- The paper presents a two-stage U-Net architecture that significantly improves the removal of hiss, clicks, and other degradations in historical recordings.
- It utilizes STFT-based spectrograms and a supervised attention module to efficiently model and suppress residual noise.
- Objective evaluations and listener tests confirm the model's superior performance in enhancing SNR and perceptual audio quality compared to traditional methods.
High-Fidelity Denoising of Historical Recordings
This paper introduces a novel audio denoising method aimed at enhancing the sound quality of historical music recordings. It utilizes a deep neural network structured as a two-stage U-Net architecture, specifically designed to suppress degradations such as hiss, clicks, and various other disturbances prevalent in analog recordings. The implementation operates on time-frequency representations of audio and is trained using noise data that mimics real-world conditions, outperforming existing methods based on both quantitative and listener evaluations.
Introduction to Audio Denoising Challenges
The problem of restoring historical audio recordings has been a persistent challenge, primarily due to their inherent low-quality caused by technological limitations during the time of recording. Common issues such as hiss and clicks require sophisticated restoration techniques. Historically, approaches like Wiener filtering, wavelet transformations, and spectral subtraction have been employed, all of which typically handle stationary noise exclusively. This paper circumvents limitations of traditional methods by employing deep learning strategies that leverage end-to-end neural architectures, specifically tailored for audio restoration (2202.08702).
Data Collection for Model Training
The efficacy of the proposed model is closely linked with the quality of its training data. The training dataset comprises clean classical music segments alongside noise data extracted from gramophone recordings. Noise data is mapped from historical gramophone records, capturing a wide range of anomalies including electrical noise, ambient interference, and disturbances inherently tied to the recording medium.
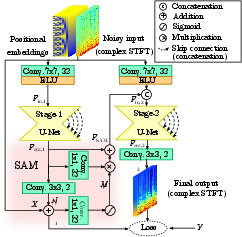
Figure 1: Two-stage denoising model with the SAM module.
Two-Stage U-Net Architecture
The two-stage U-Net architecture builds upon recent advancements in image restoration techniques, employing a supervised attention module (SAM) to enhance feature propagation between stages. The model inputs are processed via STFT to generate spectrograms, with distinct U-Net subnetworks focusing on residual noise modeling followed by comprehensive denoising. The innovation lies in its dual-phase operational design, enabling enhanced suppression of audio noise across extensive frequency ranges without introducing musical artifacts.
U-Net Subnetworks
U-Net subnetwork architecture plays a pivotal role in this work, encompassing symmetric encoder-decoder structures reinforced by DenseNet blocks featuring residual connections. These components foster improved feature communication through skip connections, thereby enabling effective denoising across various scales.
Experiments and Results
Objective evaluations demonstrated significant advancements over prior methods, with enhanced SNR and perceptual metrics. The two-stage architecture's denoising capability was assessed with both artificial and real-world noisy conditions, showcasing superior performance.
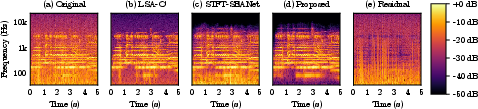
Figure 2: Log-spectrograms of (a) one of the listening test examples, (b,c,d) denoised versions, and (e) the residual noise.
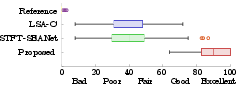
Figure 3: Box-plot visualization of the listening test results.
A blind listening test confirmed these findings, as participants consistently rated the proposed denoising method higher in audio quality compared to competing methods. The nuanced removal of low-frequency rumble contributed to its increased scores.
Conclusion
The introduction of the two-stage U-Net framework for audio denoising marks a significant stride toward restoring the fidelity of historical recordings. By employing realistic noise data and leveraging a robust deep learning architecture, the paper offers compelling improvements over existing strategies. This development underscores the potential of deep learning in the domain of audio restoration, inviting future research into advanced model designs and training methodologies that further exploit the capabilities of such architectures.

