- The paper introduces an end-to-end learning framework that surpasses traditional 3DMM methods by leveraging large-scale augmented RGB-D data for enhanced 3D face reconstruction.
- The methodology employs multiview simulation, shape transformation, and a many-to-one hourglass network to precisely capture personalized facial details while reducing reconstruction errors.
- The experiments demonstrate significant improvements in accuracy with reduced Normalized Mean Error and Densely Aligned Chamfer Error, underscoring the method’s superior performance.
Summary of "Beyond 3DMM: Learning to Capture High-fidelity 3D Face Shape"
This paper proposes an advanced framework to address the shortcomings of 3D Morphable Model (3DMM) fitting in accurately capturing high-fidelity 3D face shapes. The limitations in 3DMM fitting arise due to insufficient data, unreliable training strategies, and limited representation power, which result in degraded reconstructions. The proposed method introduces a novel end-to-end learning approach that enhances the 3D reconstruction process in terms of visual verisimilitude and personalized shape reconstruction.
Data Construction and Augmentation
To mitigate data scarcity, the paper utilizes single-view RGB-D images to construct large-scale 3D data, leveraging the accessibility provided by devices like handheld depth cameras (e.g., iPhone X). The registration of RGB-D images employs two substantial augmentation strategies: multiview simulation and shape transformation. These enhancements produce a substantial 3D dataset termed Fine-Grained 3D face (FG3D), bolstering the training of neural networks on high-fidelity 3D face reconstruction.
RGB-D Registration
The registration process engages the Iterative Closest Point (ICP) method with additional constraints, including edge landmarks and contour curve fitting, ensuring semantic consistency across registrations.
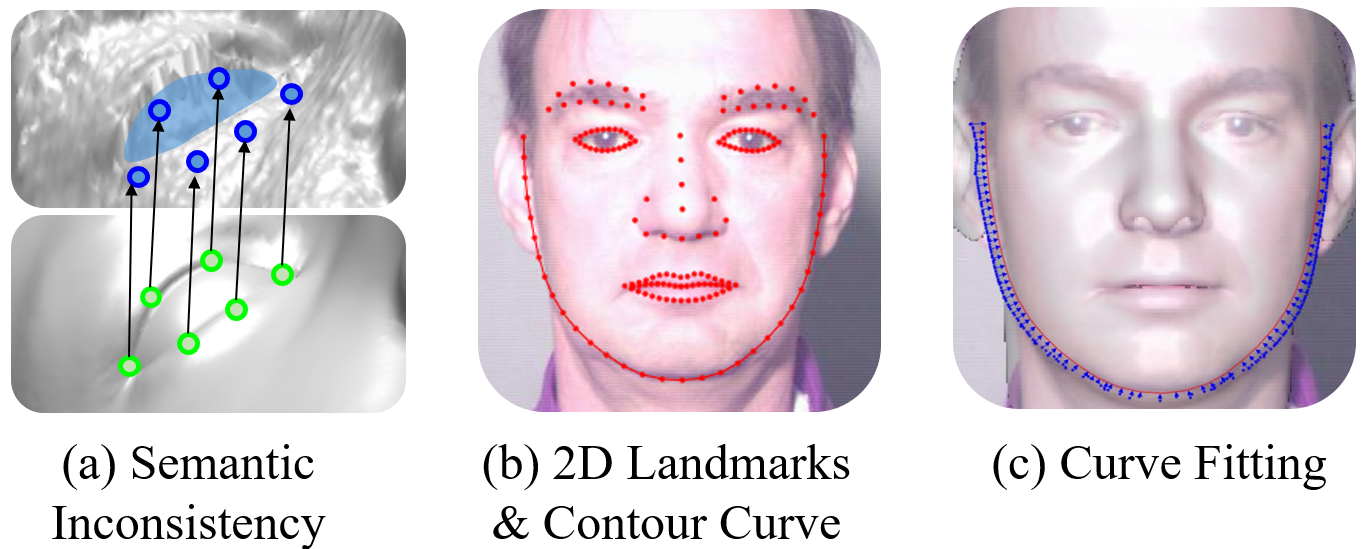
Figure 1: RGB-D registration demonstrating the alignment of 3D models using semantic features and facial landmarks.
Full-view Augmentation
The augmentation approach completes depth channels on RGB-D images, fixes artifacts with an advanced rotate-and-render strategy, and employs the Phong illumination model for refinement.
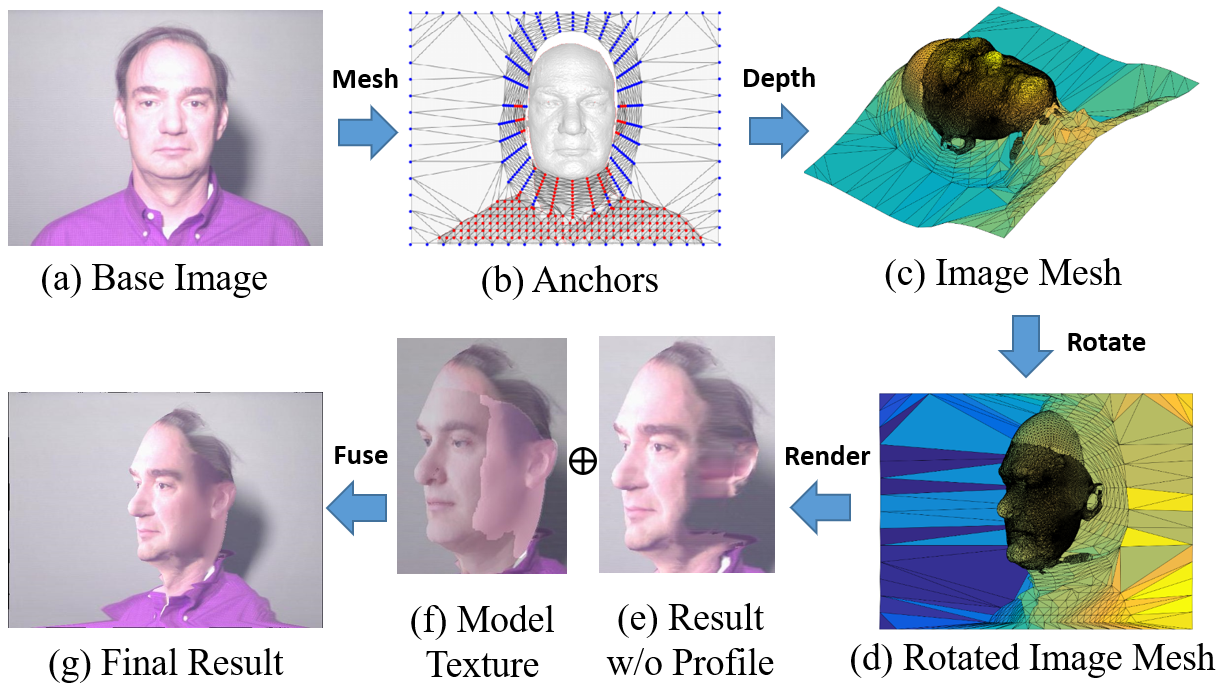
Figure 2: Full-view augmentation process providing depth channel completion and enhancing view variation.
Shape Transformation
This innovative augmentation method fuses facial features from various identities, enabling substantial shape variation and improving model robustness.
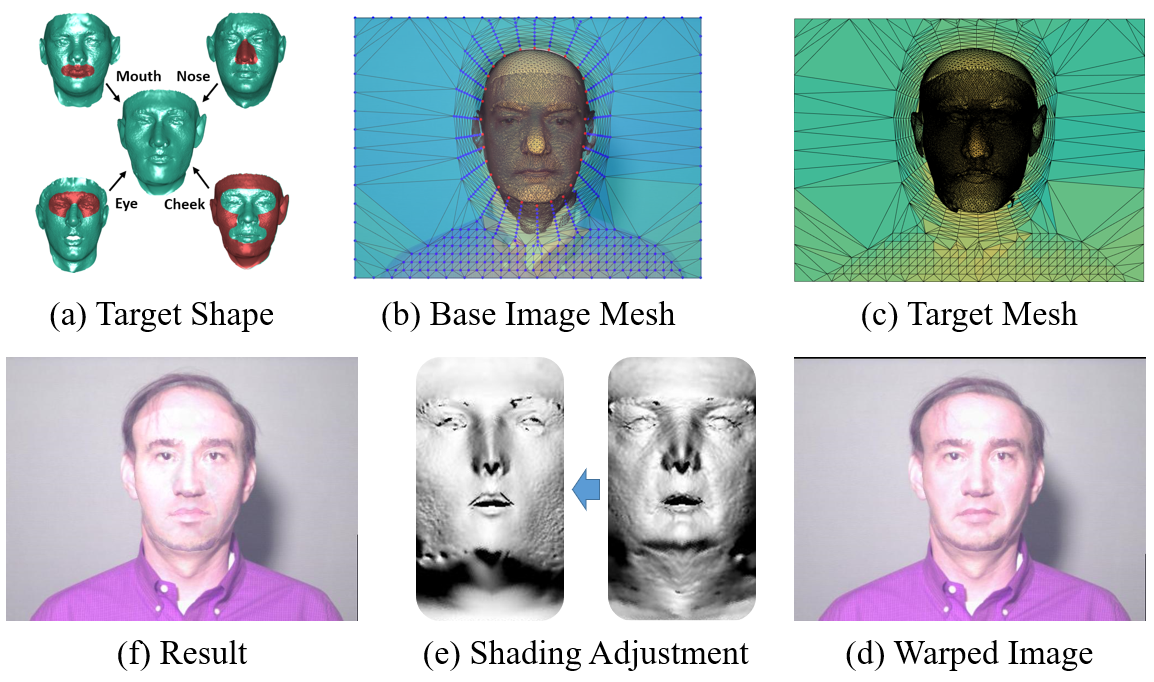
Figure 3: Shape transformation illustrating the integration of diverse facial features and adjustment of shading.
Virtual Multiview Network
The network architecture encompasses the Virtual Multiview Network (VMN) concept, which simulates multiview input using constant calibrated views to capture personalized shape effectively while preserving the geometry and external features of input images. The network has three critical properties: normalization, preservation of image detail, and concentrated receptive field alignment.
Multiview Simulation
The simulation renders several constant poses to normalize pose variations effectively, providing comprehensive visual input to the network.
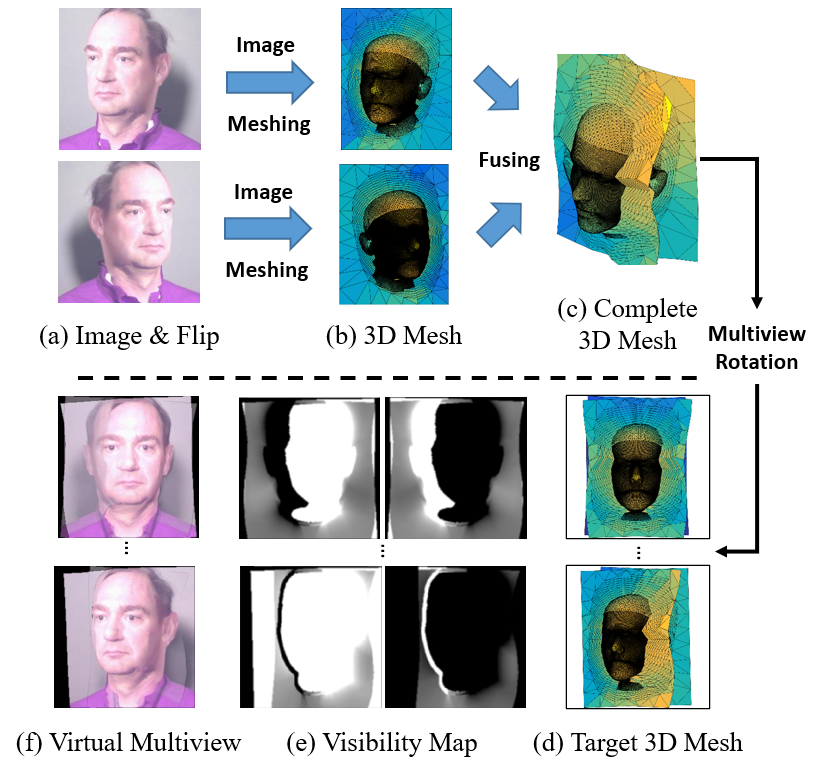
Figure 4: Multiview simulation process outlining the generation of calibrated poses.
Many-to-one Hourglass Network
A novel many-to-one hourglass network fuses multiview features into a unified output, honing in on personalized shape representation via intermediate feature alignment.
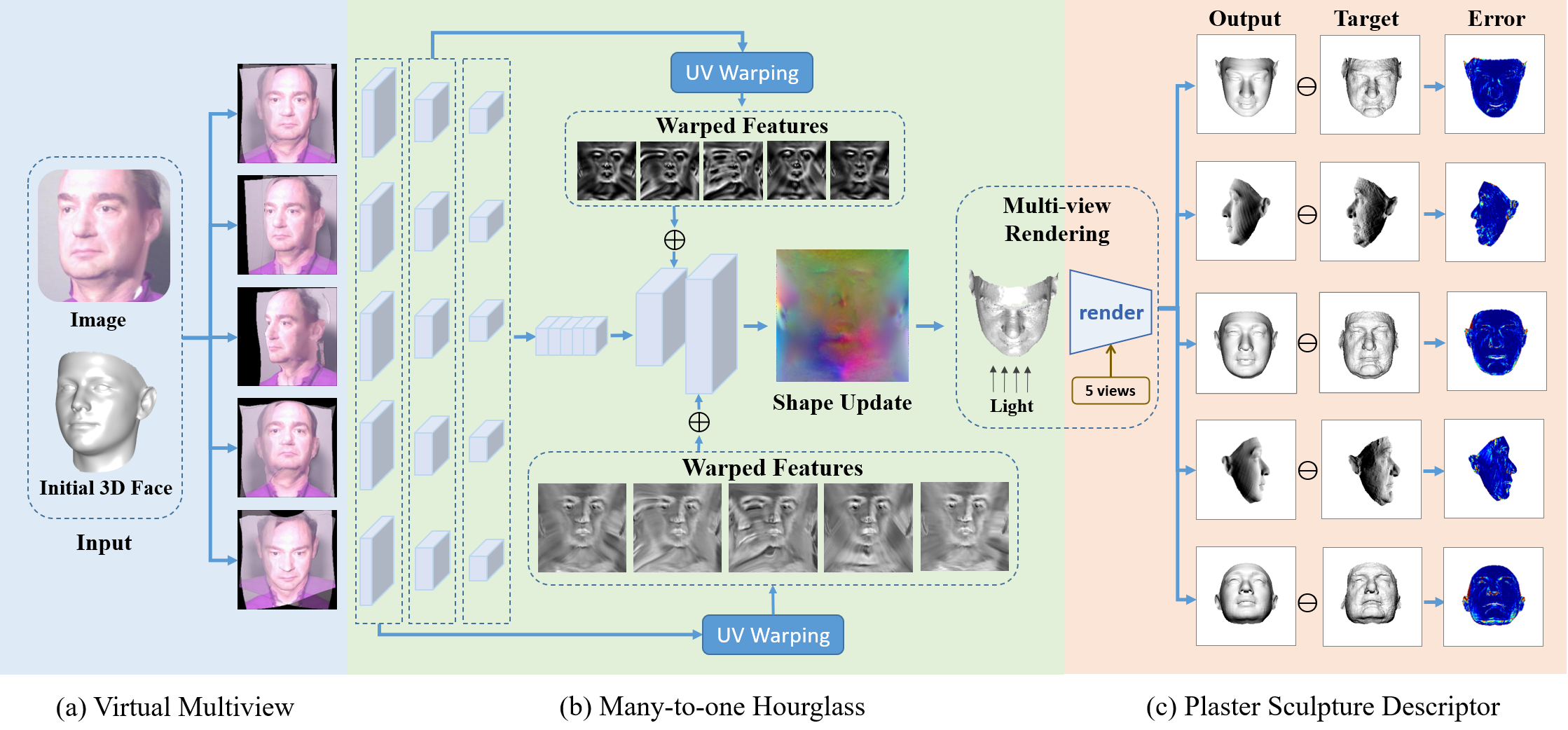
Figure 5: High-Fidelity Reconstruction Network overview depicting feature fusion within a multiview hourglass network.
Loss Function
The loss function pivots on visual recognition enhancements and includes the Plaster Sculpture Descriptor (PSD) modeling visual effects and the Visual-Guided Distance (VGD) loss, which mitigates deficiencies within PSD by focusing explicitly on visual discriminative regions.
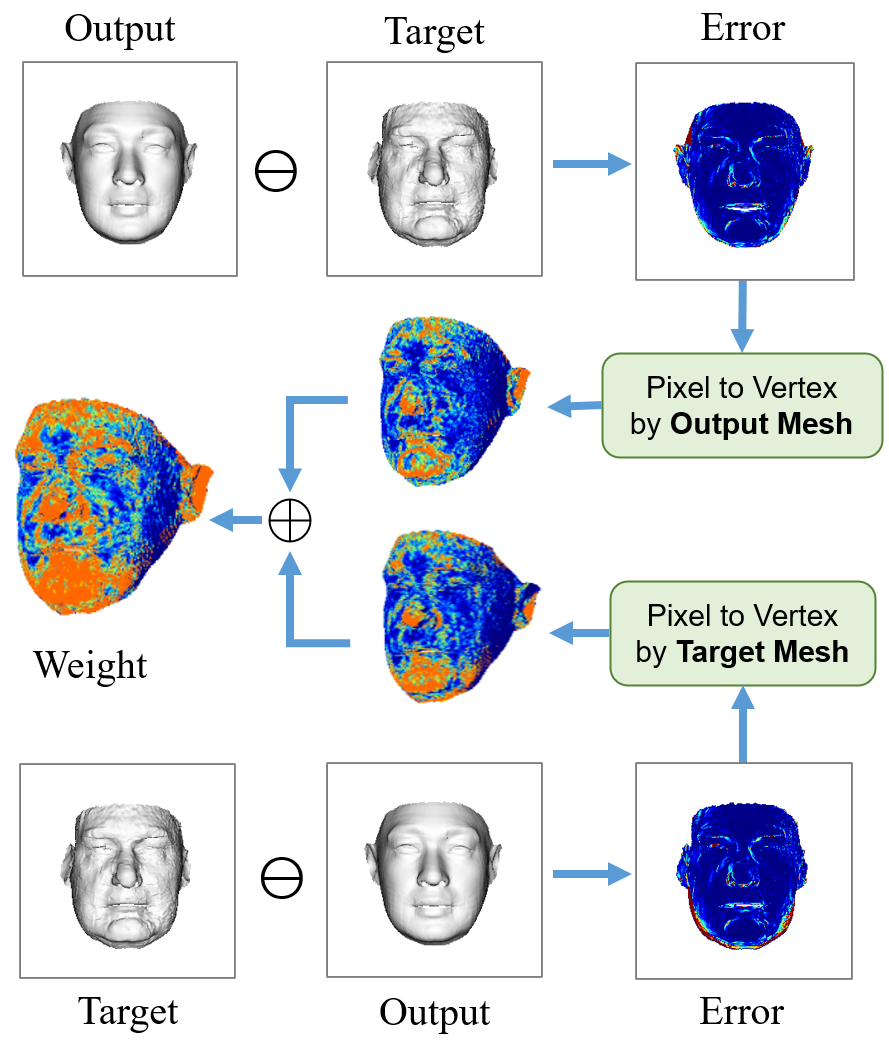
Figure 6: Visual-guided weights articulating the contribution of vertex weights to visual effect improvement.
Experiments and Results
Comprehensive experiments culminate in superior reconstruction accuracy as evidenced by reduced Normalized Mean Error (NME) and Densely Aligned Chamfer Error (DACE) across benchmarks.
Conclusion
The proposed approach extends beyond traditional frameworks such as 3DMM, refining high-fidelity face reconstruction from single images through pronounced data augmentation strategies, innovative network structures, and loss functions that emphasize visual verisimilitude. The method shows promising results in achieving greater accuracy and fidelity in 3D face reconstruction, paving the way for future developments in this domain.

