- The paper proposes the R-U-MAAD benchmark, a novel framework integrating simulation and real data to assess anomaly detection in multi-agent driving scenarios.
- It augments the Argoverse dataset with human-labeled anomalies, categorizing behaviors into 9 normal maneuvers and 13 distinct abnormal classes.
- Deep reconstruction models, especially STGAE, and one-class classifiers demonstrate robust performance with metrics like AUPR and AUROC.
A Benchmark for Unsupervised Anomaly Detection in Multi-Agent Trajectories
The paper "A Benchmark for Unsupervised Anomaly Detection in Multi-Agent Trajectories" proposes the R-U-MAAD benchmark to address the lack of a standardized framework for evaluating unsupervised anomaly detection (AD) techniques in the field of multi-agent driving behaviors. Using the Argoverse Motion Forecasting dataset as a foundation, the authors introduce an augmented test dataset with human-labeled anomalies tailored for urban traffic environments.
Motivation and Objectives
Self-driving vehicles must replicate human-like intuition to detect anomalous driving scenarios and take preventive measures accordingly. The absence of a comprehensive dataset for benchmarking AD models motivated the creation of the R-U-MAAD dataset. The benchmark's objective is to facilitate learning normal and abnormal driving behaviors using trajectories from the Argoverse dataset, both for model training without explicit anomaly labels and for testing with anomaly annotations. This work aims to set a baseline for AD in multi-agent trajectories using unsupervised learning methods.
Methodology and Dataset
The methodology hinges on hijacking a single vehicle from the Argoverse validation set to conduct scenario simulations in a multi-agent environment, thereby generating abnormal trajectory data through simulation while preserving normal driving sequences.
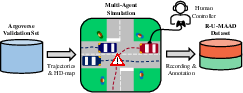
Figure 1: Our pipeline for abnormal trajectory generation, visualizing a scene from the HD-map with the target vehicle controlled for simulations.
A human operator induces abnormal scenarios, resulting in a dataset, R-U-MAAD, which includes individual and interaction-focused abnormalities. This dataset complements real-world trajectory data with simulation-derived anomalies.
Data Annotations
The paper meticulously annotates the driving behaviors as either normal with 9 distinct maneuvers, or abnormal with 13 unique anomaly classes such as ghost driving, aggressive maneuvers, and interactions leading to potential collisions.


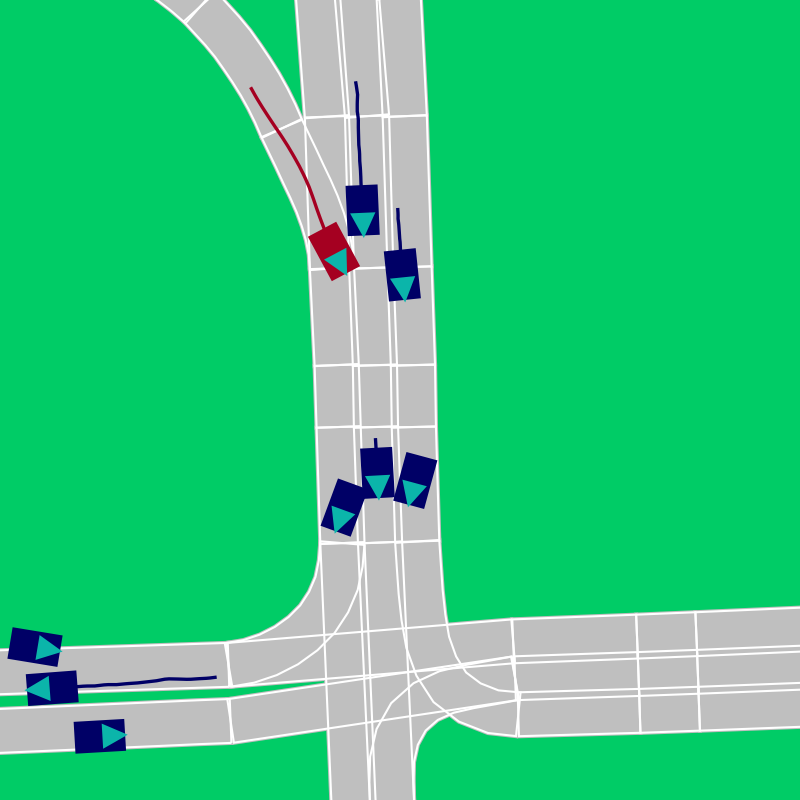
Figure 2: Example scenarios highlighting normal and abnormal interactions, mapping lane configurations and agent trajectories in diverse driving conditions.
Model Architectures and Baselines
The authors evaluate a rich suite of baseline models comprising linear, deep reconstruction, and one-class classification methods. The reconstruction models, notably sequence-to-sequence (Seq2Seq) variations and spatio-temporal graph auto-encoders (STGAE), adaptively approximate the path trajectories. Comparatively, one-class classifiers utilize Support Vector Machines (SVM) and Deep Support Vector Data Description (DSVDD) objectives to learn separation between normal and anomalous trajectory representations.
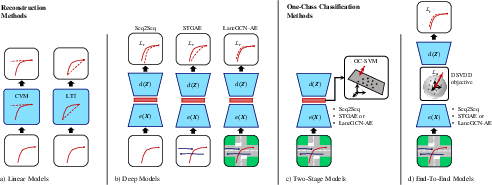
Figure 3: Comprehensive flow of anomaly detection baselines, distinguishing between trajectory reconstruction and one-class classification approaches.
Performance Evaluation
Deep auto-encoders particularly the STGAE model, demonstrated proficiency in generating representative feature spaces of normal driving, thereby achieving commendable performance metrics like AUPR-Abnormal and AUROC.
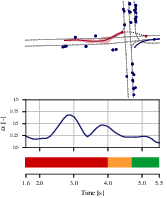
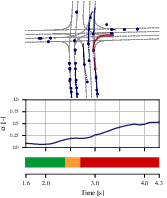
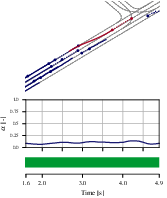
Figure 4: Qualitative assessments indicate score transitions in scenarios, with notable increases during abnormal behaviors and consistent low scores otherwise.
Experimental Results
The benchmark tests demonstrated that deep learning models, especially with enhancements incorporating spatio-temporal and context features like LaneGCN-AE, exhibit superior accuracy and reliability over traditional linear modeling techniques. Metrics like AUPR consistently highlighted the deep networks' edge in predictive fidelity under unsupervised learning paradigms. However, the potential of exploiting context-derived information indicates prospective research directions for augmenting anomaly detection segments.
Conclusion
The R-U-MAAD benchmark facilitates robust evaluation for anomaly detection in multi-agent traffic scenarios by blending real-world data with simulation-generated anomalies. The proffered baseline models offer a substantive comparison point for future advancements in unsupervised AD systems. The presentation emphasizes expanding research directions to exploit interaction-aware models effectively, thus enhancing the robustness of autonomous vehicle systems in detecting and adapting to unusual driving conditions.
This benchmark is poised to stimulate ongoing research and pave the way towards safer and more predictive autonomous navigation in dynamic, multi-agent environments.