types and exploring adaptive strategies for more complex memory patterns.