- The paper introduces HR-VQVAE, which uses hierarchical residual quantization to overcome codebook collapse and enhance image reconstruction.
- The methodology optimizes multi-layer discrete representations, reducing reconstruction errors and search time compared to earlier VQVAE models.
- Experimental results show HR-VQVAE outperforms state-of-the-art models in metrics like FID and reconstruction error across multiple datasets.
Hierarchical Residual Learning Based Vector Quantized Variational Autoencoder for Image Reconstruction and Generation
Introduction
The paper introduces Hierarchical Residual Vector Quantized Variational Autoencoder (HR-VQVAE), a novel approach leveraging multi-layer vector quantized representations for image reconstruction and generation. HR-VQVAE proposes a hierarchical quantization strategy that enhances image quality while simultaneously addressing longstanding issues in discrete VAE models, such as codebook collapse. By building upon previous architectures like VQVAE and VQVAE-2, HR-VQVAE offers a more efficient and detailed representation, allowing for superior image reconstructions and generative performance.
Background
Traditional approaches to Variational Autoencoders (VAEs) often struggled with efficient representation due to continuous latents, leading to the development of discrete latent representations as seen in VQVAE models. VQVAE introduced discrete latent variables quantized through a k-means based approach, tackling the posterior collapse problem but facing codebook collapse due to inefficient utilization of codebook vectors [van2017neural]. VQVAE-2 extended this idea by structuring quantized codes hierarchically without addressing the collapse issue, limiting its capacity with larger codebooks.
HR-VQVAE Architecture
The HR-VQVAE constitutes a significant shift from its predecessors by employing a hierarchical architecture that quantizes residuals across layers, ensuring encoding of complementary information at each stage. The model's objective function encourages each layer to capture distinct residual information not addressed by previous layers, fostering more robust data encapsulation. This hierarchical encoding strategy is demonstrated in various visual illustrations:
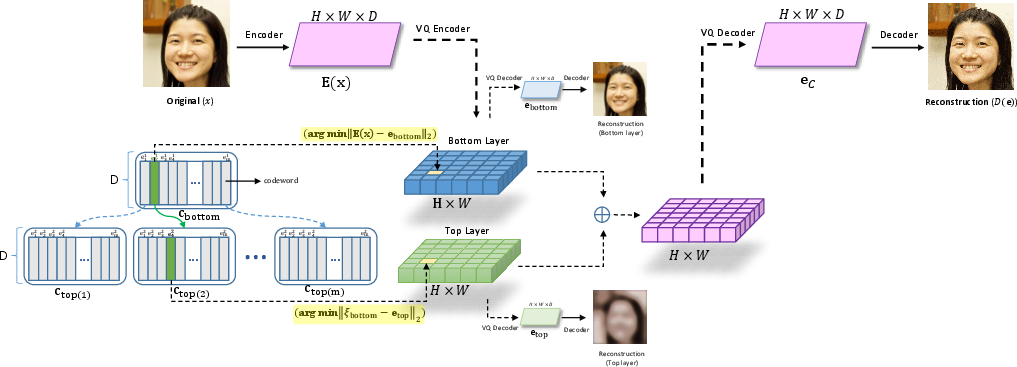
Figure 1: The HR-VQVAE method (only two consecutive layers are shown for simplicity).
Implementation and Methodology
HR-VQVAE employs a novel hierarchical codebook organization where each layer of the model contributes an additional discrete representation level. The hierarchy allows increased codebook sizes without the pitfalls of traditional k-means clustering, thereby avoiding codebook collapse. Optimization involves minimizing errors across layers using custom loss functions to jointly train the encoder's nonlinear transformation and the hierarchical codebook vectors.
Key experimental setups include using datasets such as FFHQ, ImageNet, CIFAR10, and MNIST, where HR-VQVAE's image reconstructions outperformed VQVAE and VQVAE-2 across various evaluation metrics like FID and reconstruction error:
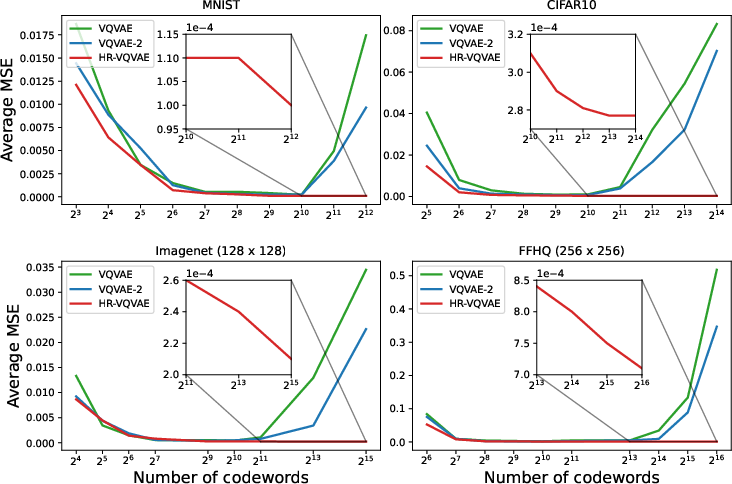
Figure 2: Average MSE vs number of codewords for different datasets and methods. Both VQVAE and VQVAE-2 collapse when the codebook size is increased over a certain limit. However, HR-VQVAE continues improving as shown in the zoom windows inside each plot.
Experiments and Results
Experimental evaluations demonstrated HR-VQVAE's robustness in maintaining high-quality reconstructions and generating diverse, realistic images. The model's ability to circumvent codebook collapse was evident as HR-VQVAE successfully benefitted from larger codebooks, unlike its antecedents. The methodology also boasts a significant reduction in search time due to the hierarchical structure's localized access to codebook layers:
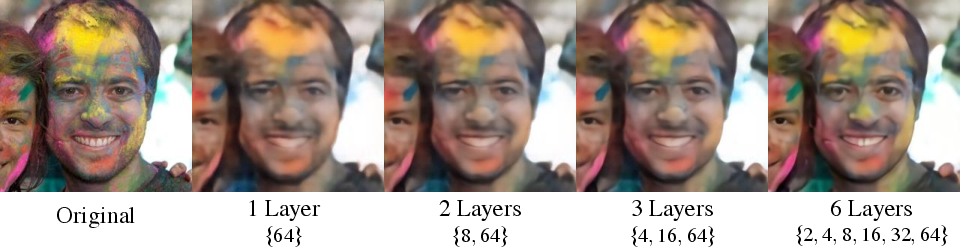
Figure 3: Reconstructions obtained with HR-VQVAE models with different depths (i.e., number of layers).
Further, HR-VQVAE outperformed state-of-the-art models like VDVAE and VQGAN on some metrics and applications, establishing its efficacy in generative tasks:

Figure 4: Random samples generated by HR-VQVAE on FFHQ 256×256 dataset.
Conclusion
HR-VQVAE represents a substantial innovation in the domain of image modeling through discrete representations. By implementing a hierarchical approach to vector quantization, it overcomes significant challenges faced by previous models, notably codebook collapse, and provides efficient decoding and representation learning. As the model scales with hierarchical layers, it encapsulates richer details, evidenced by both qualitative and quantitative superiorities. Future work could explore integrating Transformers for enhanced autoregressive modeling, potentially optimizing sampling efficiency and capturing complex data representations. This exploration could pave the way for even more sophisticated models supporting high-quality, diverse image generation.

