- The paper introduces a novel two-stage AR framework leveraging Residual-Quantized VAE to overcome traditional VQ limitations and enhance image fidelity.
- The RQ-Transformer employs spatial and depth transformers to efficiently model and predict stacked discrete codes for high-resolution images.
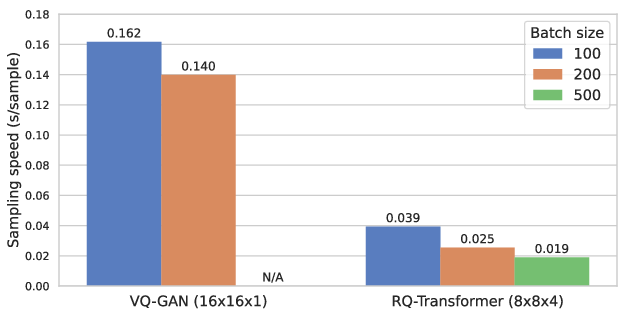
- Experimental results demonstrate state-of-the-art performance with improved FIDs, IS scores, and up to 7.3x faster sampling compared to existing methods.
Autoregressive Image Generation using Residual Quantization
Introduction
This paper presents a novel two-stage framework for autoregressive (AR) image generation leveraging Residual Quantization (RQ). The primary motivation is to address the limitations of traditional Vector Quantization (VQ), which poses a trade-off between reducing the sequence length of codes and maintaining image fidelity due to the rate-distortion constraint. The proposed framework consists of the Residual-Quantized VAE (RQ-VAE) and the RQ-Transformer, designed to generate high-resolution images efficiently.
Methodology
Residual-Quantized VAE
The RQ-VAE replaces traditional VQ with a residual quantization technique to overcome the limitations of the codebook size. RQ quantizes a feature map of an image into a stack of discrete codes, allowing for precise approximation without requiring a massive codebook. This is achieved by recursively quantizing the residual errors, resulting in a coarse-to-fine approximation of the feature map.
The RQ process can be defined as follows:
- Start with the feature vector z and initialize the residual vector r0=z.
- For each depth d, compute the nearest code kd from a shared codebook and the new residual rd.
- Accumulate the embeddings of these codes to approximate the original vector.
The RQ-VAE encodes an image into a reduced resolution feature map, enabling more efficient AR modeling of images.
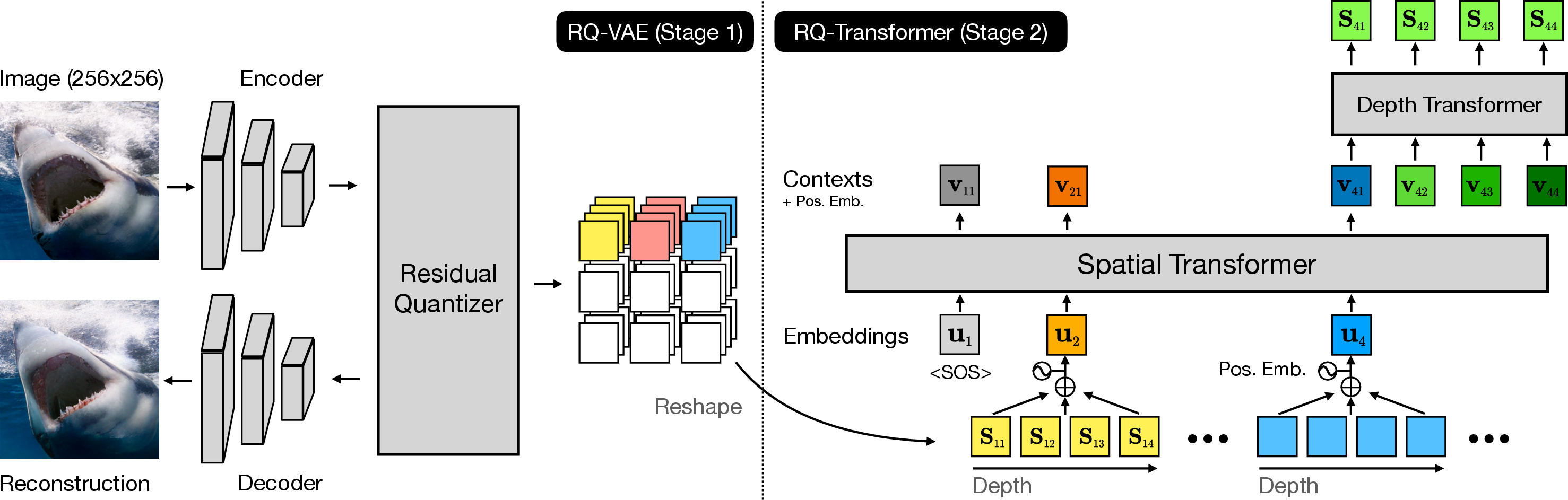
Figure 1: An overview of our two-stage image generation framework composed of RQ-VAE and RQ-Transformer. In stage 1, RQ-VAE uses the residual quantizer to represent an image as a stack of D=4 codes. After the stacked map of codes is reshaped, RQ-Transformer predicts the D codes at the next position.
The RQ-Transformer is designed to efficiently predict the quantized feature vectors provided by RQ-VAE. It utilizes a combination of spatial and depth transformers to handle the reduced sequence length efficiently.
- Spatial Transformer: Processes the sequence of input feature maps to generate context vectors, capturing information from previous positions.
- Depth Transformer: Autoregressively predicts the multiple depth codes for each position, utilizing the context vectors generated by the spatial transformer.
This architecture reduces computational complexity compared to na"ive transformer models, thanks to its design focused on handling shorter sequences more effectively.
Experimental Results
The proposed framework achieves superior performance on various benchmarks for both unconditional and conditional image generation tasks compared to existing AR models.


Figure 3: Additional examples of conditional image generation by 1.4B parameters of RQ-Transformer trained on ImageNet.
Efficiency and Ablation Study
The computational efficiency of the RQ-Transformer is highlighted by achieving fast image generation speeds while maintaining high-quality output. Ablation studies reveal the impact of various architectural choices, such as the depth of residual quantization and using a shared codebook for all quantization steps.
Conclusion
The integration of RQ-VAE and RQ-Transformer offers a robust solution for high-resolution image synthesis with AR models, addressing the limitations of traditional VQ methods. The precise approximation of feature maps and efficient modeling of sequences empower the framework to outperform existing models in terms of quality and speed on significant image generation benchmarks. Future work could further explore regularization techniques for small datasets and scaling models for text-conditioned generation tasks.