- The paper demonstrates that using synthetic contexts via TeaBReaC significantly boosts language model performance, yielding up to 13 F1 point improvements on multi-step QA tasks.
- It leverages QDMR annotations to systematically generate and balance synthetic contexts, effectively minimizing reasoning shortcuts.
- Experimental results indicate that pretraining on TeaBReaC enhances robustness across in-distribution and complex question evaluations for various language models.
"Teaching Broad Reasoning Skills for Multi-Step QA by Generating Hard Contexts"
Introduction
The paper "Teaching Broad Reasoning Skills for Multi-Step QA by Generating Hard Contexts" (2205.12496) addresses the challenge of enhancing LLMs' capability in multi-step question answering (QA) tasks. Multi-step QA requires models to integrate various reasoning skills such as reading comprehension, numerical reasoning, and information synthesis. Existing datasets are limited in that they often allow models to exploit reasoning shortcuts, preventing them from developing the required reasoning skills. The paper proposes a method for generating synthetic contexts, referred to as TeaBReaC, to improve the robustness and performance of LLMs on multi-step reasoning tasks.
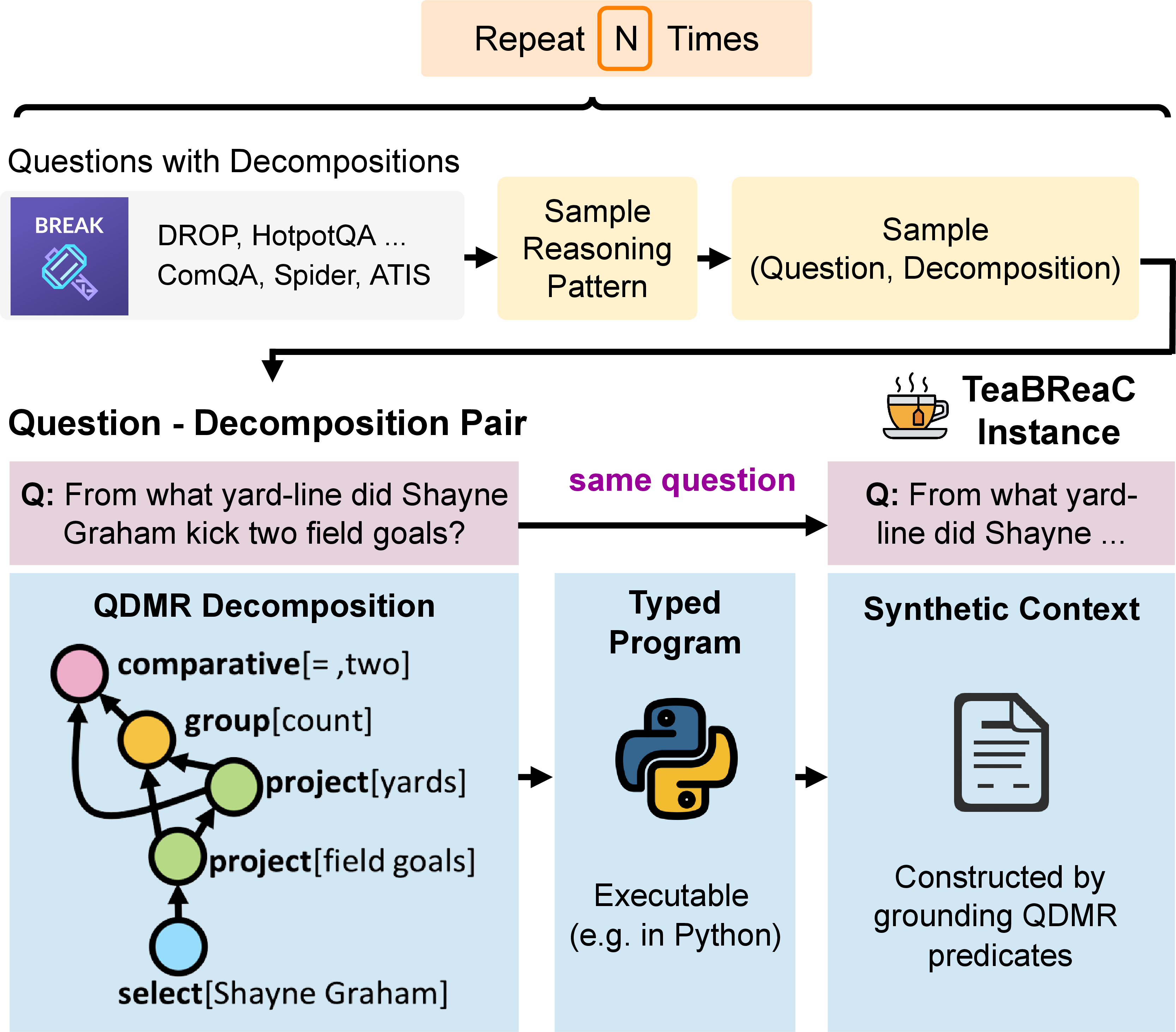
Figure 1: TeaBReaC images/teabreac.png Dataset Construction: We use widely available question decomposition annotations (QDMRs) for real questions from a broad range of datasets to carefully construct synthetic contexts such that answering the resulting images/teabreac.png question requires proper multi-step reasoning. These questions are further re-balanced to help teach a broad set of reasoning skills.
Methodology
The TeaBReaC dataset is constructed by leveraging Question Decomposition Meaning Representation (QDMR) annotations to systematically generate synthetic contexts for questions sourced from six diverse datasets. The construction process controls for reasoning shortcuts by balancing the distribution of reasoning patterns and ensuring that questions reflect a wide range of reasoning skills.
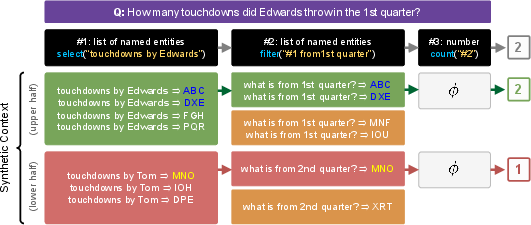
Figure 2: A simplified example of a QA instance in TeaBReaC, with a (simplified) real question from the DROP dataset and the synthetic context we construct for it using the question's 3-step decomposition. Statements in red, yellow, and green form the synthetic context. The instance satisfies desirable properties P1, P2, and P3, and thus helps robustly teach multi-step reasoning skills.
The process involves converting QDMRs into precise typed programs that define the steps needed to answer a question. This conversion enables the creation of synthetic contexts that models can execute to obtain answers while avoiding irrelevant reasoning paths. The synthetic contexts use grounded entities such that reasoning steps cannot be bypassed.
Experimental Setup
The effectiveness of TeaBReaC is assessed by pretraining LLMs on the dataset before fine-tuning them on target QA datasets. The research evaluates various LLMs, both plain (e.g., T5-Large) and numerate ones (e.g., NT5), to ascertain the performance and robustness gains from TeaBReaC pretraining.
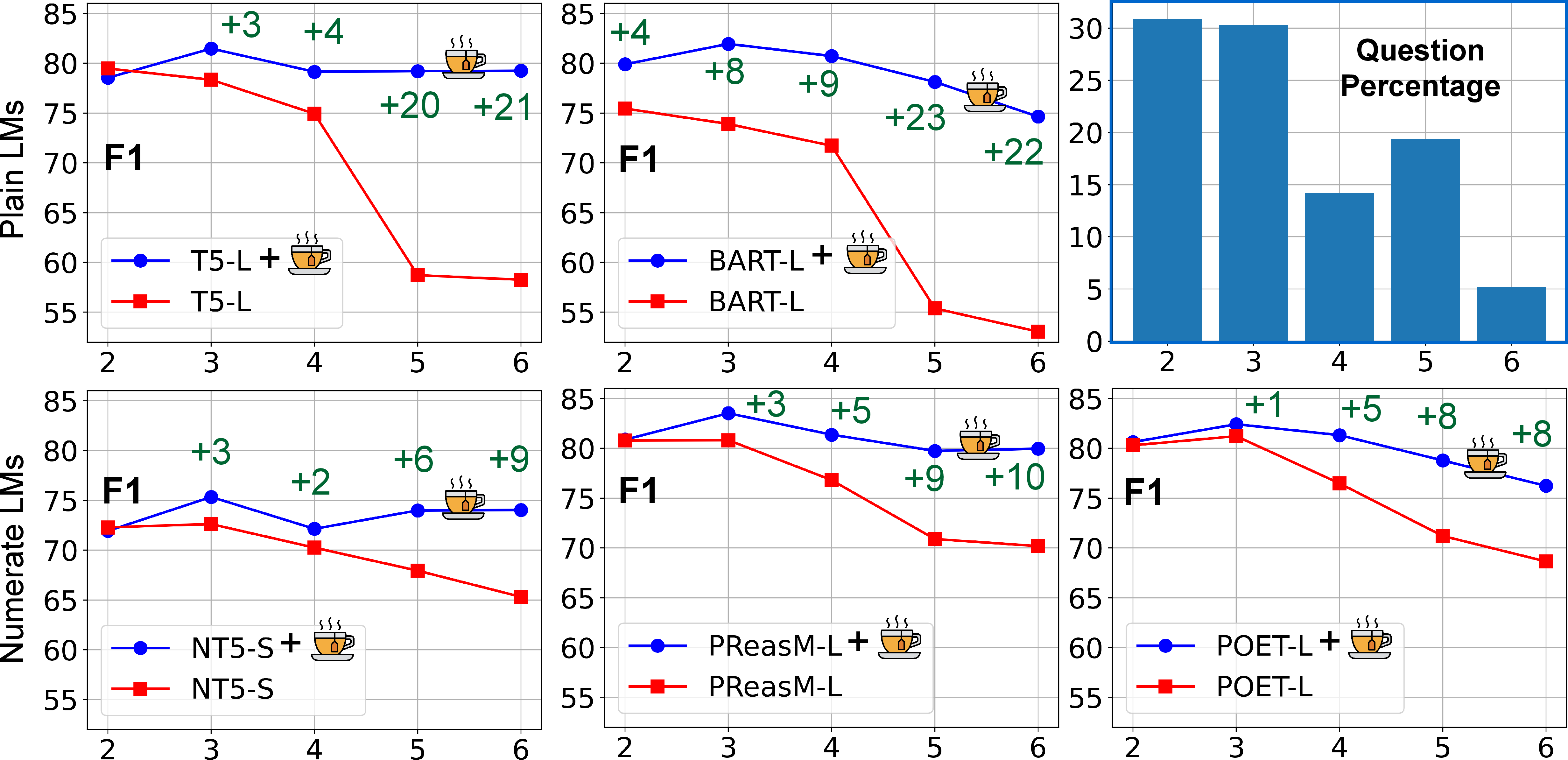
Figure 3: F1 scores for plain and numerate LMs with and without images/teabreac.png \xspace TeaBReaC pretraining on DROP across varying numbers of steps, as determined by our programs. TeaBReaC pretraining helps more on more complex questions. The effect is more prominent on plain LMs like T5-L than on numerate LMs like PReasM-L.
Results and Discussion
TeaBReaC pretraining significantly boosts the performance of LMs on multiple QA datasets, achieving up to 13 F1 point improvements (with up to 21 points on complex questions). These performance gains are observed across in-distribution evaluations and robustness tests, indicating that models pretrained on TeaBReaC learn more reliable multi-step reasoning skills.
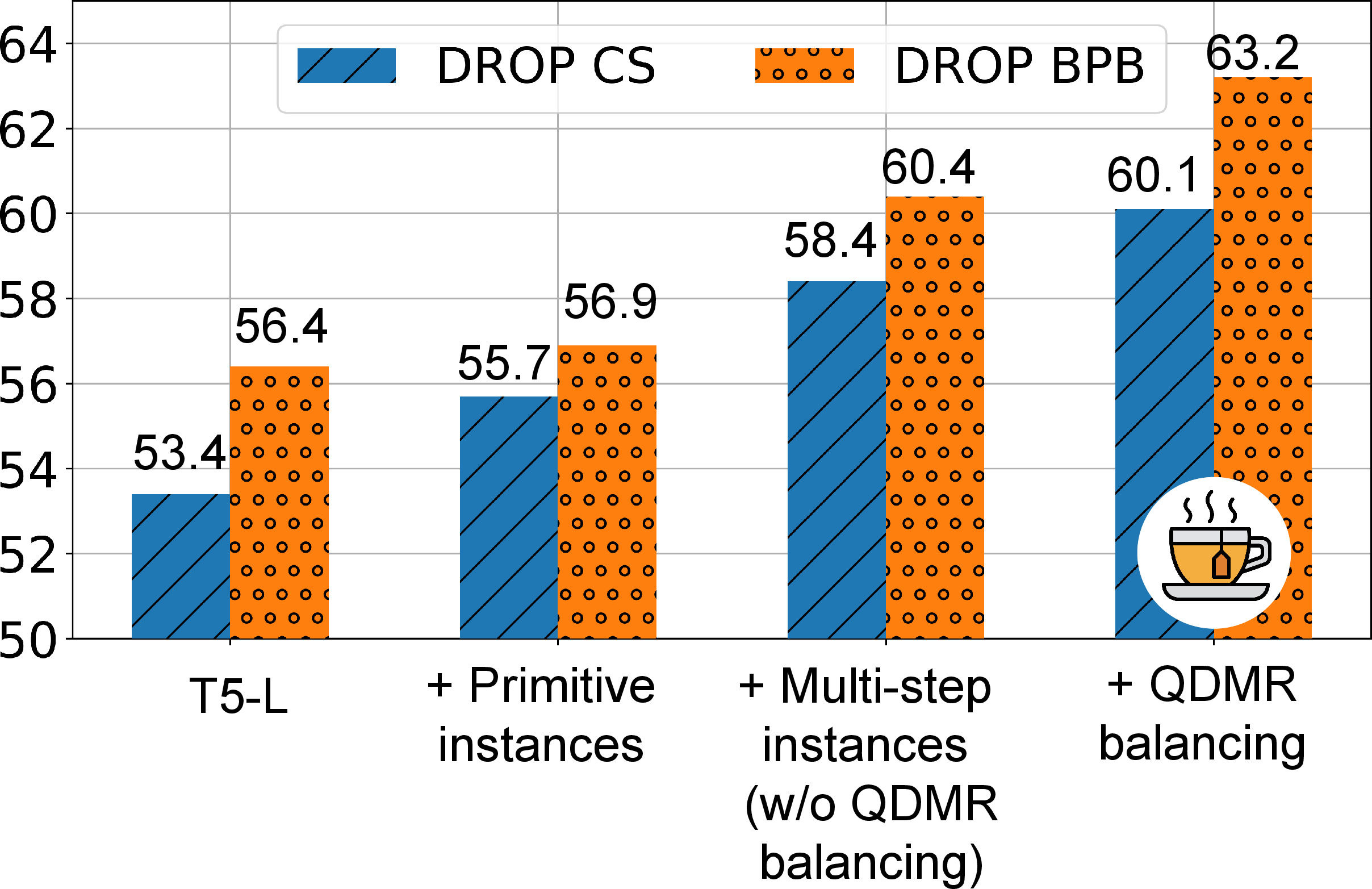
Figure 4: TeaBReaC Ablations: All aspects of TeaBReaC pretraining data contribute to the overall performance: (i) primitive QA instances (ii) multi-step QA instances (iii) balancing of QDMR distribution.
The dataset notably enhances performance on complex questions requiring multiple reasoning steps, which are underrepresented in natural datasets. The ablation study reveals that every component of the TeaBReaC design, including the construction of QA instances and the QDMR balancing, is crucial for achieving these improvements.
Conclusion
This research demonstrates that synthetic context generation is a powerful method for imparting robust multi-step reasoning skills to LLMs. By addressing the limitations of existing datasets and providing varied reasoning challenges, TeaBReaC represents a significant step forward in preparing models to handle complex QA tasks. The dataset's broad applicability offers numerous avenues for further research into teaching reasoning patterns and measuring reasoning robustness in LLMs.