- The paper introduces MFA-Conformer, a novel architecture integrating multi-scale feature aggregation with Conformer blocks for robust speaker embedding extraction.
- The model achieves a significant performance boost, reducing the Equal Error Rate to 0.64% on VoxCeleb1-O and surpassing traditional CNN-based systems.
- The architecture leverages a combination of CNN and Transformer elements to capture both local details and global context, improving inference speed and accuracy.
Introduction
The paper "MFA-Conformer: Multi-scale Feature Aggregation Conformer for Automatic Speaker Verification" introduces the MFA-Conformer, an innovative architecture tailored for automatic speaker verification leveraging the Conformer model. This model uniquely integrates multi-scale feature aggregation techniques with Conformer blocks to enhance both global and local feature representation, optimizing speaker embedding extraction.
Architectural Design
The architecture of the MFA-Conformer is centered around effectively capturing both global dependencies and local features through the integration of Conformer blocks. Conformer blocks are a hybrid adaptation combining CNNs and Transformers, effectively leveraging the strengths of both architectures. These blocks employ multi-head self-attention (MHSA) mechanisms with relative positional encoding alongside convolution modules to simultaneously model local detail and global context.
The Conformer block architecture is distinct from traditional Transformer blocks by incorporating two Macaron-like feed-forward networks (FNN) that encase the MHSA and convolution modules. This design ensures a balanced modeling of local and global features, optimizing embedding extraction for variable-length speech inputs.

Figure 1: The overall architecture of Multi-scale Feature Aggregation Conformer (MFA-Conformer).
Experimental Evaluation
The MFA-Conformer was rigorously evaluated on benchmarks such as VoxCeleb1-O, SITW.Dev, and SITW.Eval, demonstrating superior performance over existing models like the ECAPA-TDNN. The MFA-Conformer achieved significant reductions in Equal Error Rate (EER), notably 0.64% on VoxCeleb1-O, compared to baseline systems. The architecture also demonstrated increased inference speed, benefiting from an efficient convolution subsampling layer.
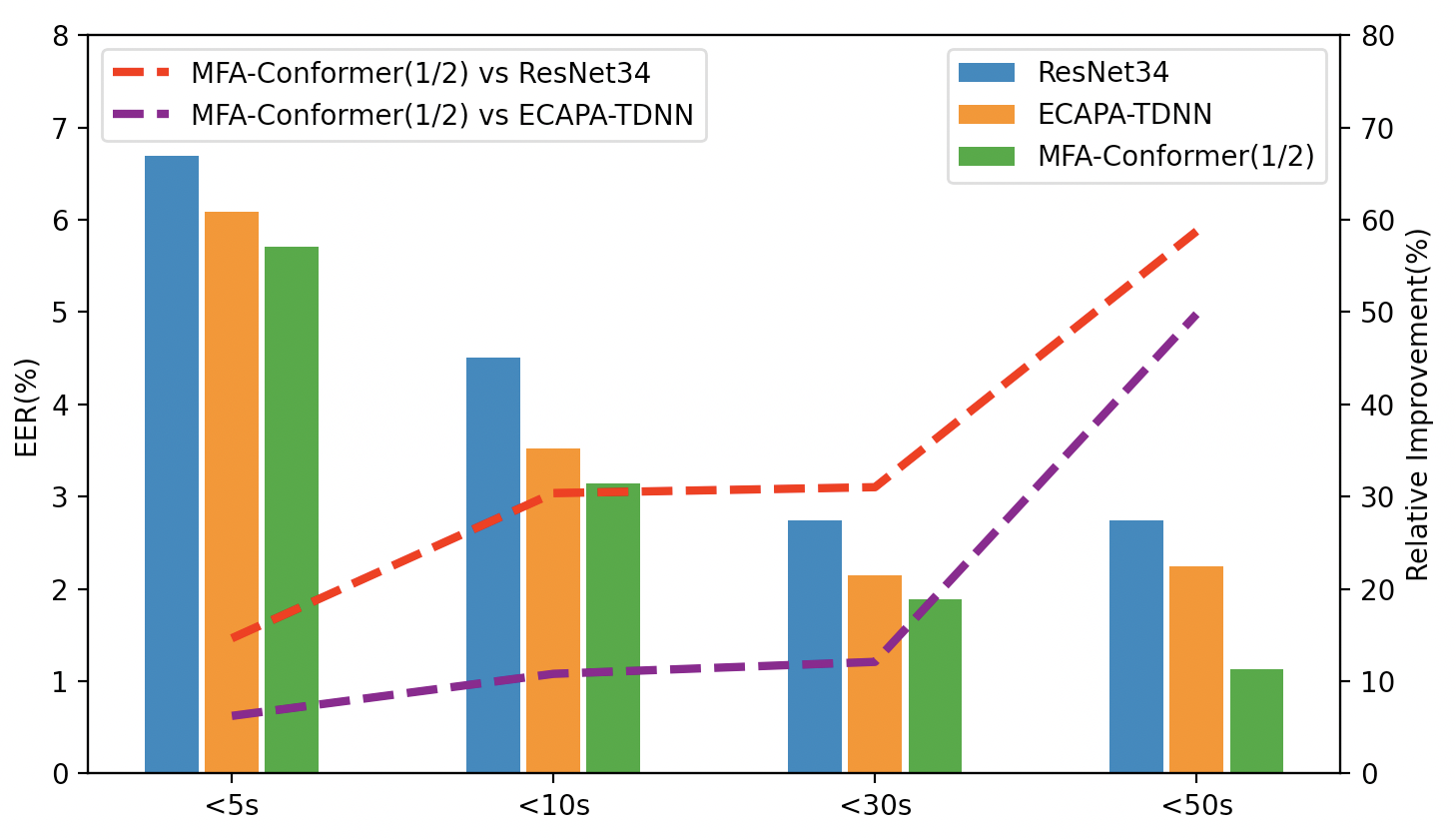
Figure 2: Performance of MFA-Conformer (1/2) and two baselines with different utterance durations. The bars denote the EERs, and the dotted lines denote the relative improvement of MFA-Conformer (1/2) over the two baseline.
Practical and Theoretical Implications
Practically, the MFA-Conformer enhances automatic speaker verification systems by providing robust speaker embeddings even with varied utterance lengths. This capability is vital in real-world applications such as speaker diarization, voice conversion, and speech recognition, where utterance durations and contexts frequently change.
Theoretically, the paper underscores the significance of combining global and local feature learning for robust speaker verification. It challenges the dominance of CNNs by demonstrating that, through appropriate architectural adaptations, Transformers can achieve superior performance in ASV tasks without extensive pre-training.
Future Directions
The paper suggests several future research trajectories, including the adaptation of MFA-Conformer to streaming ASV scenarios. This would further enhance its applicability in real-time systems. Additionally, exploring modifications to further decrease computational overhead while maintaining accuracy could be beneficial for deploying in resource-constrained environments.
Conclusion
The MFA-Conformer presents a noteworthy advancement in the field of automatic speaker verification by integrating multi-scale feature aggregation within a Conformer-based framework. This approach not only outperforms traditional CNN-based systems but also opens up new avenues for embedding extraction techniques capable of handling diverse input lengths and complexities. The research provides both practical improvements and theoretical insights, marking a significant step forward in speaker recognition technology.