- The paper introduces a scalable method using large language models that predict human similarity judgments from linguistic descriptors.
- It employs CNNB and BERT embeddings with a linear transformation, achieving superior predictive performance measured by Pearson R² scores.
- The approach minimizes data requirements compared to traditional pairwise comparisons, offering cross-domain applications in psychology and machine learning.
Predicting Human Similarity Judgments Using LLMs
The paper explores a novel methodology for predicting human similarity judgments through LLMs, transcending traditional approaches based on visual comparisons. This paper leverages linguistic descriptors and recent advancements in LLMs to efficiently approximate similarity judgments, thereby addressing the scalability limitations of conventional methods like multi-dimensional scaling (MDS).
Introduction
The research addresses the complex problem of deriving human similarity judgments, which traditionally demands extensive pairwise comparisons, growing quadratically with stimuli count. The proposed method leverages LLMs and linguistic similarities, establishing a scalable, domain-general framework that significantly reduces data requirements. Crucially, the paper contends that linguistic similarity traces human cognitive processes accurately, offering a robust alternative to visual data-driven models such as those using CNNs.
Methodology
The researchers employ a multi-step procedure to predict similarity. Initially, pre-existing semantic labels and newly crowd-sourced text descriptions serve as stimuli representations. Embedding models, specifically ConceptNet NumberBatch (CNNB) and BERT, are employed to compute vector representations of these linguistic descriptors. Cosine similarity of these vectors serves as the prediction metric for pairwise similarity judgments. The linear transformation approach enhances the embeddings' predictive accuracy, utilizing ridge regression to manage potential overfitting through a cross-validation strategy.
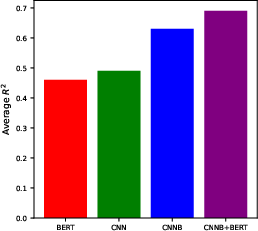
Figure 1: Average CCV R2 score for the main four models considered.
Stimuli and Representations
Six datasets comprising diverse categories were utilized to validate the approach. Initial investigations employed semantic labels within one-hot and CNNB embeddings. While one-hot representations provided basic predictive power, CNNB embeddings demonstrated improved accuracy, capturing nuanced semantic similarities ignored by category labels alone.
Results and Evaluation
The combined use of CNNB and BERT enhanced predictive performance, showcasing an ability to generalize across domains with R2 scores outperforming previous CNN-based studies on most datasets. BERT captured sentence-level semantics from free-text descriptions, while CNNB tapped into broader, concept-level relations, demonstrating complementary strengths in capturing human similarity perceptions. The evaluation of models was focused on Pearson R2 scores, with linearly transformed versions showing more robust predictions, validated through cross-validated testing on held-out data.

Figure 2: Examples of image pairs that generated large discrepancies between CNN and CNNB model predictions and their relation to human similarity scores.
Implications and Future Directions
The implications of this research are multifaceted, impacting both psychological studies and machine learning applications. The methodology offers scalable opportunities to explore similarity in any domain where linguistic descriptions are accessible, such as audio and video. In psychology, this framework could illuminate the disparity between perceptual and semantic similarity across different expertise levels, aiding in the understanding of semantic development trajectories. Furthermore, enhancing machine learning datasets with such similarity-based enrichments can improve model robustness and alignment with human cognition.
Conclusion
This study presents a domain-general, scalable approach to predicting human similarity judgments using LLMs and linguistic representations. By illustrating that semantic similarity mirrors human cognitive processing efficiently, this method provides a promising pathway for future research in both behavioral sciences and computational applications. Future work should explore multi-modal integration, potentially enhancing the model's precision by unifying visual and semantic cues through advanced transformer architectures.

