- The paper introduces SKILL, a novel pre-training method that directly infuses structured knowledge from graphs into LLMs, enhancing closed-book QA accuracy.
- It employs salient span masking and a dual corpus of knowledge graph triples and synthetic sentences to blend structured and unstructured learning effectively.
- Experimental results show significant improvements in exact match scores across diverse QA benchmarks, particularly for larger models and varied KG scales.
Structured Knowledge Infusion for LLMs
This essay provides an in-depth review of the paper "SKILL: Structured Knowledge Infusion for LLMs," which proposes enhancing LLMs' capacity for handling structured knowledge by leveraging knowledge graph triples directly. The method innovatively circumvents traditional reliance on natural language representations in favor of direct, structured data, resulting in marked performance improvements on closed-book QA tasks.
Introduction to SKILL
LLMs typically excel when trained on vast unstructured text corpora. However, their ability to internalize structured knowledge directly from knowledge graphs remains underexplored. This paper tackles this gap by proposing a novel pre-training method named SKILL (Structured Knowledge Infusion for LLMs), which infuses knowledge directly from structured knowledge graph representations like Wikidata KG without requiring alignment with natural language corpora.
Methodology
The methodology involves training T5 models on factual triples extracted from knowledge graphs. The training process includes salient span masking, which facilitates unsupervised learning by masking key elements within triples and their equivalent in KELM-generated sentences. This enables models to integrate structured knowledge efficiently while maintaining competence in natural language understanding.
Training Corpus
Two distinct knowledge representations are used:
- Wikidata KG: Structured triples form the exclusive training data.
- KELM (Knowledge-Enhanced LLM) corpus: Synthetic natural language sentences derived from these triples.
The corpus is augmented with natural language from the C4 dataset to ensure comprehensive language understanding capabilities is retained.
Training Method
Models undergo SKILL pre-training on datasets combining knowledge representations and are further evaluated by fine-tuning on QA benchmarks like FreebaseQA and WikiHop. The pre-training emphasizes salient span masking of either the subject or object entity within a triple.
Experiments and Results
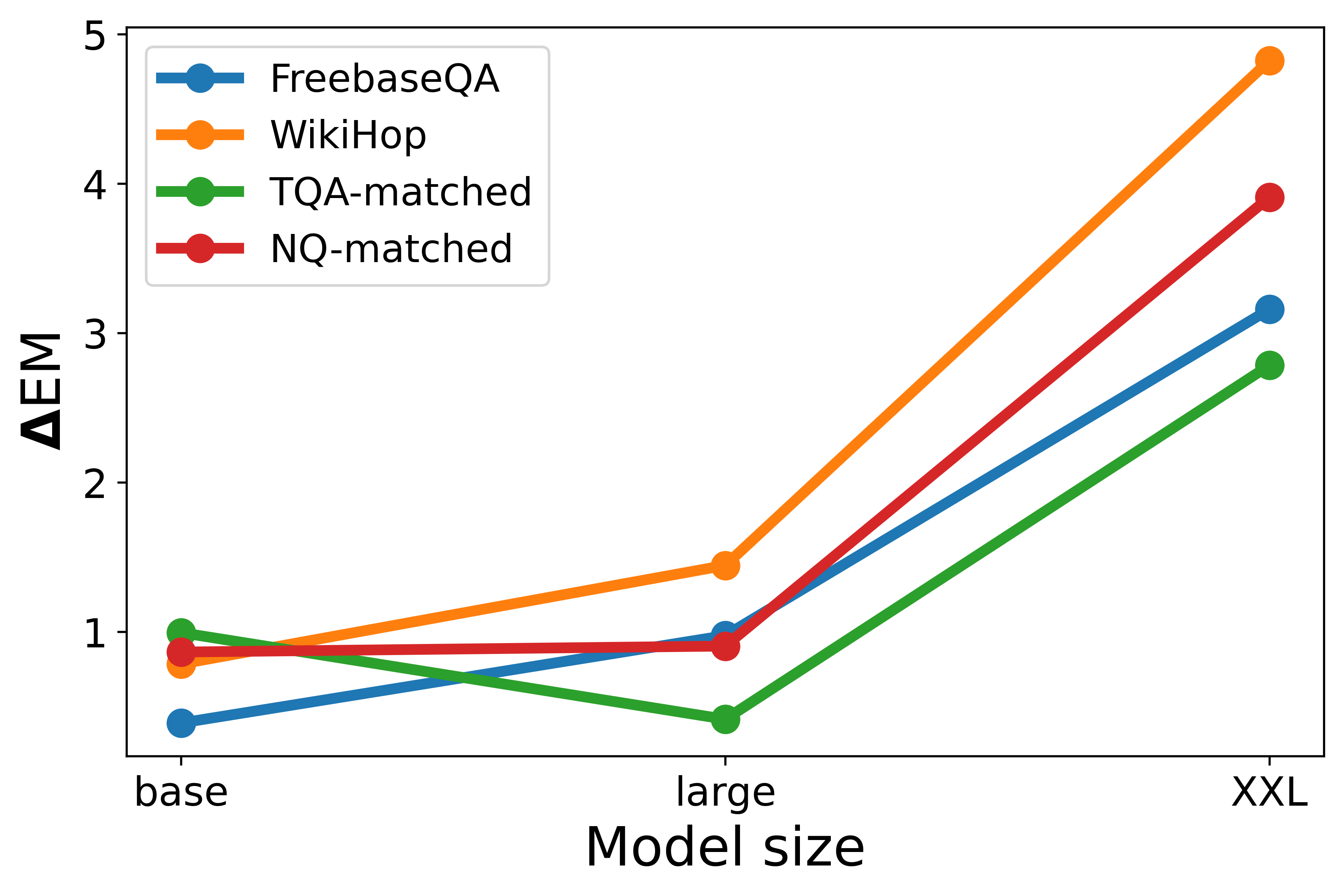
SKILL is evaluated by its performance on four standard closed-book QA tasks. Results demonstrate that models trained with SKILL outperform T5 baselines, particularly on datasets closely aligned with knowledge graphs.
Application on Smaller Knowledge Graphs
Training with WikiMovies KG triples yields substantial benefits in MetaQA tasks, particularly improving EM scores for tasks involving 1-hop questions. The ability of SKILL-trained models to substantially enhance results on smaller-scale KGs showcases SKILL's adaptability to varying scales of structured knowledge.
Contrasting with Traditional Methods
Unlike retrieval-augmented models, SKILL embeds knowledge directly into the model's parameters, thereby avoiding additional inference costs or complex alignment procedures. This approach is distinct in embedding structured knowledge directly without translation or mapping to natural language, as seen in models like KnowBert or KG-FiD.
Implications and Future Directions
SKILL opens new avenues for integrating structured knowledge efficiently into LLMs, making them suitable for applications involving industrial-scale KGs. Future research could explore encoding graph structure information more explicitly, which may be crucial for improving multi-hop reasoning capabilities. Additionally, integrating graph-based insights could further enhance model reasoning ability without significant escalation in computational overhead.
Conclusion
The paper introduces a significant advancement in the field of knowledge fusion in LLMs, providing a straightforward, effective method to integrate structured knowledge from knowledge graphs consistently. This approach shows promise in enhancing the factual accuracy and capability of LLMs, particularly in closed-domain Q&A setups, without the dependency on natural language conversion, thereby paving the way for future exploration in scalable, knowledge-driven language understanding.