Domain Adaptation via Prompt Learning
Abstract: Unsupervised domain adaption (UDA) aims to adapt models learned from a well-annotated source domain to a target domain, where only unlabeled samples are given. Current UDA approaches learn domain-invariant features by aligning source and target feature spaces. Such alignments are imposed by constraints such as statistical discrepancy minimization or adversarial training. However, these constraints could lead to the distortion of semantic feature structures and loss of class discriminability. In this paper, we introduce a novel prompt learning paradigm for UDA, named Domain Adaptation via Prompt Learning (DAPL). In contrast to prior works, our approach makes use of pre-trained vision-LLMs and optimizes only very few parameters. The main idea is to embed domain information into prompts, a form of representations generated from natural language, which is then used to perform classification. This domain information is shared only by images from the same domain, thereby dynamically adapting the classifier according to each domain. By adopting this paradigm, we show that our model not only outperforms previous methods on several cross-domain benchmarks but also is very efficient to train and easy to implement.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about helping an AI model recognize objects in new kinds of images where it hasn’t been given labels. For example, a model trained on labeled photos might need to work on unlabeled drawings or product pictures. This problem is called “Unsupervised Domain Adaptation” (UDA). The authors propose a new, simple way to do UDA using “prompts” (short text phrases) with a vision-LLM, so the model can adjust itself to each kind of image without messing up what it has learned about object categories.
Key Objectives and Questions
- How can we make a model trained on one type of images (the “source domain”) work well on a different type (the “target domain”) where we don’t have labels?
- Can we avoid the usual “force everything to look the same” tricks that can damage the model’s understanding of categories?
- Can we use text prompts to help the model understand both the object category (“dog”, “backpack”) and the image’s style or domain (“photo”, “sketch”, “product”) at the same time?
How They Did It
What is a “domain”?
A domain is the style or source of images. Examples:
- Photos from the real world
- Sketches or clip art
- Product images with clean backgrounds
Models often struggle when the domain changes because images look different, even if they show the same things.
What is a “prompt”?
A prompt is a short text phrase the model uses to understand an image, like “a photo of a [CLASS]”, where [CLASS] might be “cat” or “bus”. The model they use (called CLIP) is trained to match images with text descriptions.
Two kinds of prompts they learn
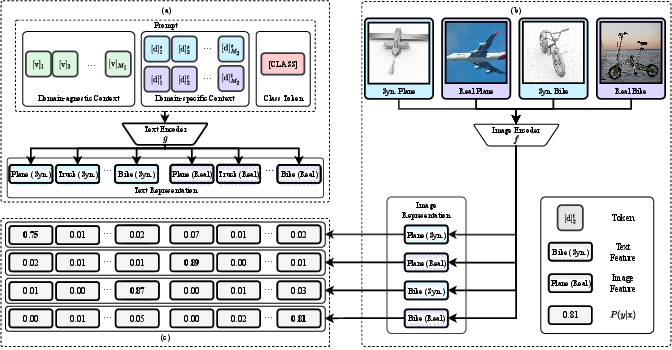
Instead of using only a single, generic prompt, the authors create a prompt with two parts:
- Domain-agnostic context: words that work across all domains (general task information).
- Domain-specific context: words that describe the domain (like “sketch” or “product”), tuned separately for each domain.
Together with the class name, the prompt might act like: “an image of a [domain info] [CLASS]”. The important part is that the domain-specific part changes depending on whether the image is a photo, a sketch, or a product image.
Training: a matching game
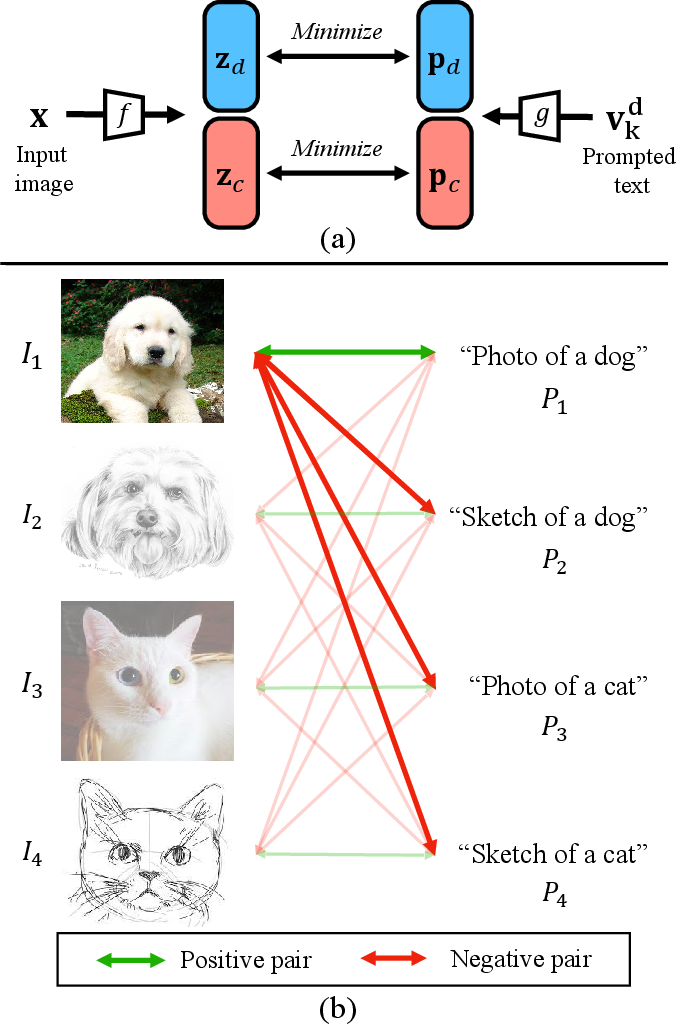
The model has two encoders:
- An image encoder turns pictures into vectors (think of them as arrows pointing in certain directions).
- A text encoder turns prompts into vectors.
The goal is to:
- Pull matching image–text pairs closer together (same domain and same class).
- Push non-matching pairs apart (different domain or different class).
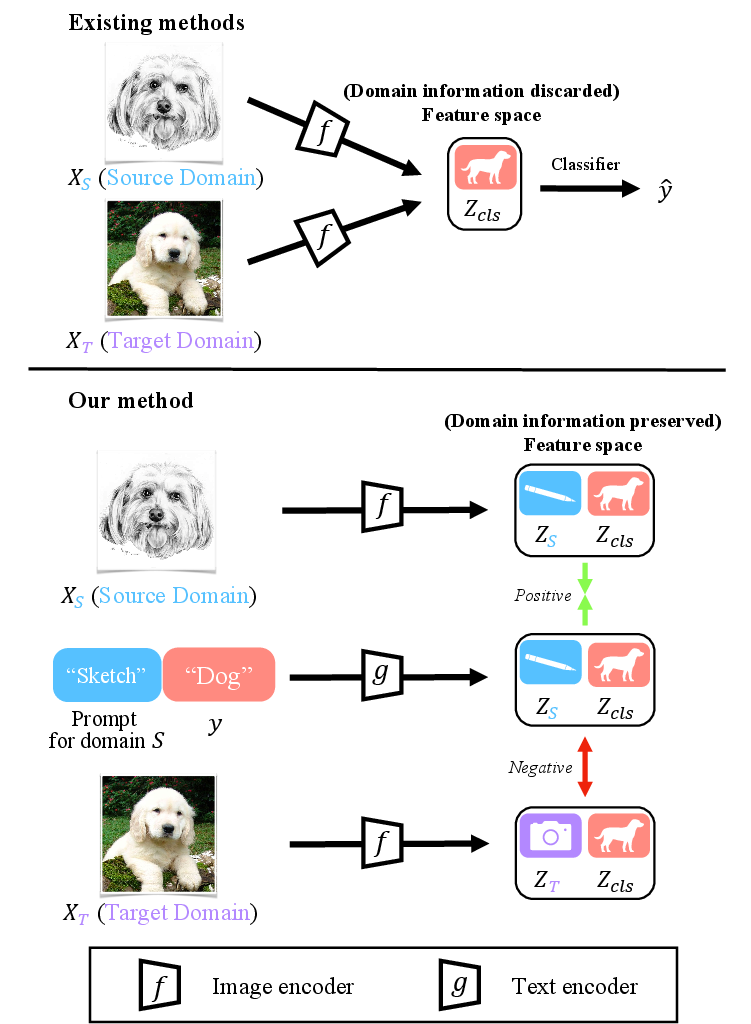
This “contrastive learning” is like a memory game: match the right pairs and separate the wrong ones. It helps the model learn to separate “what is the object” (class) from “how it looks” (domain style).
Using unlabeled data with “pseudo labels”
Because target images don’t have labels, the model guesses the most likely class (a “pseudo label”) when it’s confident enough. It only trains on these guesses if its confidence passes a threshold, so it avoids learning from bad guesses.
Why this avoids hurting category understanding
Many older methods try to make source and target features look the same. That can blur useful details and hurt class recognition. Here, the model doesn’t force everything to align. Instead, it keeps domain info in the prompt, so it can adapt per domain while preserving clear, category-specific understanding.
Main Findings
- Strong performance on standard benchmarks:
- Office-Home: average accuracy of about 74.5%, better than prior methods.
- VisDA-2017 (synthetic-to-real): average accuracy of about 86.9%, also better than prior methods.
- Improves over a strong baseline (zero-shot CLIP) by about 2.5% on both benchmarks.
- Efficient training: they only tune the small prompt parameters, not the whole model, making it fast and easy to implement.
- Clearer predictions: adding domain-specific prompt information increases the model’s confidence and accuracy, especially in tricky categories like “knife”, “person”, and “plant”.
Why It Matters
- Less labeling work: You can adapt a model to new kinds of images without collecting and labeling tons of data.
- Better accuracy without “feature alignment” side effects: By keeping domain information in prompts, the model avoids breaking its understanding of object categories.
- Simple and fast: You only tweak a small number of prompt parameters, so it’s practical and cost-effective.
- Flexible foundation: This idea can be expanded to other tasks like semantic segmentation, making vision models more adaptable to real-world variation (different cameras, styles, or environments).
In short, using learned prompts that include domain information helps the model recognize objects more reliably across different styles of images, with minimal extra training and without harming its understanding of what things are.
Collections
Sign up for free to add this paper to one or more collections.

