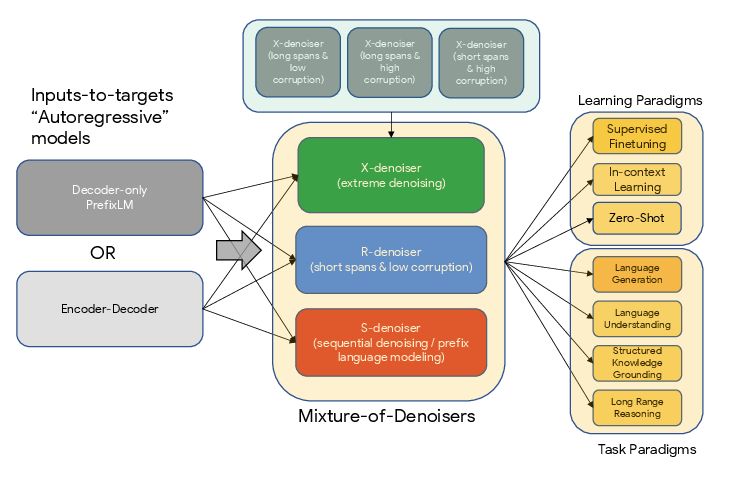
- The paper introduces a novel Mixture-of-Denoisers (MoD) framework that unifies diverse pre-training paradigms for language models.
- It presents a mode switching mechanism that dynamically aligns pre-training objectives with downstream tasks to enhance performance.
- Experiments show that scaling UL2 to 20B parameters yields state-of-the-art results on over 50 supervised and few-shot NLP tasks.
UL2: Unifying Language Learning Paradigms
The paper "UL2: Unifying Language Learning Paradigms" (2205.05131) introduces a novel pre-training framework designed to create universally effective LMs applicable across diverse datasets and setups. It challenges the conventional task-dependent approach to pre-trained LM selection by presenting a unified perspective on self-supervision in NLP. The core innovation lies in the Mixture-of-Denoisers (MoD) pre-training objective, which combines various denoising paradigms, and the concept of mode switching, where downstream fine-tuning is associated with specific pre-training schemes. The paper demonstrates state-of-the-art (SOTA) performance on a wide range of NLP tasks by scaling the model to 20B parameters.
Key Concepts and Contributions
This paper makes several key contributions:
- Disentangling Architectures and Objectives: The paper emphasizes the importance of distinguishing between architectural choices (e.g., encoder-decoder vs. decoder-only) and pre-training objectives, arguing that the latter has a more significant impact on model performance.
- Mixture-of-Denoisers (MoD): The paper introduces MoD, a pre-training objective that combines diverse denoising paradigms, including R-denoising (regular span corruption), S-denoising (sequential denoising), and X-denoising (extreme denoising). The MoD approach enables the model to learn from different contextual conditioning methods, improving its generalization ability.
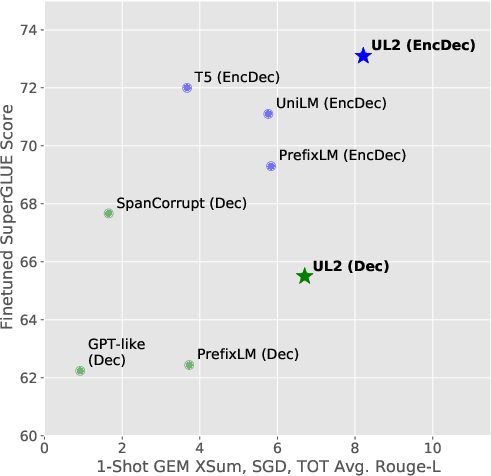
Figure 1: In both decoder-only and encoder-decoder setups, UL2 strikes a significantly improved balance in performance between fine-tuned discriminative tasks and prompt-based 1-shot open-ended text generation than previous methods. Note: Dec and EncDec are compute matched but EncDec models have double the parameters.
- Mode Switching: The paper proposes mode switching, a mechanism that associates pre-training tasks with dedicated sentinel tokens, allowing the model to dynamically switch between different pre-training schemes during downstream fine-tuning.
- Architecture-Agnostic Framework: UL2 is designed to be architecture-agnostic, supporting both encoder-decoder and decoder-only models. The choice of architecture is framed as an efficiency trade-off.
- SOTA Performance: The paper demonstrates SOTA performance on 50+ supervised NLP tasks, including language generation, language understanding, text classification, question answering, and commonsense reasoning, by scaling the UL2 model to 20B parameters. The model also achieves strong results in zero-shot and few-shot learning scenarios, outperforming GPT-3 (175B) on zero-shot SuperGLUE.
Mixture of Denoisers (MoD)
The UL2 framework hinges on the Mixture-of-Denoisers (MoD) pre-training objective. MoD blends several denoising objectives, each designed to impart distinct capabilities to the model. The main paradigms include:
The final objective is a mixture of 7 denoisers, configured as follows:
- R-Denoiser: (μ=3,r=0.15,n)∪(μ=8,r=0.15,n)
- S-Denoiser: (μ=4L,r=0.25,1)
- X-Denoiser: (μ=3,r=0.5,n)∪(μ=8,r=0.5,n)∪(μ=64,r=0.15,n)∪(μ=64,r=0.5,n)
Where μ is the mean span length, r is the corruption rate, and n is the number of corrupted spans. The mixing of these denoisers is crucial, as some denoiser types perform poorly in isolation. For example, the original T5 paper explored a 50% corruption rate (X-denoising) and found it ineffective.
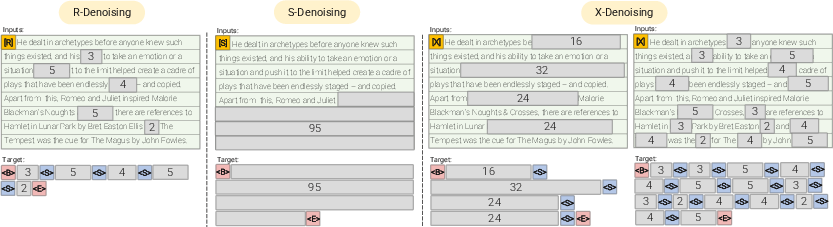
Figure 3: Mixture of denoisers for training UL2. Greyed out rectangles are masked tokens that are shifted to `targets' for prediction.
Mode Switching
Mode switching is a technique that allows the model to adapt its behavior based on the downstream task. During pre-training, the model is fed a paradigm token ([R], [S], [X]) that indicates the denoising mode. This helps the model learn to associate specific modes with different types of tasks. For fine-tuning and few-shot learning, a paradigm token is also added to trigger the model to operate in a suitable mode. This effectively binds downstream behavior to the pre-training modes.
Experimental Results
The paper presents extensive ablative experiments and scaling studies to evaluate the effectiveness of the UL2 framework. Key findings include:
- UL2 consistently outperforms T5-like and GPT-like models across a wide range of supervised and few-shot tasks.
- Mixing pre-training objectives is generally helpful.
- X-denoising is complementarily effective but does not suffice as a standalone objective.
- Small amounts of S-denoisers are preferred in the mixture.
- Mode switching has a substantial impact on model performance, with the right prompt leading to significant gains.
- Scaling the model size and pre-training data further improves performance.
- UL2 20B achieves SOTA performance on 50+ NLP tasks.
- UL2 20B demonstrates strong chain-of-thought prompting capabilities, enabling multi-step reasoning on arithmetic and commonsense tasks.
Implications and Future Directions
The UL2 framework has significant implications for the development of general-purpose LLMs. By unifying different learning paradigms and introducing mode switching, UL2 achieves SOTA performance across a wide range of NLP tasks, reducing the need for task-specific model design. The architecture-agnostic nature of UL2 also allows for flexible deployment across different hardware platforms.
Future research directions include:
- Scaling UL2 to even larger model sizes and datasets.
- Exploring different combinations of denoising objectives and mode switching strategies.
- Investigating the effectiveness of UL2 in other domains, such as computer vision and reinforcement learning.
- Developing more efficient training and inference techniques for UL2 models.
Conclusion
The paper "UL2: Unifying Language Learning Paradigms" (2205.05131) presents a novel and effective framework for pre-training universally applicable LLMs. The Mixture-of-Denoisers (MoD) pre-training objective and mode switching mechanism enable UL2 to achieve SOTA performance across a wide range of NLP tasks. The results suggest that UL2 is a promising approach for building general-purpose AI systems that can seamlessly adapt to diverse tasks and environments.