- The paper introduces Time3D, an end-to-end framework that jointly learns monocular 3D object detection and tracking by integrating geometric and appearance features.
- It leverages transformer-based spatial-temporal attention mechanisms to aggregate features and enforce temporal-consistency for smooth trajectory predictions.
- The framework demonstrates leading performance on the nuScenes dataset with 21.4% AMOTA and 38 FPS, highlighting its efficacy for real-time autonomous driving.
Time3D: End-to-End Joint Monocular 3D Object Detection and Tracking for Autonomous Driving
The paper presents Time3D, a novel end-to-end framework designed for monocular 3D object detection and multi-object tracking in the context of autonomous driving. Utilizing a monocular video sequence, Time3D integrates geometric and appearance features to predict and output smooth 3D trajectories, bounding boxes, object categories, velocities, and motion attributes. This joint learning enables the transmission of uncertainties and error gradient backpropagation, enhancing stability and estimations in real-time settings.
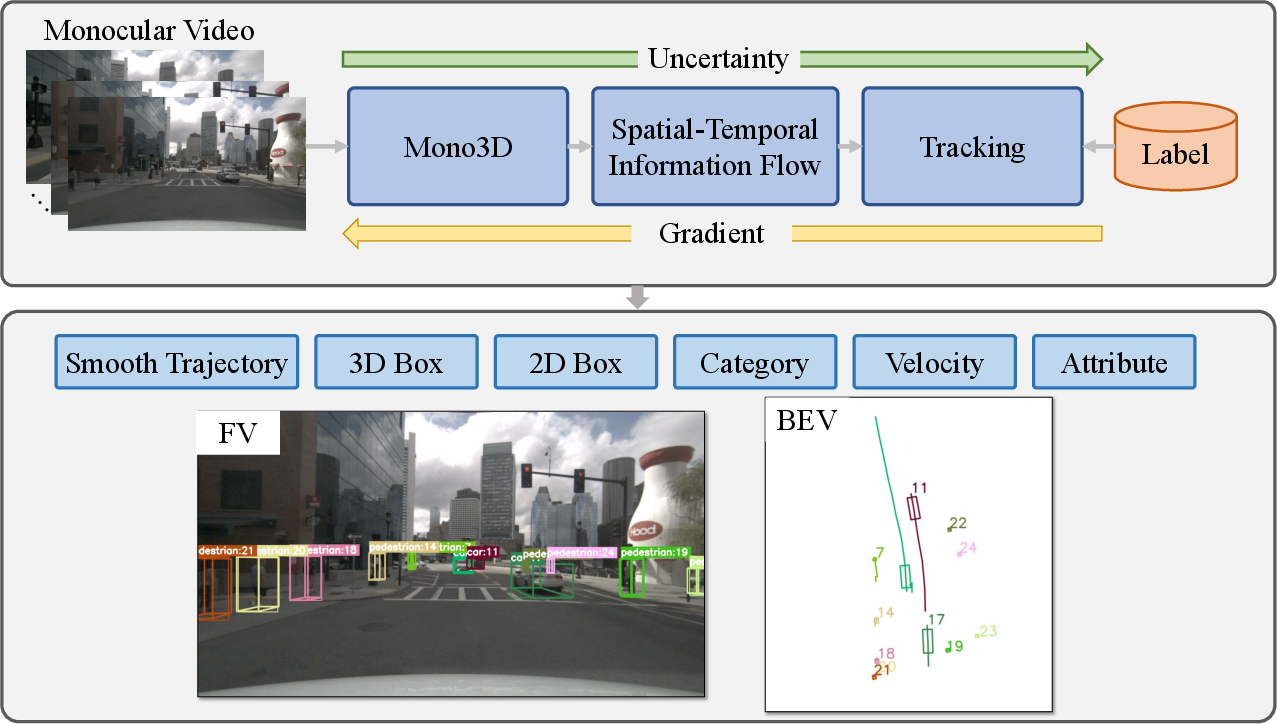
Figure 1: Illustration of the proposed Time3D framework showcasing joint learning for monocular 3D detection and tracking.
Introduction
Autonomous driving systems rely heavily on 3D object detection to perceive their environment accurately. Conventional solutions often separate detection and tracking, breaking the communication of error differentials between them which hinders performance. Time3D resolves these issues with a unified architecture that manages both processes simultaneously using monocular camera inputs. The absence of depth data in monocular cameras presents challenges in stable 3D target estimation; however, Time3D uniquely leverages spatial-temporal information flow that aggregates features using transformer mechanisms for robust trajectory predictions.
Methodology
Time3D employs a spatial-temporal information flow module to manage geometry and appearance features aggregated via attention mechanisms. This module uses self-attention for manipulating spatial data within frames, while cross-attention processes information across frames to estimate object trajectories with temporal consistency. Additionally, Time3D formulates temporal-consistency loss to ensure smooth trajectory predictions. This comprehensive approach achieves superior tracking and detection performance compared to contemporaries operating in similar settings.
The backbone of Time3D is an enhanced KM3D detector augmented with parallel identification processing (Re-ID), delivering accurate object features needed for reliable tracking. Time3D's association mechanism performs well due to the transformer architecture enabling complex feature interaction across time dimensions.
In competitive benchmarking on the nuScenes dataset, Time3D demonstrates leading performance metrics including 21.4% AMOTA and runs efficiently at 38 FPS. Its capability to generate reliable 3D trajectories from monocular data is particularly noteworthy, advancing real-time processing requirements crucial for autonomous driving applications. The framework’s end-to-end nature facilitates effective uncertainty handling, crucial for dynamic driving environments where predictability is needed for safe navigation.
Implications and Future Research Directions
The implications for autonomous driving technology are profound. Time3D’s integration of 3D detection and tracking enhances data transmission fidelity between these processes, improving prediction reliability under uncertain conditions. Future research may explore extending the framework with more sophisticated geometric and appearance cues, adapting to diverse and challenging driving scenarios. Expanding the transformer architecture to manage real-world complexities introduces promising avenues for research into unified systems within autonomous platforms.
Conclusion
Time3D represents a significant advancement towards practical monocular vision solutions in autonomous driving. Its methodical integration of detection and tracking within a shared framework establishes a precedent for high-performance real-time applications. As autonomous driving continues to evolve, frameworks like Time3D provide the foundational methodologies that can be leveraged to refine and enhance systems globally towards greater safety and efficiency in transportation networks.