- The paper presents a novel multiagent approach combining a polling-based coordinating agent with RL-based trajectory control to schedule vehicles dynamically.
- The methodology leverages multi-discount Q-learning to balance short-term collision avoidance with long-term path optimization, significantly reducing computational complexity.
- Empirical results demonstrate near-optimal performance and reduced travel times in multi-lane intersections, validating the framework's real-time feasibility and safety.
Intelligent Autonomous Intersection Management
The paper "Intelligent Autonomous Intersection Management" addresses the real-time management of connected autonomous vehicles (CAVs) through intersections, replacing traditional traffic signals. It proposes an efficient, deployable, multiagent architecture based on reinforcement learning (RL) and a novel algorithm named multi-discount Q-learning. This approach tackles the complexity of managing real-time autonomous traffic, accounting for both long-term trajectory planning and short-term dynamic adjustments necessary for collision-free operation.
Autonomous Intersection Management Challenges
Autonomous Intersection Management (AIM) aims to exploit the capabilities of CAVs to improve traffic flow through intersections better than traditional methods. Most existing AIM strategies rely on knowing vehicles' arrival times in advance, which limits their real-world applicability as real-time conditions are often stochastic. The computational complexity inherent in solving these scheduling and trajectory optimization problems has traditionally necessitated expensive linear programming (LP) approaches, which are impractical for real-time deployment.
Proposed Solution
Multiagent System Design
The proposed system consists of two key agent types:
- Polling-based Coordinating Agent: This agent formulates a time schedule for each vehicle entering the intersection's control region. It applies a novel polling algorithm that adapts to the complexity of multi-lane intersections with multiple turning directions by managing scheduling in a computationally efficient manner.
- RL-based Trajectory Control Agents: Assigned to individual vehicles, these agents determine the optimal trajectory to reach the intersection at the scheduled time while maximizing velocity. The distributed architecture allows these agents to operate independently while adhering to the overall AIM policy set by the coordinating agent.
Multi-Lane Polling System
The multi-lane polling system extends traditional single-lane approaches by representing each lane as a queue and employing queue-dependent transition functions to manage service and switch-over times. This method generalizes to real-world intersections with multiple directions and ensures non-conflicting time schedules for vehicles.
Novel Multi-Discount Q-learning
To tackle challenges posed by tasks with both short-term safety and long-term scheduling objectives, the authors introduce multi-discount Q-learning. This algorithm uses a discount vector to differentiate between short and long temporal horizons, enabling simultaneous optimization of different objectives. The adaptive discounting is managed via a reward-dependent discount function, which is crucial for preserving the temporal integrity of each sub-task in the decision-making process.
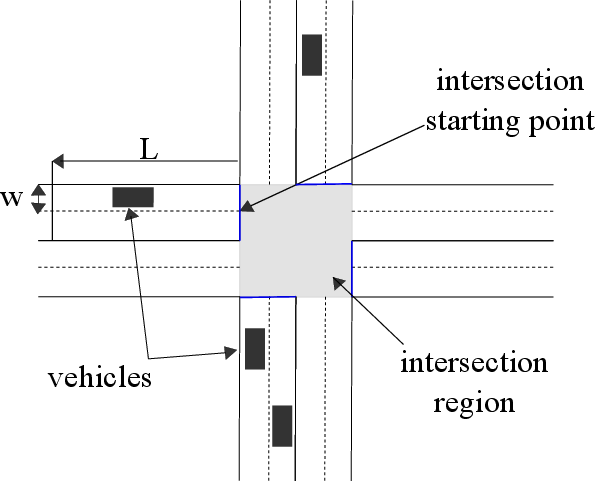
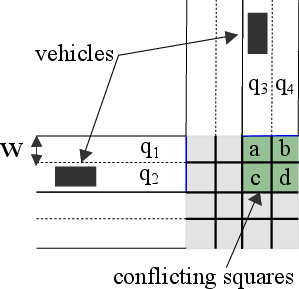
Figure 1: A four legged intersection with vehicles represented with black rectangles. The control region for one road segment is shown with length L. The intersection region is shown in gray and the intersection starting point for road segments are shown in blue lines.
Empirical Evaluation
Experimental Setup
- VE-setup: Focuses on testing individual vehicle trajectories against baselines using an RL-based agent and optimal LP models.
- IE-setup: Tests full intersection management with stochastically arriving vehicles, simulating real-world traffic patterns.
Results
- Trajectory Optimization: Multi-discount Q-learning achieves near-optimal trajectory performance comparable to LP solutions but with significantly lower computational time and complexity, ensuring feasibility for real-time application.
- Intersection Management Performance: The proposed I-AIM framework demonstrates reduced average travel times compared to traditional methods, even under varying traffic conditions. Most notably, the RL-based solution incurs no scheduling deviations, underscoring its safety and reliability advantages over heuristic or LP-based approaches.
Conclusions
The integration of RL with novel algorithmic enhancements presents a feasible, real-time solution to AIM, achieving efficiency across typical urban traffic conditions. The proposed multi-discount approach shows potential applications in diverse areas where tasks comprise objectives with differing temporal scopes, notably in robotics and broader autonomous systems. Future work may extend this framework to coordinate multiple intersections concurrently and evaluate broader urban networks. Such advancements could further harness the potential of AIM to meet evolving urban mobility demands.