- The paper introduces a novel weight fusion technique that aggregates multiple finetuned models to create superior base models.
- It shows that fused models consistently achieve higher accuracy and stability over conventional pretraining, even under weight decay.
- Experimental evaluations on tasks like NLI and text classification confirm the practical benefits of this fusion approach for efficient initialization.
"Fusing Finetuned Models for Better Pretraining"
Introduction
The paper "Fusing finetuned models for better pretraining" (2204.03044) addresses the challenge of improving pretrained models' performance while mitigating the high computational costs associated with training them from scratch. The authors introduce a novel methodology to construct enhanced base models through weight averaging of multiple finetuned models. This fusion technique leverages the finetuned models, often more readily available than pretrained ones, to outperform standard pretraining and intertraining methods in terms of accuracy and training stability.
Methodology
The central contribution of this work lies in the proposed model fusion process. By aggregating the weights from several finetuned models, the authors aim to create a unified base model that can serve as a superior initialization point for subsequent finetuning tasks.
\begin{align*}
W_{fuse} &= \frac{W_1 + W_2 + \ldots + W_n}{n}
\end{align*}
This approach contrasts with typical transfer learning paradigms, which primarily focus on adapting pretrained models to specific tasks. Instead, this methodology utilizes the diversity and abundance of finetuned models to generate more robust pretrained models, thereby reversing the conventional transfer learning framework (Figure 1).
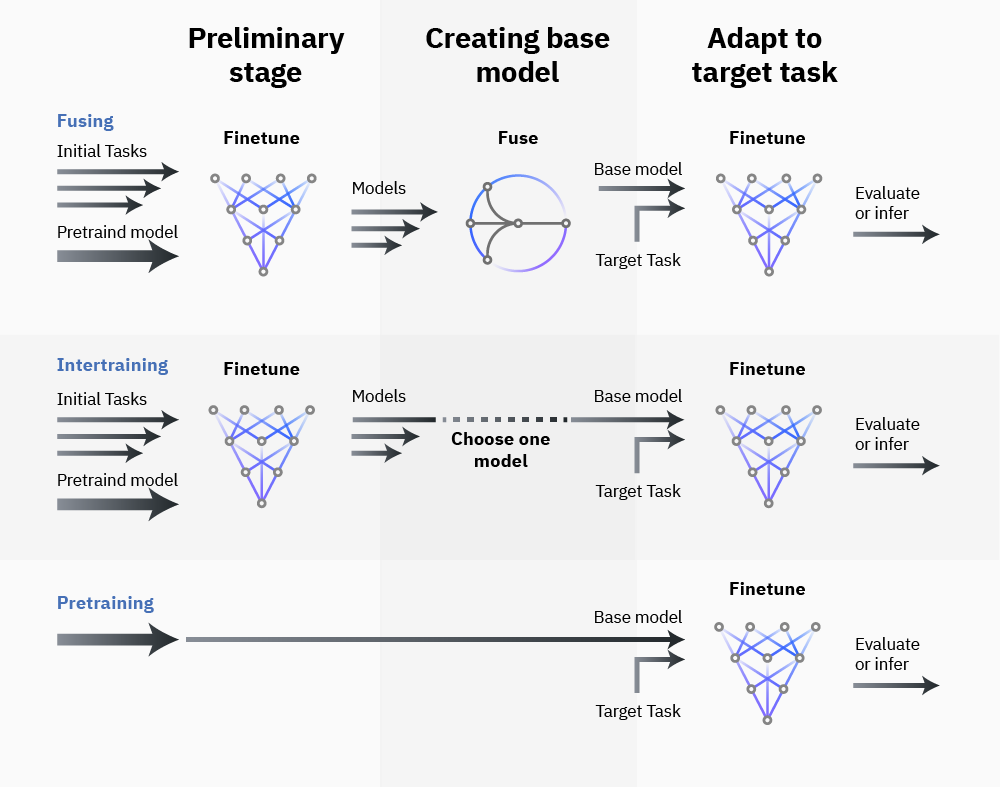
Figure 1: Different uses for available finetuned models ranging from ignoring to intertraining to fusing.
Experimental Evaluation
Experiments were conducted across diverse families of datasets, including general text classification, natural language inference (NLI), and Twitter-specific tasks. The primary comparison sets were fusing, intertraining, and baseline pretraining models. Notably, fused models consistently exhibited superior performance over pretrained models across various settings, demonstrating heightened accuracy and stability.
The findings showed that carefully selecting models for fusion—especially those beneficial for intertraining—yielded the best outcomes. For instance, fusing MNLI and SST2 models produced the highest results, outperforming individual intertrained models (Figure 2).
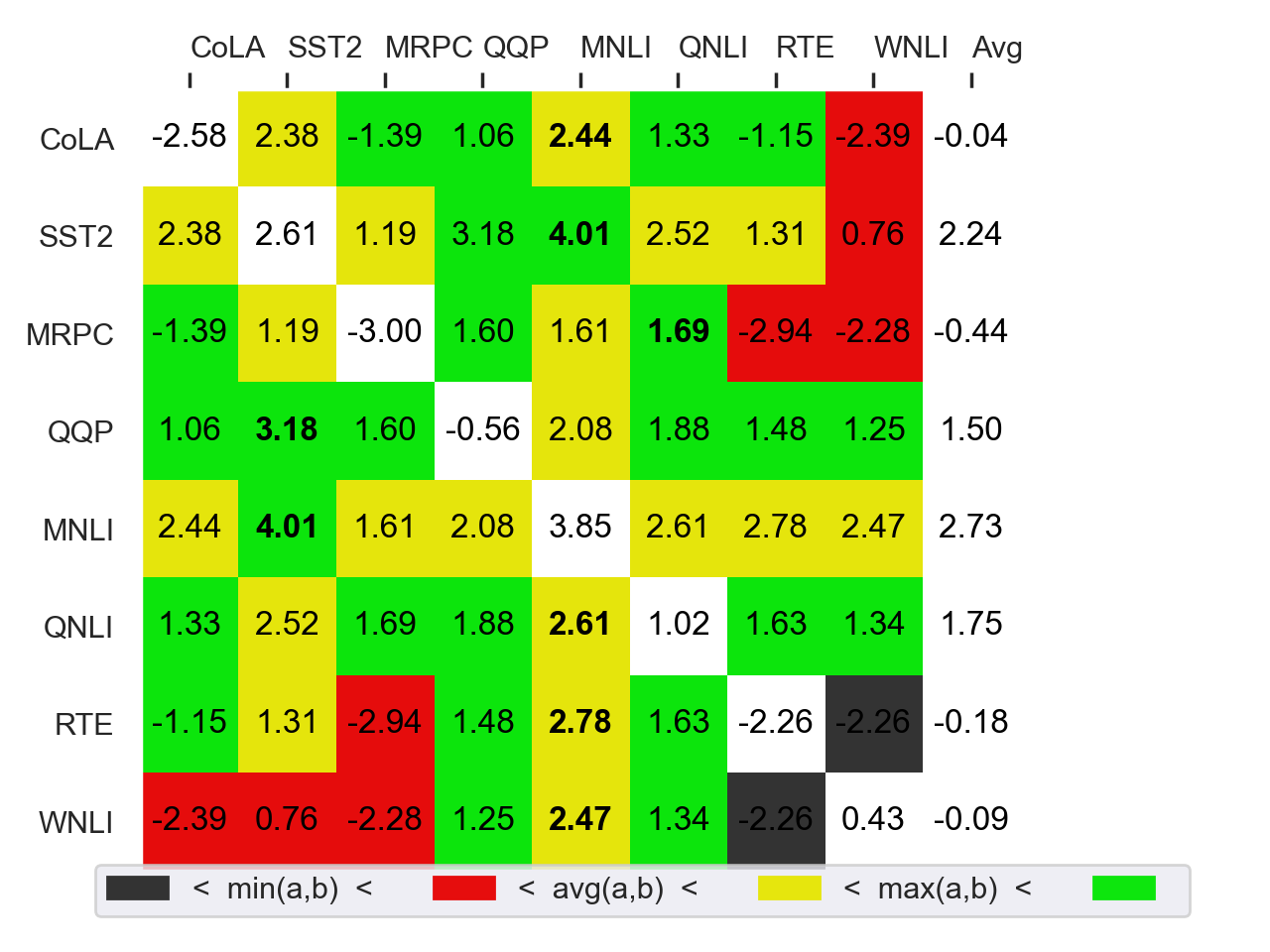
Figure 2: Fusing two models often surpasses individual model intertraining on GLUE datasets.
Sensitivity to Weight Decay
The authors report that intertraining effectiveness diminishes when weight decay is applied, unlike fusing methods, which remain robust. This robustness suggests that fused models inherently possess qualities resistant to regularization-induced degradation, further validating the viability of this technique.
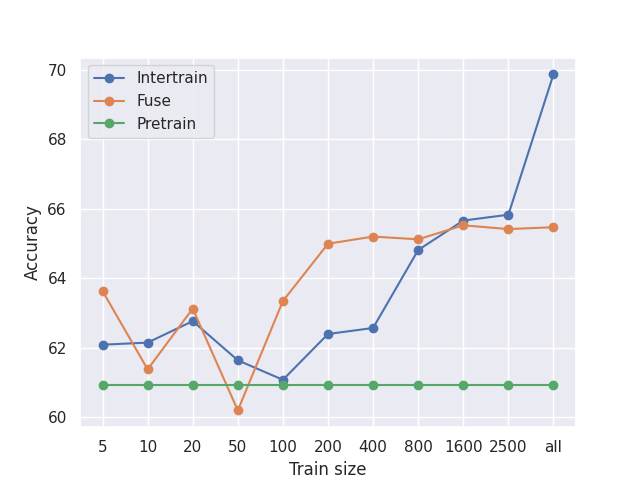
Figure 3: Increasing source data improves fused models, depicted as accuracy on general target datasets by source data amount.
This research intersects with extant studies on model fusion and transfer learning, expanding upon concepts such as monotonic linear interpolation and linear mode connectivity. Synchronizing insights from these fields bolsters the rationale behind employing weight fusion to enhance pretrained models without access to extensive training resources.
Conclusion and Future Directions
Overall, the paper illustrates the utility of model fusion in creating more efficient and accurate base models for finetuning. Future research avenues include optimizing fusion methodologies, exploring meta-learning scenarios, and adapting fusion techniques to handle models of varying sizes. These directions hold promise for refining the architecture and efficacy of pretrained models, potentially reshaping standards in transfer learning practices.