- The paper presents a tokenwise contrastive pretraining method that aligns speech and text (BERT) embeddings at the token level.
- It employs a cross-modal attention mechanism with a pyramidal BiLSTM to achieve fine-grained alignment, improving SLU performance.
- Evaluations on SNIPS and FSC datasets show enhanced accuracy—up to 83.07%—with a compact 48M parameter design suitable for on-device deployment.
Tokenwise Contrastive Pretraining for End-to-End Speech-to-Intent Systems
Introduction
The paper "Tokenwise Contrastive Pretraining for Finer Speech-to-BERT Alignment in End-to-End Speech-to-Intent Systems" (2204.05188) addresses the challenges in traditional spoken language understanding (SLU) systems that use automatic speech recognition (ASR) followed by natural language understanding (NLU). These cascaded systems are prone to substantial error propagation from ASR to NLU, and they suffer from inefficiencies due to the large model sizes necessitated by combining state-of-the-art ASR and NLU components. Recent trends favor end-to-end (E2E) SLU systems that directly process speech to extract semantic intents, bypassing ASR entirely. This work enhances the pretraining of speech encoders for E2E SLU using a tokenwise contrastive loss to align speech representations finely with BERT-based text embeddings.
Proposed Methodology
The core innovation of this paper is a novel cross-modal attention mechanism that facilitates token-by-token alignment between speech and BERT embeddings, using a contrastive loss function.
The speech encoder uses 80-dimensional log-Mel features from speech inputs, processed by a 9-layer pyramidal Bidirectional LSTM (BiLSTM) with a self-attention layer. The encoding undergoes cross-modal attention, where non-contextual word embeddings are converted into contextual embeddings influenced by corresponding speech signals. This alignment process is depicted in the model overview (Figure 1).
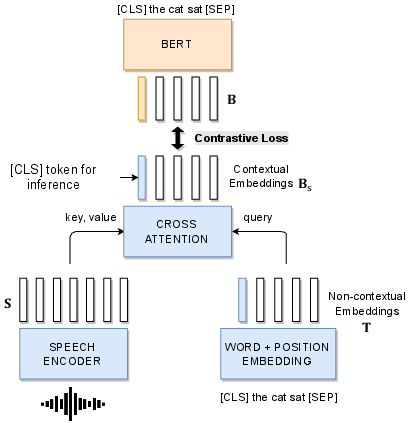
Figure 1: Model overview. During pretraining, the cross-attention mechanism yields contextual embeddings for the all input tokens using corresponding speech. During fine-tuning for downstream S2I, when only speech is available, only the [CLS] token is required.
The tokenwise contrastive loss optimizes the alignment by minimizing distance between the same tokens from speech and BERT modalities, improving cross-modal semantic representation. Pretraining is conducted using Librispeech data, followed by fine-tuning on downstream SLU tasks without in-domain transcripts, employing SpecAugment for data augmentation.
Results
The proposed model was tested on SNIPS-Smartlights and Fluent Speech Commands (FSC) datasets, outperforming existing methods in terms of accuracy. Tokenwise contrastive pretraining demonstrated substantial improvements on the SNIPS dataset, particularly for far-field speech, achieving up to 83.07% accuracy when combined with SpecAugment, which highlights its robustness to noisy settings.
Attention heatmaps validated the cross-modal attention's ability to learn alignment structures (Figure 2), suggesting the model effectively captures token-level dependencies across modalities.
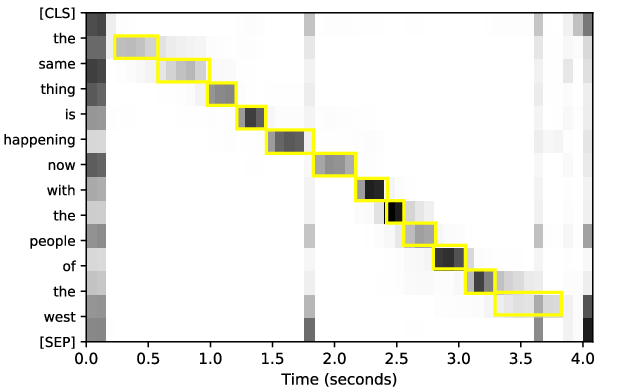
Figure 2: Attention heatmap of the cross-modal attention layer. The yellow boxes represent the actual alignment of the tokens with the speech. Cross-modal attention is implicitly learning alignment structures.
Additionally, the model is compact with just 48 million parameters, suitable for on-device deployment, offering a practical advantage over larger transformer-based architectures.
Discussion
This study contributes significantly to E2E SLU by demonstrating that finer alignment at the token level can enhance semantic understanding without reliance on large datasets or in-domain adaptation. The demonstrated performance improvements and model efficiency suggest potential deployment on resource-constrained devices.
While the results are promising, further exploration into entity extraction and slot-filling capabilities using tokenwise contrastive pretrained models would solidify its applicability in broader SLU tasks.
Conclusion
The paper presents a robust approach to overcoming traditional SLU limitations through refined cross-modal embedding alignment using tokenwise contrastive loss. The technique enhances speech-to-intent recognition accuracy, offering new directions for SLU research with practical implications for real-world voice assistant deployments. Future work should explore extending this framework to more diverse SLU applications, enhancing its versatility and generalization capabilities.

