- The paper reveals that traditional ratio clipping in PPO does not effectively bound policy changes and may be unnecessary for optimal performance.
- The work introduces Early Stopping Policy Optimization (ESPO), which replaces clipping with a mechanism that halts policy updates based on deviation thresholds.
- ESPO outperforms conventional PPO variants on high-dimensional tasks, showing improved scalability and robustness in empirical evaluations.
You May Not Need Ratio Clipping in PPO
Introduction
The paper addresses the commonly used technique of ratio clipping in Proximal Policy Optimization (PPO) and posits that such clipping is not essential for optimal performance. PPO typically involves optimizing a surrogate objective iteratively over multiple epochs within a single data sampling phase. The prevalent belief, grounded in existing research, maintains that ratio clipping is vital as it ostensibly ensures bounded likelihood ratios, providing a conservative estimate of objective function improvements. However, the authors reveal that in practice, ratio clipping fails to maintain boundedness effectively and may not be as critical as previously assumed.
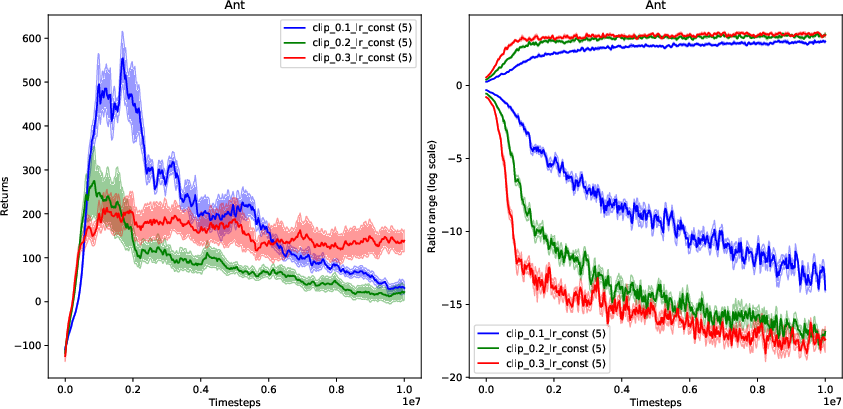
Figure 1: Empirical returns and ratio ranges (log scale) of RC-PPO trained on Ant-v2 (with constant learning rate 0.0003).
Theoretical Analysis
The paper explores theoretical implications by challenging the assumption that ratio clipping enforces a bounded change in policy as PPO progresses through multiple optimization epochs. The authors question the implicit enforcement of a trust region constraint traditionally associated with monotonic policy improvement guarantees. They demonstrate that even with ratio clipping, it is possible for policy ratios to exceed the boundaries, leading to ineffective bounding of the total variation divergence (Figure 1). This realization leads to the development of the Early Stopping Policy Optimization (ESPO) algorithm, which dispenses with clipping in favor of a robust early stopping criterion based on ratio deviation.
Methodology: Early Stopping Policy Optimization (ESPO)
ESPO replaces ratio clipping by monitoring the degree of policy update through expected ratio deviations. The theoretical foundation suggests that bounding the expected absolute deviation of the probability ratios effectively contributes to the policy improvement guarantee while allowing larger and more informed policy updates. ESPO achieves superior empirical performance across various high-dimensional control tasks by dynamically determining the point to terminate optimization epochs based on deviation thresholds.
Figure 2: ESPO performance against ratio clipping PPO, PPO-KLES, and TRPO on Mujoco benchmark tasks.
Results and Empirical Validation
Extensive experiments on Mujoco and DeepMind control suite tasks demonstrate ESPO's efficiency. ESPO consistently outperforms standard PPO with clipping and its variant with KL-based early stopping (PPO-KLES). Notably, ESPO shows resilience and performance gains in high-dimensional tasks such as Humanoid and HumanoidStandup, where traditional PPO variants falter (Figure 2). Moreover, ESPO's performance slightly edges out in distributed settings, ensuring scalability and robust policy optimization with multiple workers, evidenced by its competitive results against Distributed PPO (Figure 3).

Figure 3: ESPO performance against ratio clipping PPO, PPO-KLES and TRPO on high dimensional DeepMind control tasks.
Conclusion
In conclusion, the research highlights a pivotal shift in understanding PPO optimizations by eliminating the arguably redundant ratio clipping process. By shifting focus to early stopping mechanisms that rely on real-time ratio deviations, ESPO offers a more reliable and theoretically appealing alternative that enhances PPO's performance across varied environments. The study provides compelling evidence for re-evaluating established reinforcement learning methodologies, suggesting further exploration into alternate regularization and optimization frameworks. This work opens up new avenues for algorithmic refinement in reinforcement learning, promoting more efficient and adaptive learning systems.

