- The paper's main contribution is showing that SGD with weight decay effectively minimizes the rank of weight matrices through controlled update dynamics.
- The theoretical framework reveals that weight matrices in both convolutional and fully connected layers converge to bounded rank configurations under small batch conditions.
- Empirical analyses on architectures like ResNet and VGG confirm that a lower rank bias correlates with slightly improved test performance while offering insights into model generalization.
SGD and Weight Decay Secretly Minimize the Rank of Your Neural Network
Introduction
The paper explores how Stochastic Gradient Descent (SGD) combined with weight decay implicitly biases neural networks towards learning weight matrices of low rank. This property is examined across various architectures, without assumptions regarding data or convergence, distinguishing it from existing literature. The study provides theoretical predictions and empirical validations that smaller batches, higher learning rates, and increased weight decay accentuate this bias.
Theoretical Framework
The analysis begins by demonstrating that the rank of gradients with respect to any weight matrix is upper-bounded by the number of patches in a convolutional layer or by 1 for fully connected layers. This implies that SGD produces updates of bounded rank, particularly when using small batch sizes. This foundational observation is further extended to show that weight matrices evolve toward having bounded rank as training progresses under mini-batch SGD with weight decay.
This behavior is explained via Lemma 3.2, stating that WTl can be seen as a combination of the original matrix and a sum of gradients, each with bounded rank. Over iterations, this sum leads to a negligible distance from a low-rank configuration, formalized as follows:
Theorem 3.4: For large T, the normalized weight matrices ∥WTl∥WTl approximate a matrix of rank ≤2μλmlBlog(2/ϵ), highlighting the central thesis that SGD implicitly enforces low rank.
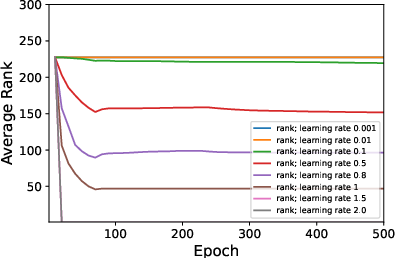
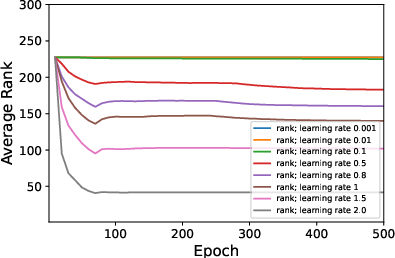
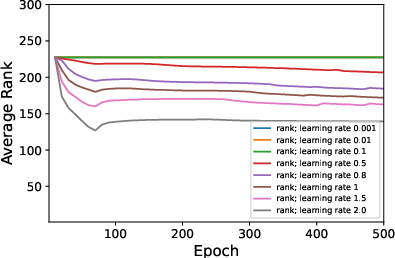
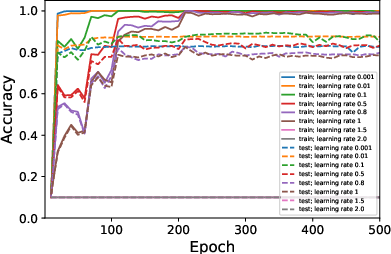
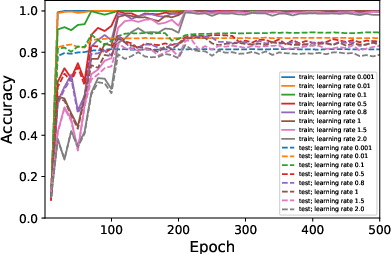
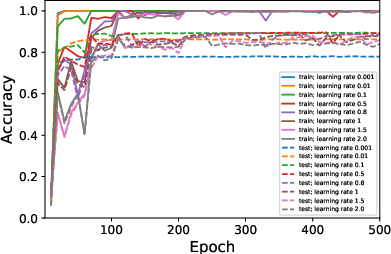
Figure 1: Average ranks and accuracy rates of ResNet-18 trained on CIFAR10 when varying μ.
Empirical Analysis
To validate theoretical predictions, comprehensive experiments were conducted with different architectures like ResNet-18, MLP-BN-10-100, VGG-16, and ViT across datasets including CIFAR10, MNIST, and SVHN.
Key Observations:
- Decreased batch size or increased learning rates and weight decay consistently result in lower rank weight matrices.
- The absence of weight decay significantly reduces or nullifies the observable low-rank bias, even with adjustments to μ or B.
- Surprisingly, despite its minimal impact on generalization, a lower-rank bias correlates with slightly better test performance.
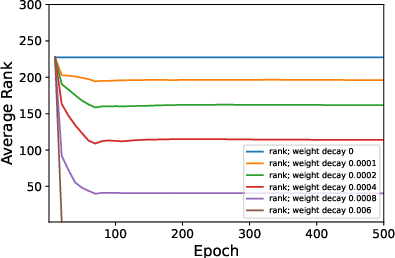
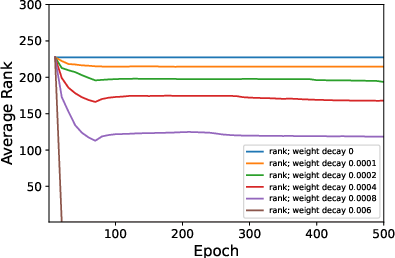
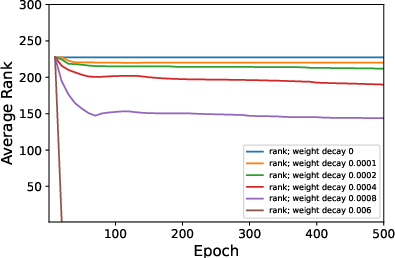
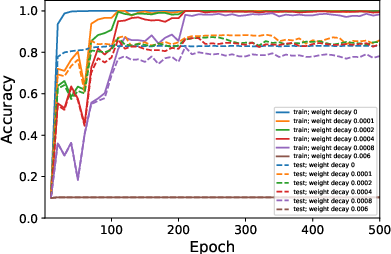
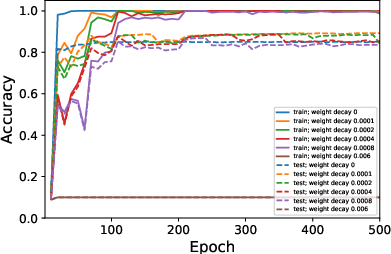
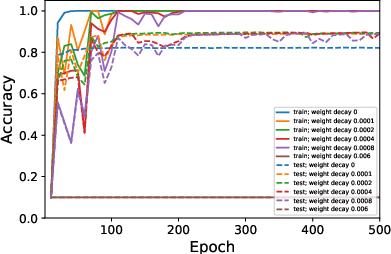
Figure 2: Average ranks and accuracy rates of ResNet-18 trained on CIFAR10 when varying λ.
Discussion
The paper's implications are significant for understanding the dynamics of modern deep networks. The implicit regularization via SGD, specifically the minimization of rank, provides insights into how models trained this way can effectively generalize. Although low-rank configurations are not singularly responsible for this generalization, they appear to support it. The results suggest that tuning hyperparameters to influence this bias could serve as an additional tuning mechanism to achieve desired model characteristics.
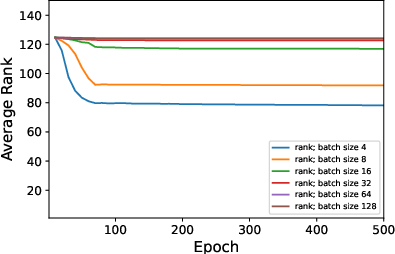
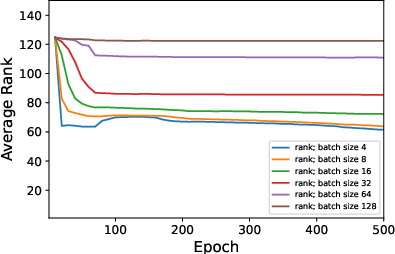
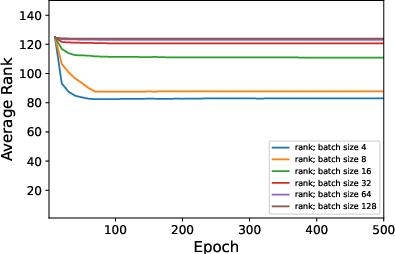
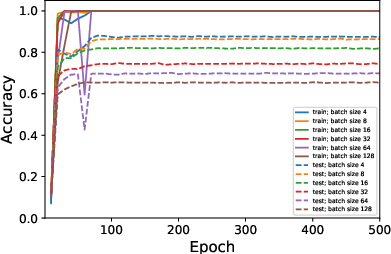
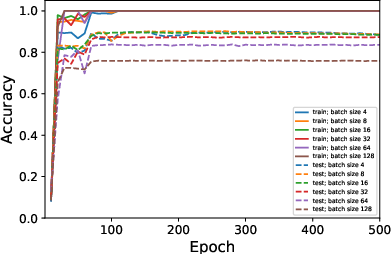
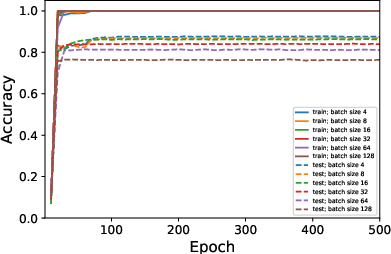
Figure 3: Average rank of Figure 4 trained on CIFAR10 when varying ϵ in rank approximation.
Future Work Considerations
The paper prompts several avenues for future exploration:
- Extensions of this theory to other forms of SGD-like optimizations or alternative regularization frameworks.
- Studies on the interaction with other forms of implicit bias such as sparsity induction or dropout.
- An exploration into the consequences of low-rank bias on overall network interpretability.
Conclusion
This study elucidates a subtle yet pervasive bias in neural network training. By demonstrating that SGD implicitly prefers low-rank weight configurations through theoretical and empirical means, it bridges an important gap in understanding the inner workings of deep learning. Although limited in its standalone influence on generalization, this rank minimization bias forms an essential part of the toolkit for characterizing and enhancing model performance.

