- The paper introduces a unifying framework for integrating XAI into ML pipelines via data, feature, loss, gradient, and post-training augmentations.
- The approach demonstrably improves model generalization, robustness, and reasoning alignment, achieving reproducible gains of 1–5% in test accuracy.
- Empirical results and systematic reviews reveal trade-offs, highlighting challenges in balancing accuracy with fairness and semantic reasoning.
XAI-Based Model Improvement: Frameworks, Methods, and Empirical Outcomes
Introduction and Motivation
The presented work "Beyond Explaining: Opportunities and Challenges of XAI-Based Model Improvement" (2203.08008) critically surveys how eXplainable Artificial Intelligence (XAI) methods, traditionally used for visualization and diagnostic purposes, can actively enhance ML models. The motivation arises from the limitations associated with black-box deep neural networks (DNNs), notably their lack of transparency, trustworthiness, and susceptibility to spurious correlations and biases. Although XAI has recently gained traction, its operational integration into model improvement pipelines remains underdeveloped, with little systematization of method classes, properties affected, and empirical efficacy.
Categorization of XAI-Based Improvement Methods
A central contribution of this paper is the formalization of a unifying theoretical framework that classifies XAI-based model improvement strategies according to the augmented component within the ML pipeline:
- Data Augmentation: Leveraging explanations to modify or generate training samples, thus mitigating dataset biases or rebalancing distributions.
- Intermediate Feature Augmentation: Using attribution methods to highlight, mask, or transform hidden-layer representations to emphasize relevant patterns during forward passes.
- Loss Function Augmentation: Incorporating explanation-derived regularization terms into the objective to steer learning towards improved reasoning, robustness, or fairness.
- Gradient Augmentation: Modifying the direction and magnitude of parameter updates using explanation-informed importance scores, impacting optimization dynamics directly.
- Model Post-Training Augmentation: Employing explanations to efficiently prune or quantize network parameters, optimizing memory and inference costs.
This framework provides a multidimensional mapping between augmentation loci and the specific model properties targeted (e.g., generalization, convergence speed, robustness, efficiency, reasoning, equality).
Empirical Demonstrations
The work illustrates, through controlled toy experiments and applications to realistic settings, that XAI-derived feedback can yield strong effects on core model properties. These include:
- Performance Enhancement via attention-masking guided by local attributions, leading to improved generalization and diminished overfitting.
- Robustness improvement through explanation-guided dropout, actively disrupting reliance on confounding features to boost out-of-distribution accuracy.
- Reasoning Alignment by inclusion of ground-truth explanation masks in loss regularization, directly forcing models to rely exclusively on semantically desired input features.
Empirical evidence supports that such XAI-driven interventions can alter the trajectory of training, output different decision boundaries, and modulate the explanatory saliency attributions in interpretable ways.
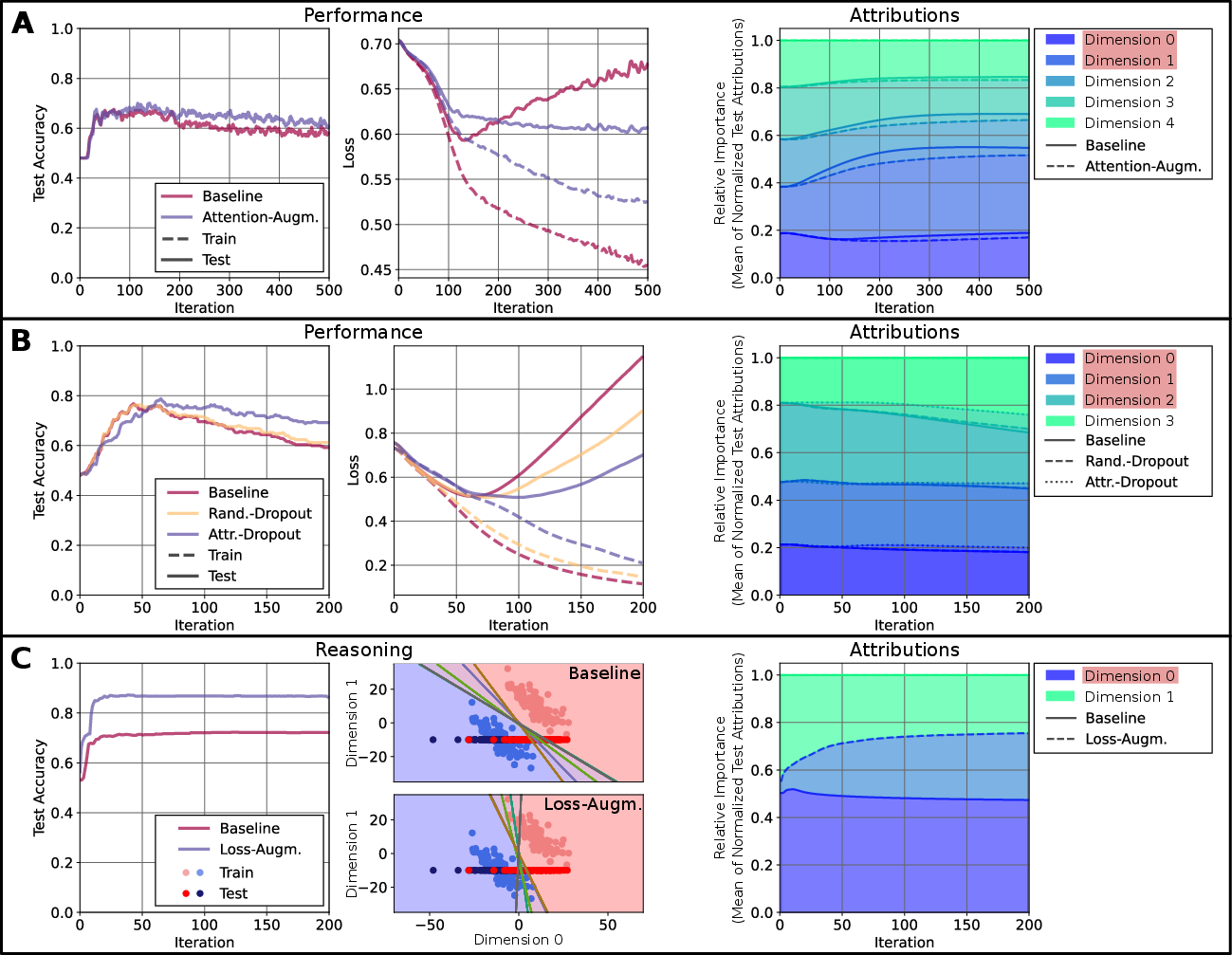
Figure 1: Toy experiments demonstrating the opportunities of XAI—including attention-based feature masking, explanation-guided dropout, and loss regularization—for model improvement across generalization, robustness, and reasoning.
Systematic Literature Review
The paper provides a structured synthesis of contemporary techniques under the XAI-improvement umbrella, highlighting heterogeneity in operational mechanism, property focus, and the required level of human interaction. Notable reviewed methods include:
- Explanatory Interactive Learning (XIL) [Teso et al., Schramowski et al.]: Interactive, expert-corrected explanation mechanisms yielding instance-level corrections and synthetic counter-example generation.
- Attention Branch Network (ABN) [Fukui et al., Mitsuhara et al.]: Incorporates visual attention maps as actionable guidance for feature masking, amenable to human correction.
- Explanation-Guided Training [Sun et al.]: Utilizes LRP-generated masks for feature modulation in few-shot learning, with statistically significant increases in cross-domain test accuracy.
- Explanation-Based Pruning and Quantization [Yeom et al., Sabih et al.]: Applies relevance maps for network sparsification and mixed-precision assignment, preserving or boosting accuracy relative to baseline post-processing methods.
Additionally, critical evaluations underscore the trade-offs between computational efficiency, model agnosticity, and improvement scope for each method class.
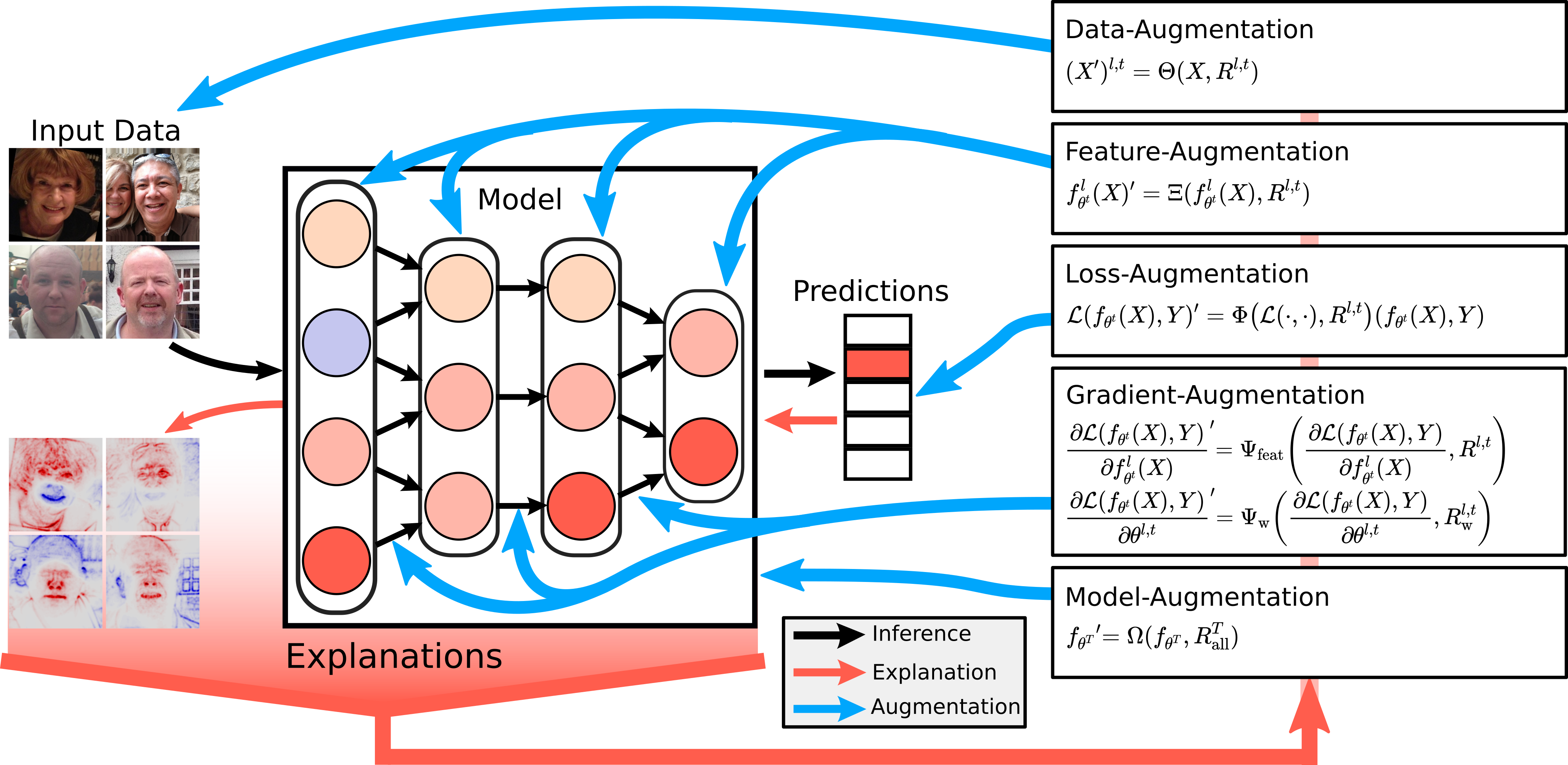
Figure 2: Schematic diagram of how explanations inform model improvement by intervention at different stages of the training loop (data, features, loss, gradients, and post-training structure).
Strong Numerical Results and Contradictory Claims
Across empirical analyses, the authors report reproducible gains in test accuracy, generalization, and class-wise balance (typically in the range of 1–5% depending on domain and augmentation strategy) when XAI is actively integrated, especially in few-shot and imbalanced learning scenarios. Importantly, a contradictory claim arises: XAI-based improvement sometimes decreases benchmark test accuracy in order to achieve higher-level properties such as fairness or reasoning, highlighting a fundamental limitation of naive accuracy-centric evaluation. The paper emphasizes that model reasoning aligned with semantic ground truth may necessitate sacrificing superficial statistical performance—an assertion verified in both toy and real datasets.
Limitations and Practical Recommendations
The authors identify multiple caveats:
- The utility of XAI feedback depends crucially on the quality, consistency, and interpretability of the explanation method itself.
- Model improvement via XAI may be sensitive to initialization, architecture, and the hyperparameters of explanation generation.
- Regularization or masking based on explanations can be manipulated ("fairwashing"), undermining their reliability for enforcing semantic alignment [Dombrowski et al., Anders et al.].
- Human-in-the-loop approaches (loss regularization via expert-provided masks) involve substantial manual annotation overhead, limiting scalability.
Practically, it is recommended that XAI-based interventions are applied judiciously, with careful benchmarking against non-XAI alternatives, robust evaluation across random seeds, and systematic selection of compatible explanation and augmentation strategies.
Theoretical Implications and Future Directions
This paper serves as a foundation for the argument that XAI should transition from a diagnostic to an operational tool in ML. By integrating explanation signals into the pipeline, models can be steered towards more reliable, fair, efficient, and generalizable behavior, with implications for domains where trust and reasoning are critical (medical, legal, safety-critical systems).
Future work may extend towards:
- Joint or hybrid augmentation strategies (e.g., simultaneous data and gradient interventions).
- Development of new XAI metrics that directly quantify semantic reasoning in complex, multi-modal tasks.
- Investigation of manipulation-resistant explanation methods to safeguard against fairwashing and adversarial compliance.
Conclusion
The paper establishes a comprehensive taxonomy of XAI-based model improvement methodologies, provides strong evidence for their practical benefits, and issues nuanced guidance on their proper use. As the ML community moves toward models that must be not only accurate but interpretable, fair, and robust, XAI-enabled augmentation will become integral to the design of next-generation learning systems. Carefully navigated, such techniques can address foundational challenges in deploying ML in real-world, high-stakes environments.

