- The paper demonstrates advanced use of deep and transfer learning to classify mental health conditions from social media texts.
- It shows that transformer models, especially RoBERTa, outperform traditional and deep learning techniques with an accuracy of 0.83.
- Results highlight potential for automated mental health screening and suggest a shift toward multi-label classification frameworks.
Mental Illness Classification on Social Media Texts using Deep Learning and Transfer Learning
The paper "Mental Illness Classification on Social Media Texts using Deep Learning and Transfer Learning" (2207.01012) presents a comprehensive study on classifying mental illness prevalence through text analysis of social media posts, particularly those on Reddit. The authors explore the use of machine learning, deep learning, and transfer learning to develop models capable of detecting common mental disorders such as depression, anxiety, bipolar disorder, ADHD, and PTSD. This classification approach aims to support public health systems by autonomously identifying individuals in need of assistance.
Introduction to Mental Health Detection Approaches
The paper begins by addressing the critical importance of detecting mental health issues amid the increased online presence due to social isolation measures, such as those observed during the COVID-19 pandemic. Traditionally, mental illness diagnoses have depended heavily on self-reported symptoms rather than laboratory tests, which opens the door to utilizing AI for enhanced analysis.
Recent advancements in AI have been applied to analyze large datasets of unstructured text data from social media platforms, allowing researchers to leverage these methods in understanding mental health conditions more robustly. This paper favors the analysis of Reddit posts due to their rich, expressive nature, unlike the previously popular Twitter data.
Problem Description and Dataset Analysis
The multi-class classification problem in this study involves categorizing Reddit posts into one of five mental illness classes, or a "none" category indicative of no illness. The dataset utilized encompasses 16,930 posts, already pre-processed for analysis, with statistics detailed in (Figure 1).
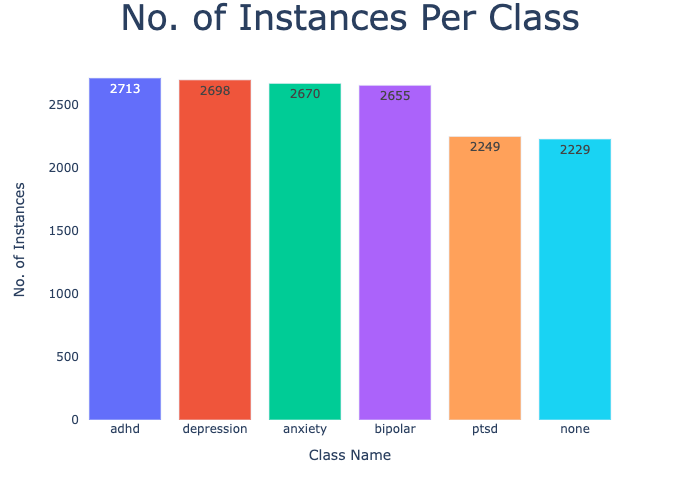
Figure 1: Mental Illness Dataset Statistics.
The methodology opted for further text preprocessing to optimize model inputs by normalizing text and removing non-essential components.
Methodological Framework
Machine Learning Techniques
Traditional machine learning models such as Random Forest, Support Vector Machine, Naive Bayes, and Logistic Regression were applied using word n-grams with TF-IDF values. Despite yielding reasonable predictive capability, ML models require manual feature engineering, a time-intensive process that deep learning approaches can potentially mitigate.
Deep Learning Architectures
Deep learning, with models such as GRU, LSTM, and CNN, form the backbone of advanced text analysis approaches in this study. Notably, the Bi-LSTM model emerged as the top performer among DL methods, highlighting its ability to capture temporal sequences effectively.
Transfer Learning Models
The study's seminal contribution pertains to its successful application of transformer-based models, notably BERT, XLNet, and RoBERTa. RoBERTa, markedly, outshines both traditional and deep learning counterparts, attaining an accuracy of 0.83, underscoring the prospect of transfer learning in extracting nuanced contextual information from texts.
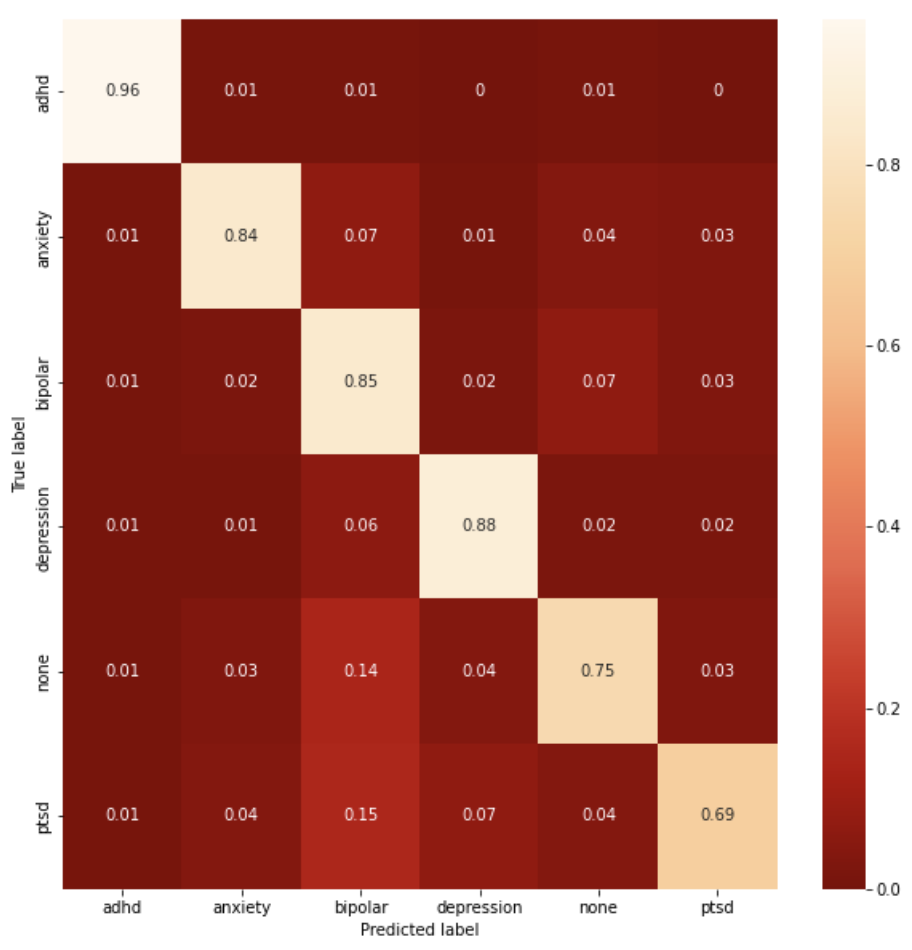
Figure 2: RoBERTa confusion matrix.
The confusion matrix (Figure 2) portrays RoBERTa's robust performance across multiple classes, especially in distinguishing non-mental illness posts with minimal false positives.
Results Discussion
The paper presents detailed numerical results, demonstrating RoBERTa's prominent classification efficacy. With precision and recall scores significantly higher than its peers, the model's capacity to decipher complex patterns revolving around mental health lingo prompts a discussion on its broader implications.
Despite encouraging outcomes, certain classes, such as depression and anxiety, reveal lower F1-scores. This potentially stems from the posts' brevity and semantic overlaps with other disorder contexts, challenging straightforward classification.
The authors argue for the potential evolution of classification tasks from multi-class to multi-label formats to better capture real-world complexities.
Conclusion
In sum, this research underscores the transformative power of transfer learning models like RoBERTa in mental health classifications, with significant implications for automated monitoring within the public health domain. It sets the stage for future exploration, suggesting advancements towards multi-label classification frameworks and ensemble modeling to bolster detection reliability.
This study represents a stride toward leveraging AI for societal good, with sizable implications for clinical psychological assistance and public health strategies during crises of social isolation.

