- The paper introduces VLCDoC, a model using global cross-modal attention with InterMCA and IntraMSA modules for robust document classification.
- The model integrates vision and text features via a contrastive loss that enhances intra-class compactness and inter-class separability.
- Experimental results reveal up to 93.19% accuracy on diverse datasets, outperforming larger pre-trained methods with fewer training samples.
Vision-Language Contrastive Pre-Training for Cross-Modal Document Classification: Architecture and Analysis
Motivation and Background
Cross-modal document classification is challenged by significant heterogeneity in both visual and textual document properties. This includes high intra-class variability and low inter-class discrimination, frequent OCR failures on handwriting or artistic text, and the need for reasoning over global document structure rather than isolated, local word-level cues. Existing multimodal document methods typically rely on large-scale pre-training and primarily leverage local, word-level fusion through position encodings or bounding box coordinates. These approaches may fail to capture global document semantics, especially in domains with complex visual layouts or unreliable text extraction.
The VLCDoC model addresses these limitations by leveraging page-level contrastive pre-training over both vision and language modalities, introducing explicit intra- and inter-modality alignment mechanisms. The model is designed to operate with reduced pre-training data—a critical requirement for document AI tasks where labeled data availability is often limited—while maintaining broad generality and high performance across varying document types.
Model Architecture
VLCDoC is structured as an encoder-only transformer stack, with distinct branches for vision and textual feature extraction. Visual features are extracted using ViT-B/16, where document images are partitioned into 2D patches and encoded as fixed-dimensional tokens. Text extraction is performed via OCR (e.g., Tesseract), then tokenized and embedded with BERTBase. Both modalities are mapped to feature vectors of identical dimensionality, facilitating subsequent attention and fusion operations.
Central to VLCDoC are two specialized attention modules—Inter-Modality Cross Attention (InterMCA) and Intra-Modality Self Attention (IntraMSA)—which are stochastically stacked throughout the transformer layers:
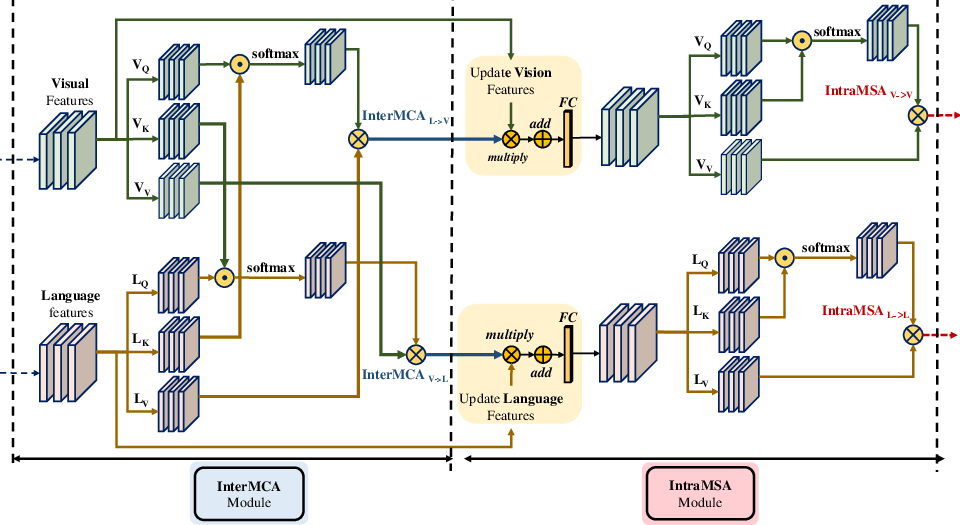
Figure 1: Illustration of the InterMCA and IntraMSA attention modules, enabling flexible feature fusion and transfer of attention between and within modalities for optimal representation learning.
- InterMCA projects queries from one modality onto keys of the other, integrating salient cross-modal features and transforming visual and textual cues into globally rich, joint embeddings.
- IntraMSA executes self-attention within each modality, leveraging cross-modally enhanced features from InterMCA and refining intra-modality semantic alignment via feature fusion and contextual weighting.
Both modules employ multi-headed attention, residual connections, and layer normalization. Vision and language features are projected into four sub-spaces and concatenated after attention aggregation.
Training Objective: Cross-Modal Contrastive Learning
The model is trained via a cross-modal contrastive loss (CrossCL) designed to simultaneously achieve intra-class compactness and inter-class separability, not only within each modality but also across modalities. This is operationalized by:
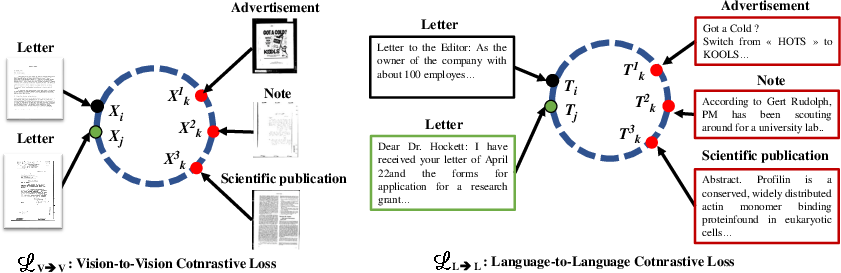

Figure 2: Intra-modality contrastive learning, aligning features from the same modality and class closer together in representation space.
- Contracting positive pairs (same class, same or different modalities) and contrasting negative pairs (different classes, within or across modalities) within the joint embedding space.
- Four loss components: intra-modal (vision-vision, language-language) and inter-modal (vision-language, language-vision) alignments, balanced by a λ hyperparameter and controlled via temperature scaling (τ).
A nonlinear MLP projection head and L2 normalization of features ensures effective representation mixing and distance-based discrimination for contrastive learning.
Fine-Tuning and Inference
After pre-training, VLCDoC supports both uni-modal and multi-modal fine-tuning: for downstream document classification, fully connected layers atop the pre-trained encoders are trained, either individually (for vision or language cues) or jointly (for fused multimodal representations).
Experimental Evaluation
Ablation Analysis
A suite of ablation studies on the Tobacco dataset examines the impact of InterMCA and IntraMSA modules, as well as the efficacy of contrastive loss:
- Removing both attention mechanisms leads to a substantial drop in classification accuracy (down to ~85.7% for vision-only).
- Enabling both modules elevates accuracy to 90.94% (vision-only) and 90.62% (language-only), confirming the necessity of cross-modal and intra-modal attention flows.
- CrossCL significantly outperforms standard supervised contrastive learning, reinforcing the benefit of explicit cross-modal contrastive alignment.
T-SNE visualization further validates these findings; clustering is tighter and more discriminative when both attention modules are active.
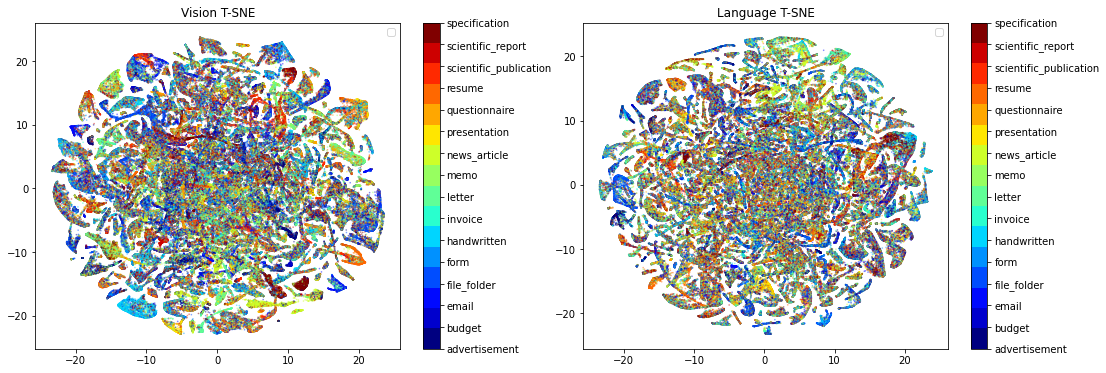
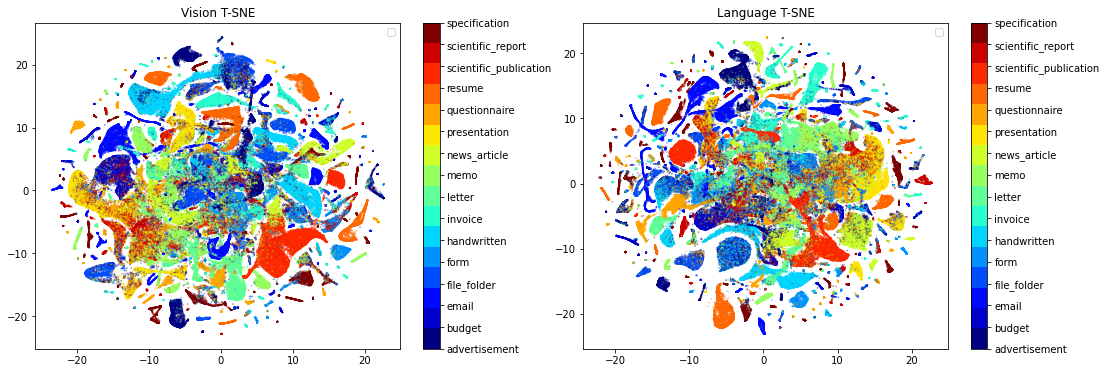
Figure 3: T-SNE demonstrates poor separation of classes without InterMCA/IntraMSA, indicating suboptimal joint embedding quality.
VLCDoC was benchmarked in cross-dataset transfer scenarios (pre-training on one dataset, fine-tuning and testing on another), consistently outperforming comparable architectures and demonstrating strong domain generality, even when the document categories differ substantially across datasets.
SOTA Comparison
On the RVL-CDIP benchmark (using only 320k training samples), VLCDoC achieved:
- 92.64% accuracy (vision-only modality)
- 91.37% accuracy (language-only modality)
- 93.19% accuracy (vision + language fusion)
This matches or exceeds several prior uni- and multi-modal approaches, and operates competitively versus layout-enriched models (e.g., LayoutLM/DocFormer), many of which use vastly larger pre-training corpora (up to 11M documents). The results support the claim that high-level global cross-modal attention, enabled by carefully structured transformer modules and contrastive objectives, can mitigate the reduced data regime typical of real-world document AI tasks.
Implementation Considerations and Resource Requirements
VLCDoC is implemented using Tensorflow, exploiting pre-trained weights of ViT and BERT. Training requires moderate resources (4 × RTX 2080Ti GPUs, 12GB each), with input images resized to 224×224 and batch sizes set to 64. Pre-training is run for 100 epochs, fine-tuning for 50 epochs, relying on AdamW and Adam optimizers. Attention modules are stacked twice, with 4 attention heads per module. No data augmentation or OCR post-processing is performed in the reported experiments.
Practical and Theoretical Implications
VLCDoC demonstrates that page-level, contrastively aligned vision-language representation learning with explicit cross-modal attention mechanisms substantively improves performance in document classification, even with far less training data compared to conventional word-level masking approaches. This challenges the prevailing view of the necessity for massive pre-training corpora and position-encoded word-level fusion, particularly for documents with complex or unreliable text.
The explicit modeling of intra- and inter-modality relations via transformer attention constructs is readily extensible, offering a basis for incorporating additional modalities (e.g., document layout information) in future models. Moreover, strong numerical results indicate its suitability for domain-agnostic document representation, with robustness against heterogeneous and unseen document categories.
Conclusion
VLCDoC presents a comprehensive cross-modal contrastive pre-training approach that advances document classification through transformer-based architecture and modular attention mechanisms. By learning intra- and inter-modality relationships and leveraging effective contrastive objectives, it achieves high accuracy and generality with modest training data and computational requirements. Further extension to layout modality and advanced pre-text task strategies are promising directions to enhance multimodal document understanding applications.