- The paper introduces novel lightweight modules (FLD, UAFM, SPPM) that balance segmentation accuracy and speed in real-time scenarios.
- The paper demonstrates an effective encoder-decoder architecture with feature aggregation and attention fusion, achieving up to 77.5% mIoU on Cityscapes.
- The paper validates PP-LiteSeg's design with state-of-the-art performance benchmarks, delivering speeds up to 273.6 FPS for real-time segmentation.
PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model
Introduction
The "PP-LiteSeg" paper (2204.02681) introduces a novel approach to tackle the real-time semantic segmentation challenge, emphasizing the performance trade-off between accuracy and speed. The detailed design of PP-LiteSeg is motivated by the increasing demand for efficient models capable of precisely labeling each pixel in high-resolution images. Traditional methods based on deep learning have shown notable progress; however, their computational expense limits their applicability in real-time scenarios. PP-LiteSeg addresses these constraints through the integration of three innovative modules: Flexible and Lightweight Decoder (FLD), Unified Attention Fusion Module (UAFM), and Simple Pyramid Pooling Module (SPPM).
Architecture Overview
The architecture of PP-LiteSeg consists of an encoder-decoder design complemented by aggregation modules. The encoder utilizes a lightweight network to extract multilevel features, which are subsequently enhanced by the SPPM for global context aggregation. Post-aggregation, the FLD facilitates efficient fusion of detailed and semantic features, aided by UAFM to amplify feature representation strength. This strategic combination not only optimizes computational efficiency but achieves high segmentation accuracy across diverse datasets.
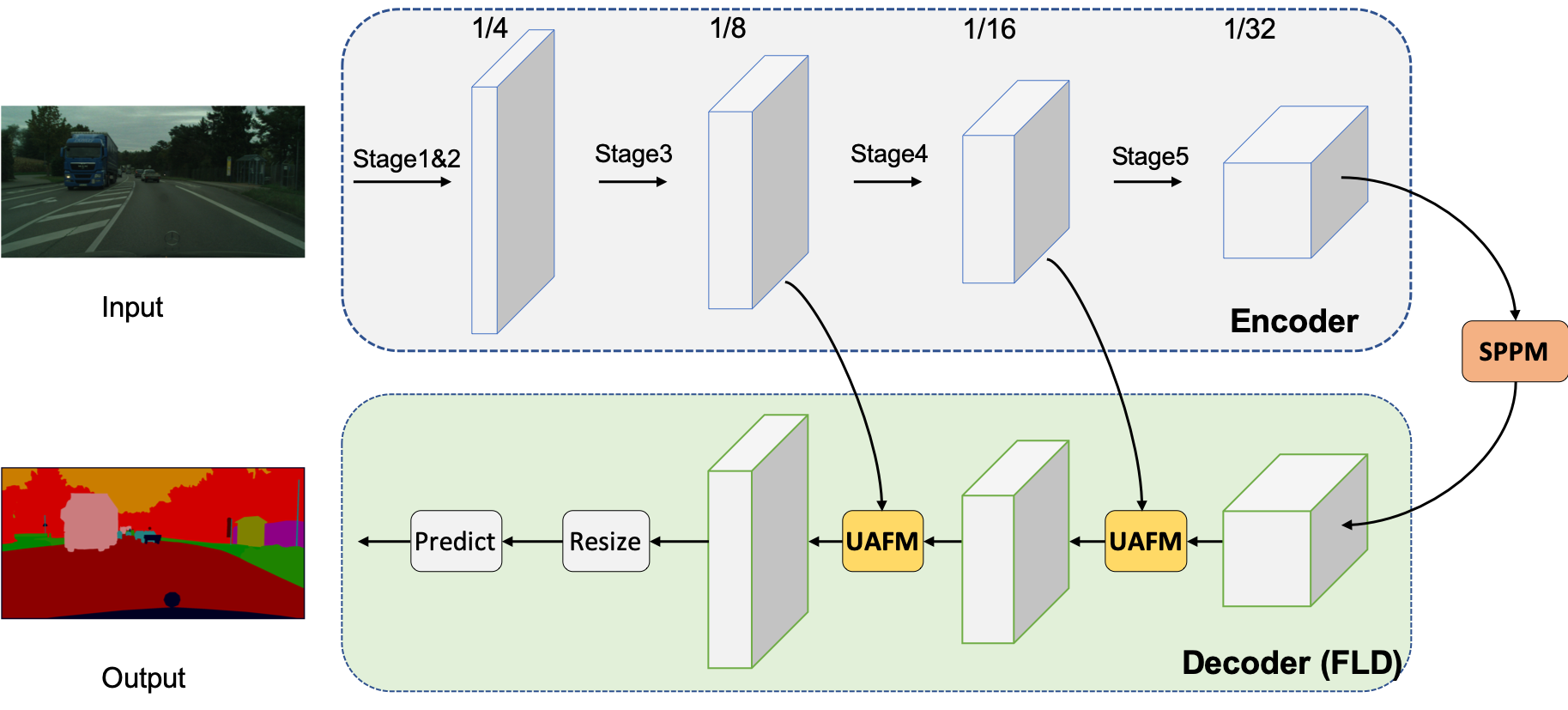
Figure 1: The architecture overview. PP-LiteSeg consists of encoder, aggregation, and decoder modules.
Key Modules
Flexible and Lightweight Decoder (FLD)
FLD redefines the conventional decoder architecture by dynamically reducing feature channels as the spatial size increases. Unlike typical decoders maintaining uniform channels, FLD’s adaptable design mitigates redundancy and aligns computational effort between encoder and decoder. This approach enhances efficiency, facilitating superior segmentation without compromising accuracy.
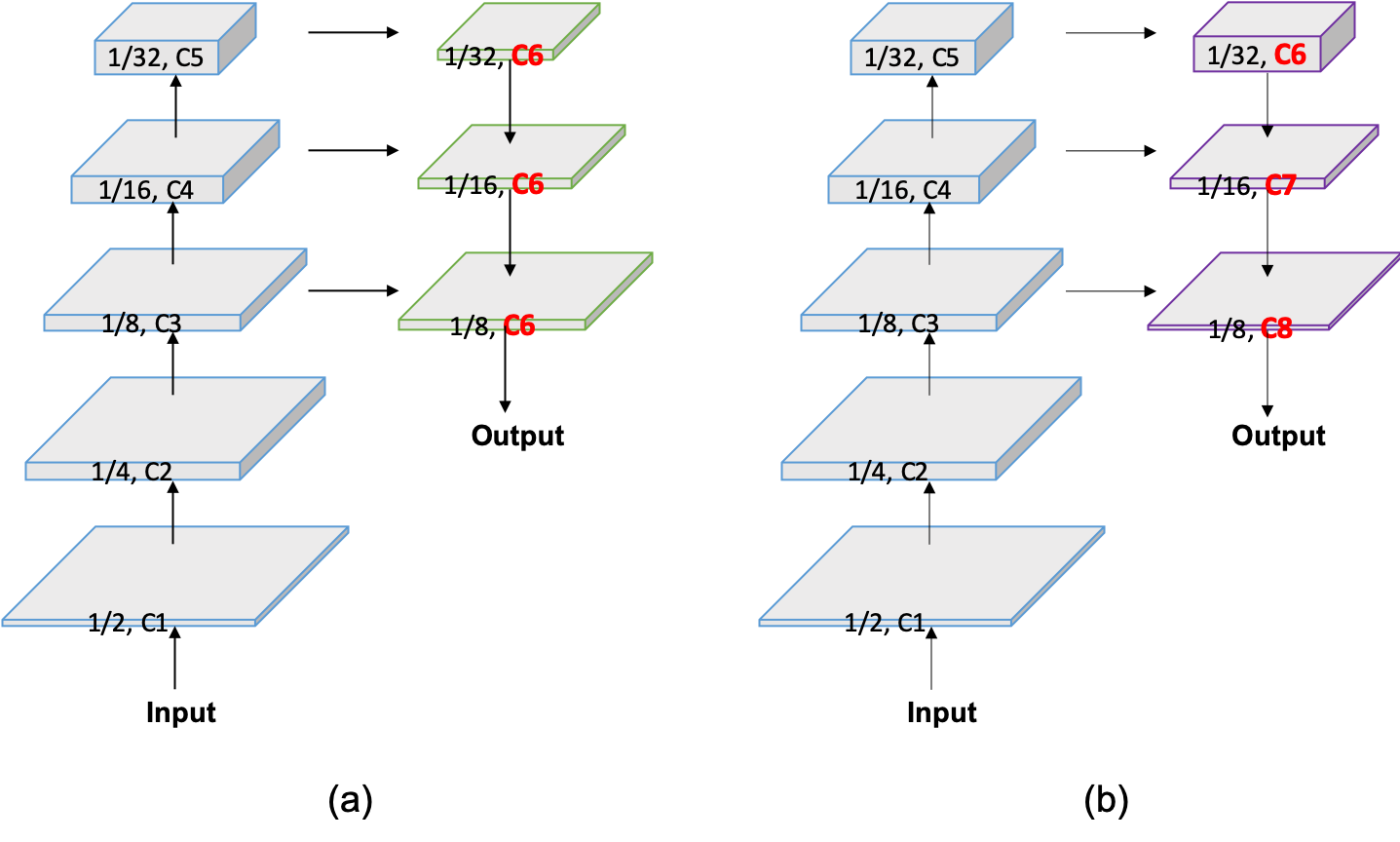
Figure 2: FLD gradually reduces feature channels from high to low levels, conforming to encoder volume.
Unified Attention Fusion Module (UAFM)
UAFM distinguishes itself through effective feature representation enhancement using attention mechanisms. It employs spatial and channel attention modules to calculate weights, which are subsequently fused with the input features via multiplication and addition operations. This fusion process enriches the representation fidelity, driving improvements in segmentation precision.
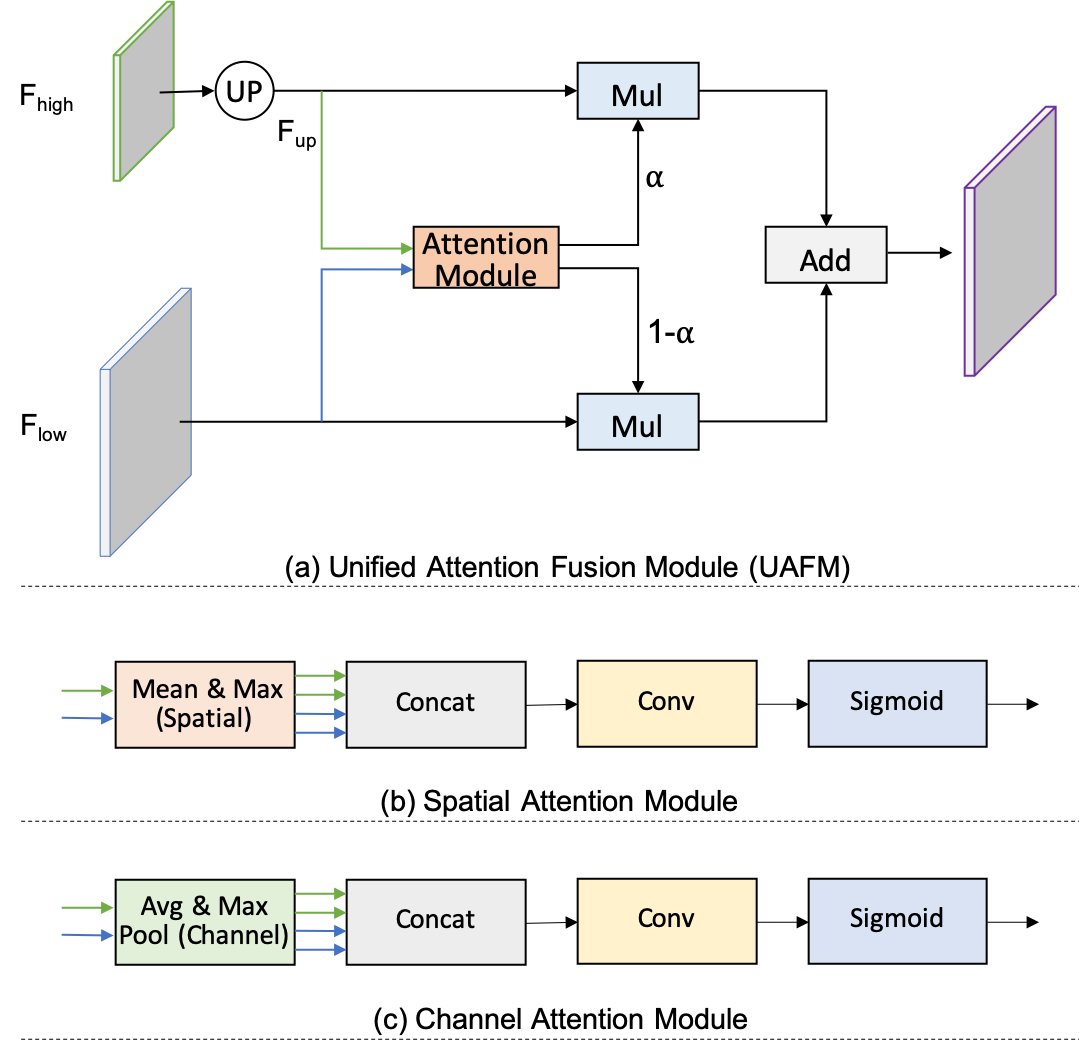
Figure 3: UAFM employs spatial and channel attention, producing weights for feature fusion operations.
Simple Pyramid Pooling Module (SPPM)
The SPPM optimizes global context aggregation while maintaining computational efficiency. Utilizing bin sizes for global-average pooling, SPPM improves segmentation outcomes at minimal additional computational cost, making it well-suited for real-time application in semantic segmentation tasks.
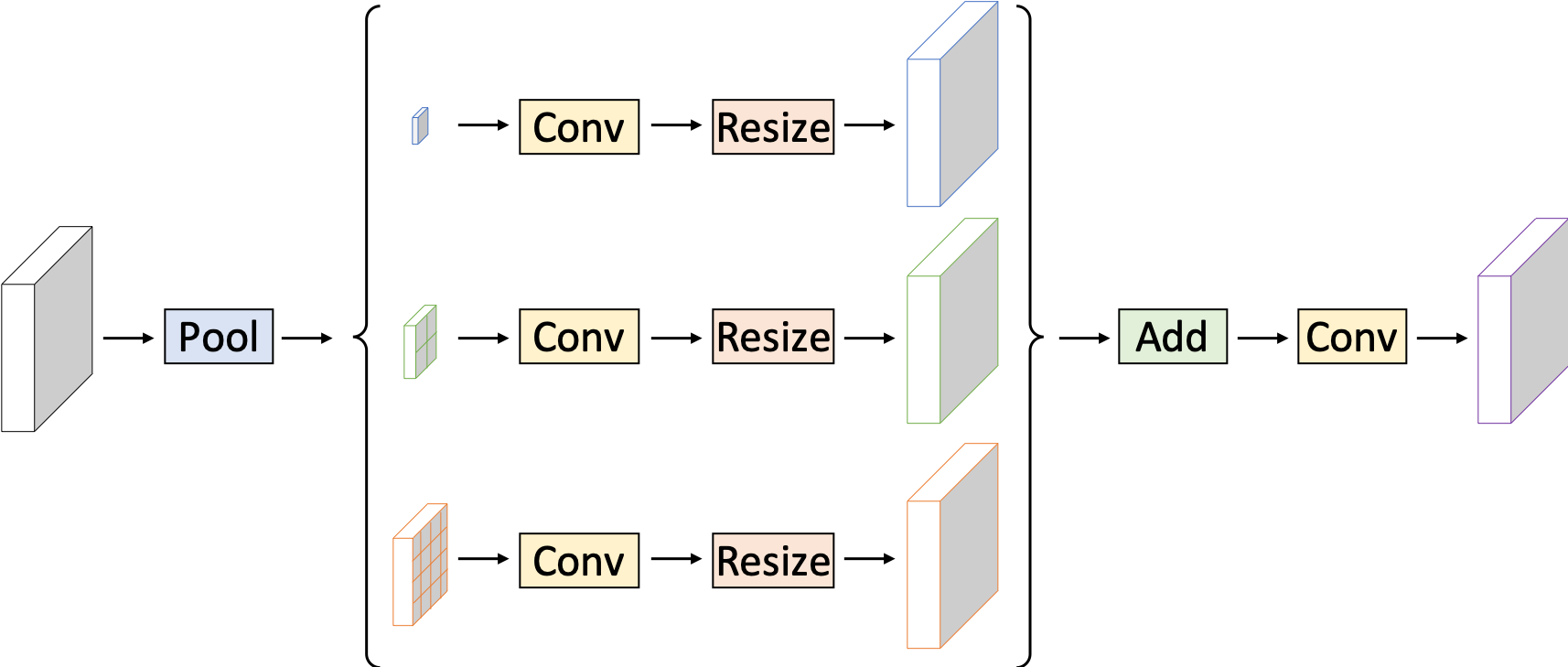
Figure 4: SPPM employs convolution and pooling to enhance global context aggregation efficiently.
Experimental Results
PP-LiteSeg demonstrates state-of-the-art performance across datasets, including Cityscapes and CamVid. On the Cityscapes test set, it achieves an impressive 72.0% mIoU with 273.6 FPS and 77.5% mIoU at 102.6 FPS, signifying an optimal balance between speed and accuracy that surpasses existing real-time models (Figure 5).
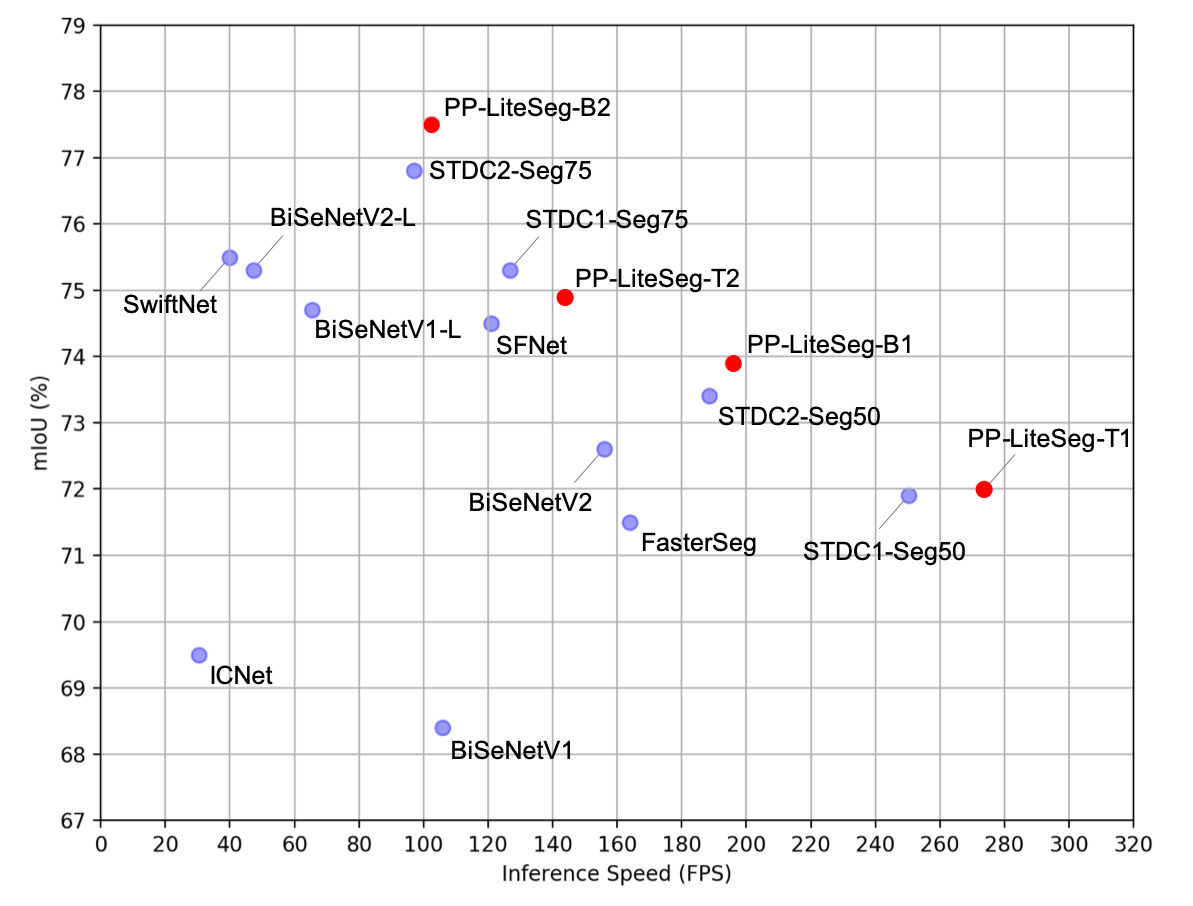
Figure 5: Superior trade-off between accuracy and speed achieved by PP-LiteSeg on Cityscapes.
Beyond quantitative metrics, qualitative analyses validate the efficacy of the proposed modules, showing refined feature integration and consistent pixel-wise accuracy improvements with each module addition (Figure 6).
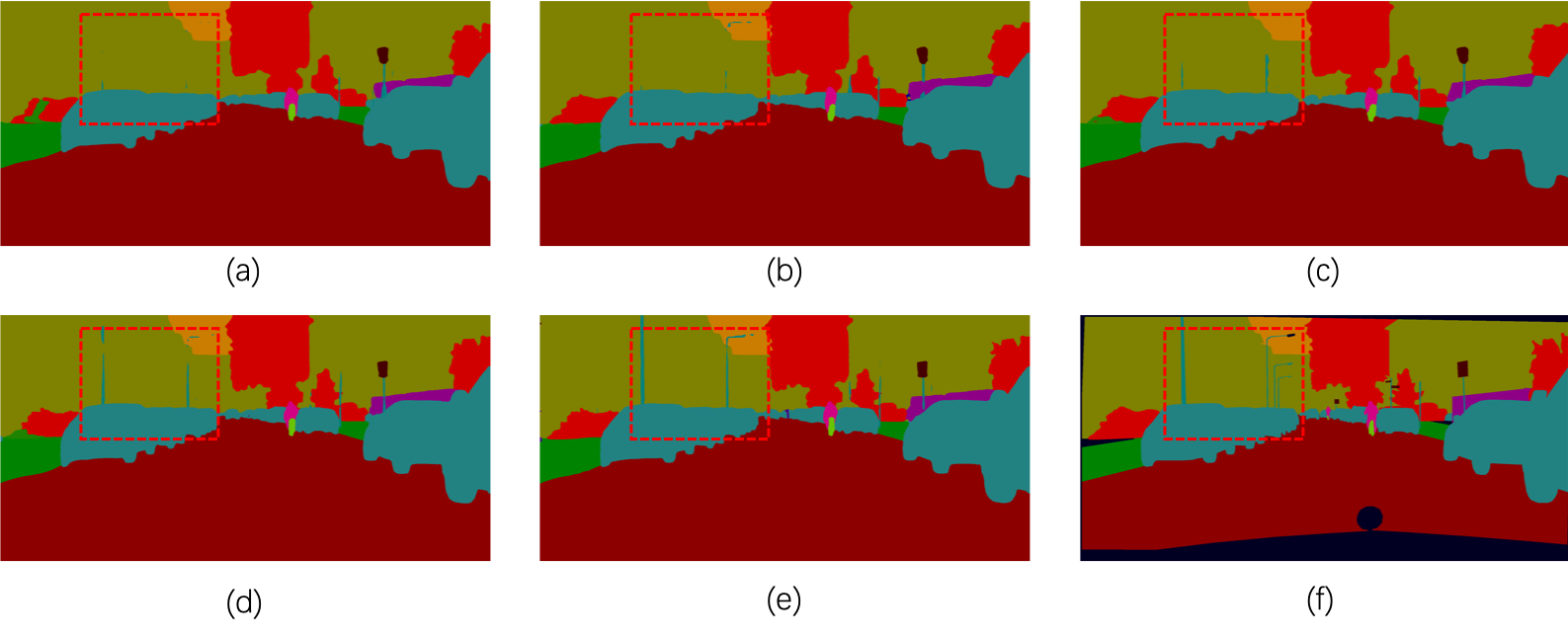
Figure 6: Qualitative comparison illustrating improvements in pixel accuracy as modules are integrated.
Conclusion
PP-LiteSeg effectively addresses the limitations of conventional semantic segmentation models by integrating novel modules to optimize computational cost and segmentation precision. The advancements in efficiency and accuracy with PP-LiteSeg set a benchmark for future real-time segmentation models. Future work will explore adaptations of these techniques for other tasks such as matting and interactive segmentation. These explorations promise to further extend the applications and efficiency of semantic segmentation methodologies.