- The paper introduces a self-supervised model that aligns visual objects and words by constructing relational graph networks through cross-situational learning.
- It incrementally builds cross-modal networks integrating object-object, word-word, and object-word co-occurrence statistics to reduce mapping ambiguity.
- Experimental results demonstrate enhanced object-to-word mapping accuracy and effective zero-shot learning, offering improved AI interpretability.
Cross-Modal Alignment Learning of Vision-Language Conceptual Systems
The paper "Cross-Modal Alignment Learning of Vision-Language Conceptual Systems" (2208.01744) introduces a model that aims to construct vision-language conceptual systems by aligning visual objects and words, inspired by the word-learning mechanisms observed in human infants. This research advocates a self-supervised approach that uses co-occurrence statistics to gradually build relational graph networks, ultimately leading to aligned semantic representation vectors for multi-modal data.
Conceptual Framework
Human infants acquire language by linking heard words with visible objects, often in ambiguous contexts where multiple objects could correspond to a single uttered word. This ambiguity is systematically reduced as they accumulate exposure to different situations, a principle known as cross-situational learning (XSL). The paper implements a computational model based on XSL, wherein visual and textual data are continuously processed to form cross-modal relational graph networks. These networks enclose object-object, word-word, and object-word co-occurrence statistics derived from a dataset of images paired with text descriptions.
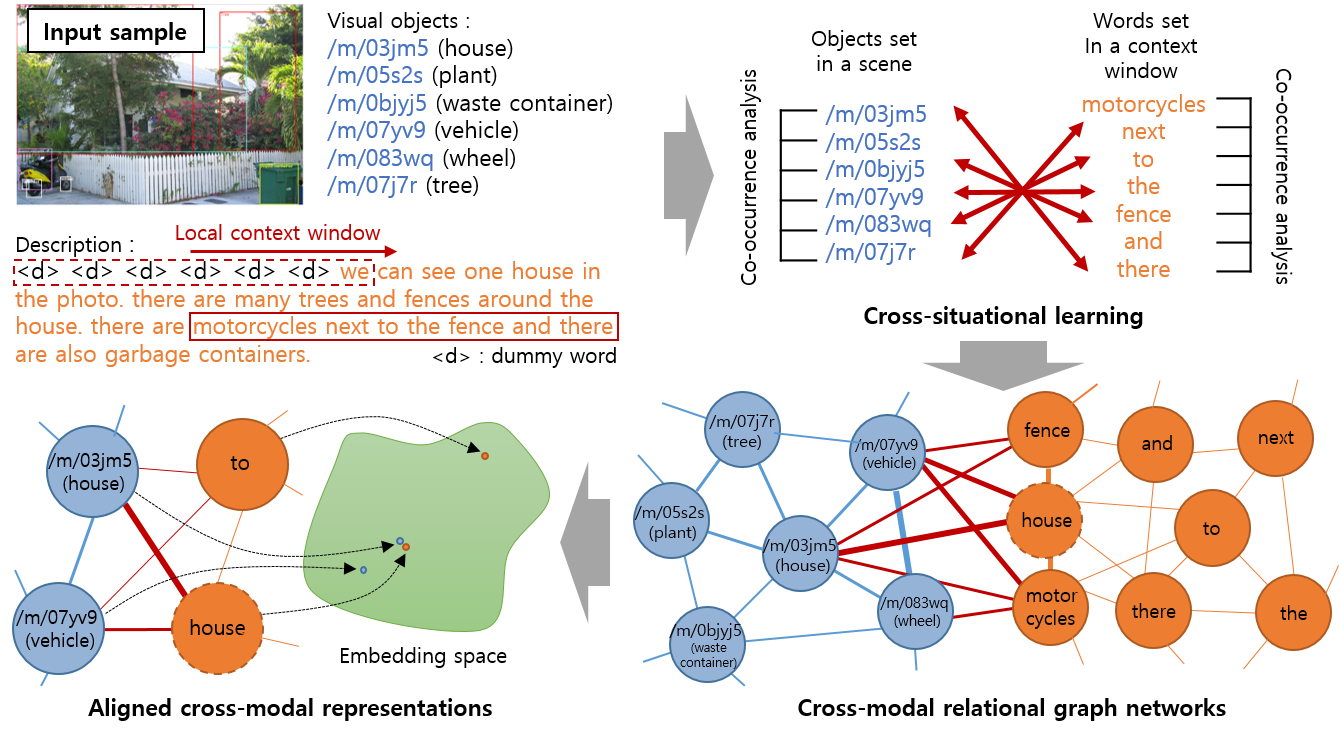
Figure 1: From the input sample, i) our model continuously learns object-object, word-word, and object-word co-occurrence statistics to construct cross-modal relational graph networks. ii) Based on the graph networks, it learns aligned semantic representations so that objects and words with conceptually the same meanings have similar representation vectors.
By leveraging these networks, the model aims to progressively align entities from different modalities—visual objects and linguistic terms—into a shared semantic space where conceptually similar pairs have representation vectors that are close. In effect, the distribution and relationships of objects and words are inferred from their frequency and context within the sample dataset.
Graph Network Construction
Starting with undirected weighted graph networks GW for words and GO for objects, the framework integrates these into cross-modal relational graph networks G. Constructed incrementally, these networks utilize co-occurrence statistics from multi-modal inputs, simulated as sequences combining object sets from images and corresponding local context word sets from descriptions.
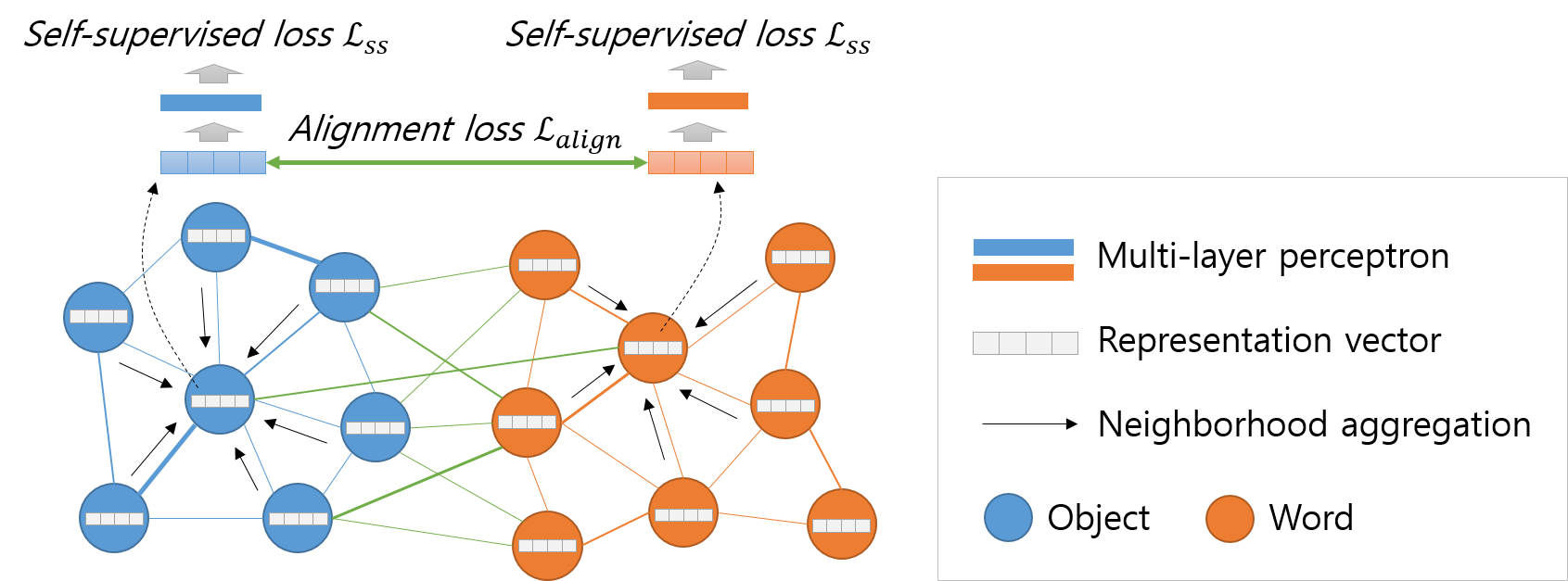
Figure 2: Overview of the aligned cross-modal representation learning method. First, we obtain a vector in which representation information of neighboring nodes is integrated using the neighborhood aggregation method. We then use the aggregated vector to minimize alignment and self-supervised losses. This process is performed for all nodes and edges of the graph networks.
An innovative cross-mapping approach facilitates the alignment of these networks by evaluating object-to-word mapping probabilities and iteratively adjusting graph structures based on acquired data. This process strives to reflect both global and local scene context by extracting meaningful relationships between entities, thereby reducing mapping ambiguity.
Aligned Semantic Representation Learning
By implementing a neighborhood aggregation technique, the model adjusts representation vectors of entities to integrate information from neighboring architectures in the constructed graph networks. This learning employs cross-entropy and alignment loss terms to guide the self-supervised identification and inter-modal correspondence of semantic representations.
Representation vectors are initially random but trained through an MLP optimizing an objective function comprised of self-supervised and alignment losses, aiming to retain identity per node while enforcing cross-modal semantic consistency. The method results in objects and words with conceptually similar meanings sharing close vectors in the semantic space, verified through zero-shot learning tasks where mappings are extrapolated from representation similarities rather than explicit co-occurrence.
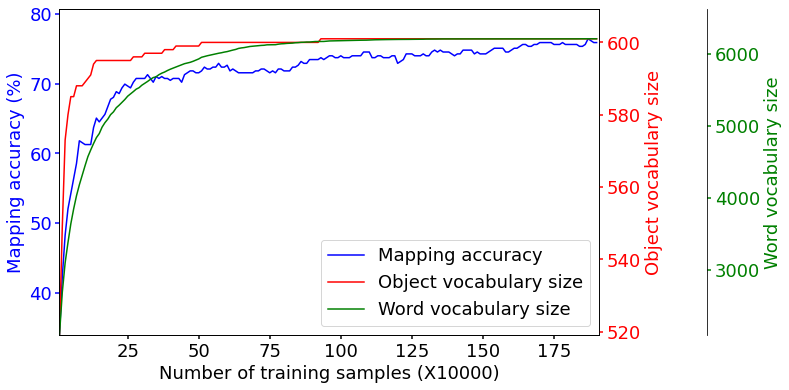
Figure 3: Object-to-word mapping accuracy with increasing training samples. The red and green lines indicate the accumulated size of object and word vocabulary, respectively. As learning progresses, the size of vocabulary increases, and the mapping accuracy also tends to increase continuously.
Experimental Validation
The paper evaluates its model through experimental tasks, including object-to-word mapping accuracy and zero-shot learning performance. In object-to-word mappings, the model showcased superior accuracy over baselines by leveraging its continuous learning architecture without a predetermined limit on the number of entities. Zero-shot evaluations tested the model's ability to align previously unencountered pairs, demonstrating foundational alignment even when explicit mapping data was absent.
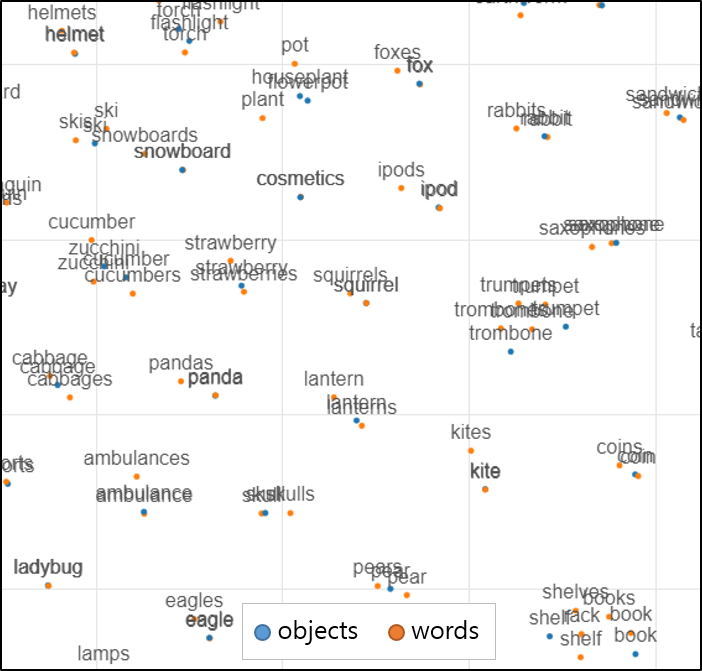
Figure 4: The visualization of the representation vector of the learned object and word using t-SNE. Objects and words with the same or similar meaning are distributed close to each other. For readability, only objects and words subject to mapping accuracy evaluation were visualized.
Practical Implications and Limitations
With applications spanning AV systems, human-computer interaction, and improved AI interpretability, the model presents a robust mechanism to bridge visual and linguistic domains autonomously. Despite promising results, limitations persist, such as the inability to map multi-word object names and handle synonym relationships comprehensively. Future work may target extensions across broader modalities and refined semantic relationships.
Conclusion
The presented model advances vision-language conceptual systems by persistently aligning cross-modal data inspired by natural cognitive processes, offering new avenues for self-supervised learning paradigms in AI applications, particularly in scenarios demanding nuanced understanding across visual and linguistic inputs.