Offline Reinforcement Learning with Causal Structured World Models
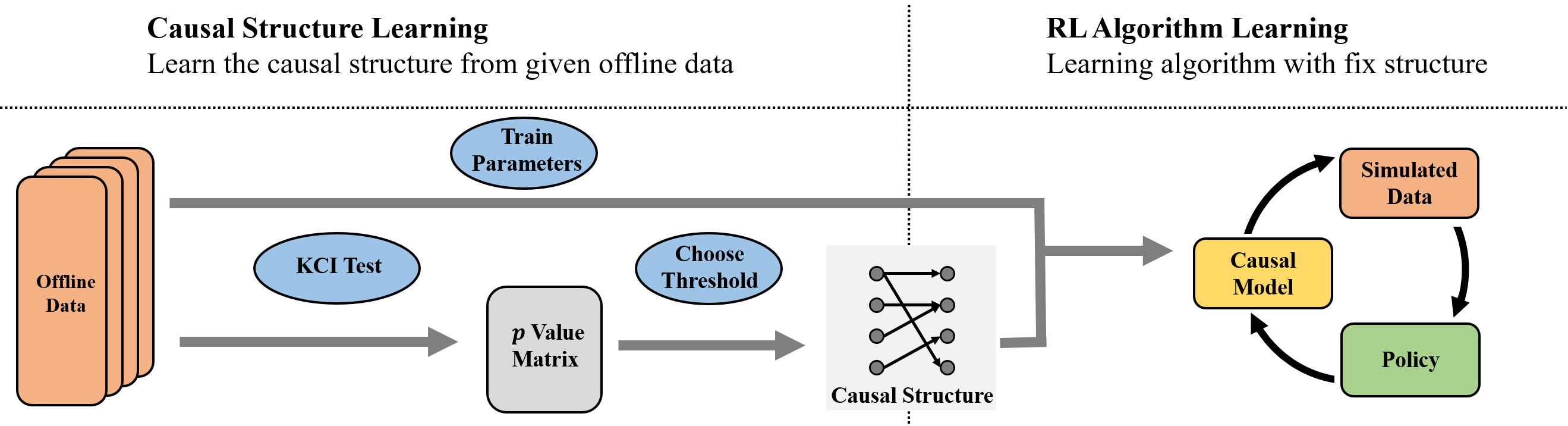
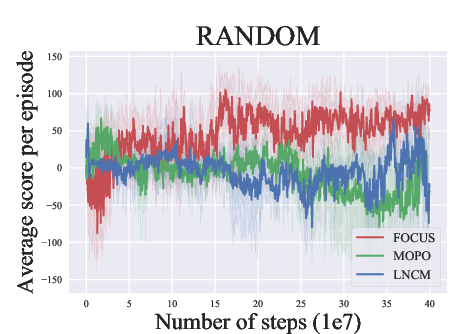
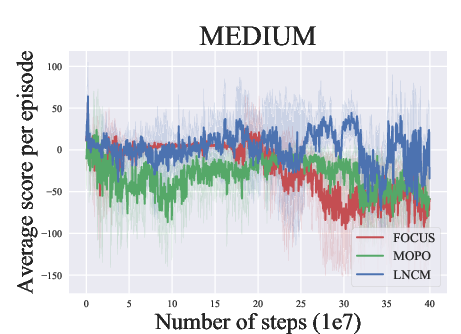
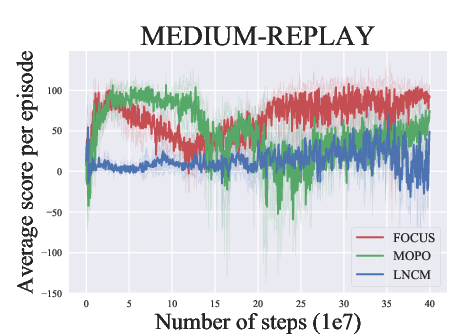
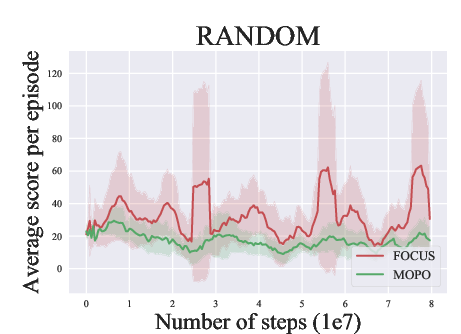
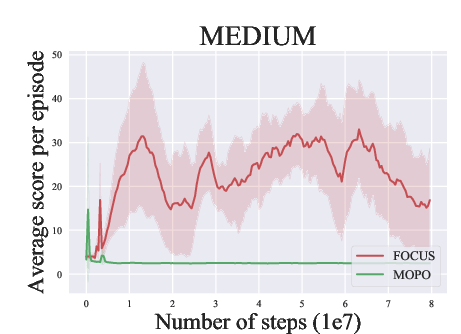
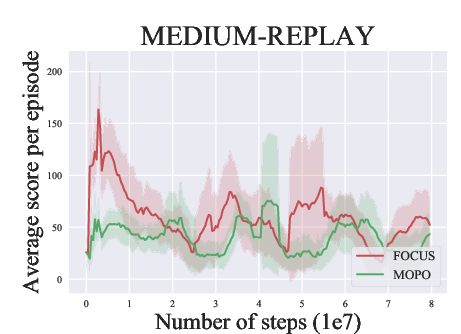
Abstract: Model-based methods have recently shown promising for offline reinforcement learning (RL), aiming to learn good policies from historical data without interacting with the environment. Previous model-based offline RL methods learn fully connected nets as world-models that map the states and actions to the next-step states. However, it is sensible that a world-model should adhere to the underlying causal effect such that it will support learning an effective policy generalizing well in unseen states. In this paper, We first provide theoretical results that causal world-models can outperform plain world-models for offline RL by incorporating the causal structure into the generalization error bound. We then propose a practical algorithm, oFfline mOdel-based reinforcement learning with CaUsal Structure (FOCUS), to illustrate the feasibility of learning and leveraging causal structure in offline RL. Experimental results on two benchmarks show that FOCUS reconstructs the underlying causal structure accurately and robustly. Consequently, it performs better than the plain model-based offline RL algorithms and other causal model-based RL algorithms.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of unresolved issues that future work could address to strengthen the paper’s theoretical foundations, algorithmic design, and empirical validation.
- Extend the theoretical results beyond the linear case to nonlinear dynamics and function classes (e.g., neural networks), and provide corresponding generalization and policy evaluation error bounds that match the model class used in FOCUS.
- Derive theory and bounds for the general (multi-dimensional) case rather than relying on 1D simplifications, and make the constants in the bounds interpretable and empirically measurable.
- Provide identifiability conditions under which the proposed causal discovery recovers the true graph from purely observational offline RL data; explicitly state and test assumptions such as causal sufficiency, faithfulness, stationarity, and absence of unobserved confounders.
- Quantify and propagate uncertainty in the learned causal structure to policy learning (e.g., via Bayesian posteriors over graphs, soft masks, or robust optimization), and analyze the impact of graph mis-specification on performance and safety.
- Specify and justify the procedure for selecting the KCI test significance threshold p*, including multiple-testing corrections (e.g., FDR control), Type I/II error trade-offs, and adaptive thresholding under varying sample sizes.
- Analyze the sample complexity and consistency of kernel-based conditional independence (KCI) tests under high-dimensional conditioning sets (conditioning on “all other variables at time t”), and propose dimensionality reduction or regularization strategies when KCI becomes unreliable.
- Evaluate scalability of the causal discovery step: characterize computational cost as a function of state/action dimensionality, number of tests, and dataset size; provide practical heuristics to reduce O(n2) testing and kernel matrix costs for large-scale offline RL.
- Assess robustness of causal discovery under mixed-policy datasets and selection bias; characterize how heterogeneity of behavior policies (and their support) affects CI tests and graph orientation, and propose corrections (e.g., inverse propensity weighting, front-door/back-door adjustments).
- Clarify how actions are treated in conditional variable selection (both at time t and t+1), and analyze whether the proposed “condition on t, not on t+1” principle remains valid when actions intervene on states, rewards, or other actions.
- Incorporate reward modeling and its causal structure explicitly; study spurious variables in the reward function and their effect on policy evaluation bounds and conservative offline RL objectives.
- Test the claimed invariance/generalization benefits of causal world-models under controlled out-of-distribution shifts and interventions (e.g., environment changes, policy changes, noise regimes), not just mixtures of offline datasets; report whether causal graphs maintain predictive invariance across domains.
- Measure and report the quantities appearing in the theory (e.g., spurious variable density R_spu and correlation strength λ_max) from data, and empirically correlate them with observed policy evaluation errors to validate the bound’s practical relevance.
- Provide head-to-head comparisons with additional offline MBRL baselines (e.g., COMBO, MOReL, MBOP, MBPO) and state-of-the-art model-free offline RL methods, to isolate the benefits of causal structure versus pessimism/uncertainty mechanisms.
- Compare causal discovery approaches beyond KCI/PC-style orientation (e.g., GES, NOTEARS, DirectLiNGAM, nonparametric additive noise models), and quantify accuracy/efficiency/robustness trade-offs across methods.
- Address partial observability and latent variables: extend FOCUS to POMDPs or incorporate latent causal discovery, and analyze how hidden confounders or unmeasured state components affect both structure learning and policy performance.
- Investigate multi-step and higher-order temporal dependencies (edges beyond t→t+1), including second-order dynamics and delayed effects; assess whether restricting edges to immediate next-step causes underfits real physics in MuJoCo-like tasks.
- Examine the interaction between causal masking and model capacity: quantify when masking reduces under/overfitting, and provide criteria or diagnostics to avoid removing necessary predictive inputs (false negatives in graph learning).
- Provide a principled treatment of sensor/observation frequency issues noted in MuJoCo (e.g., aliasing, time discretization); offer guidelines or preprocessing for time series that improve causal discovery reliability.
- Detail KCI hyperparameter choices (kernels, bandwidths), computational budgets, and implementation specifics; report sensitivity analyses to these settings and provide reproducible code and experiment seeds.
- Revisit fairness of the LNCM baseline adaptation to offline RL (or include more appropriate offline causal baselines), ensuring methodological alignment and avoiding confounds in comparative conclusions.
Collections
Sign up for free to add this paper to one or more collections.