- The paper introduces AIS as a framework to assess whether NLG outputs are verifiable against external sources, reducing hallucination risks.
- It employs a two-stage, human-annotated pipeline that separately evaluates interpretability and source attribution across varied NLG tasks.
- The study highlights challenges such as multi-hop reasoning and annotator variance, while suggesting improvements for automated attribution checks.
Measuring Attribution in Natural Language Generation Models
The paper introduces a framework called Attributable to Identified Sources (AIS), designed to assess whether the output of natural language generation (NLG) models reflects verifiable information from external sources. This evaluation framework is crucial given the propensity for generative models to produce hallucinated content not backed by reference documents.
Introduction to AIS
The paper presents AIS as a solution to measure attribution, focusing on the relationship between generated responses and their sources. The framework involves defining when a statement can be considered attributable to identified sources, using a two-stage annotation pipeline where human evaluators first rate interpretability and then attribution independently.
Defining Attribution
The formal definition of AIS revolves around whether a stand-alone proposition, when paired with its context, can be genuinely affirmed as being derived from specified parts of a given source corpus. This determination is accomplished using explicatures—a concept used to unravel the meaning of a sentence in its context to ensure faithful representation of source material.
Evaluation through Human Studies
The paper validates the AIS framework by conducting human evaluation studies on datasets from diverse NLG tasks (conversational QA, text summarization, and table-to-text generation). These studies illustrate that AIS can serve as a common metric for assessing whether NLG outputs are substantiated by underlying documents.
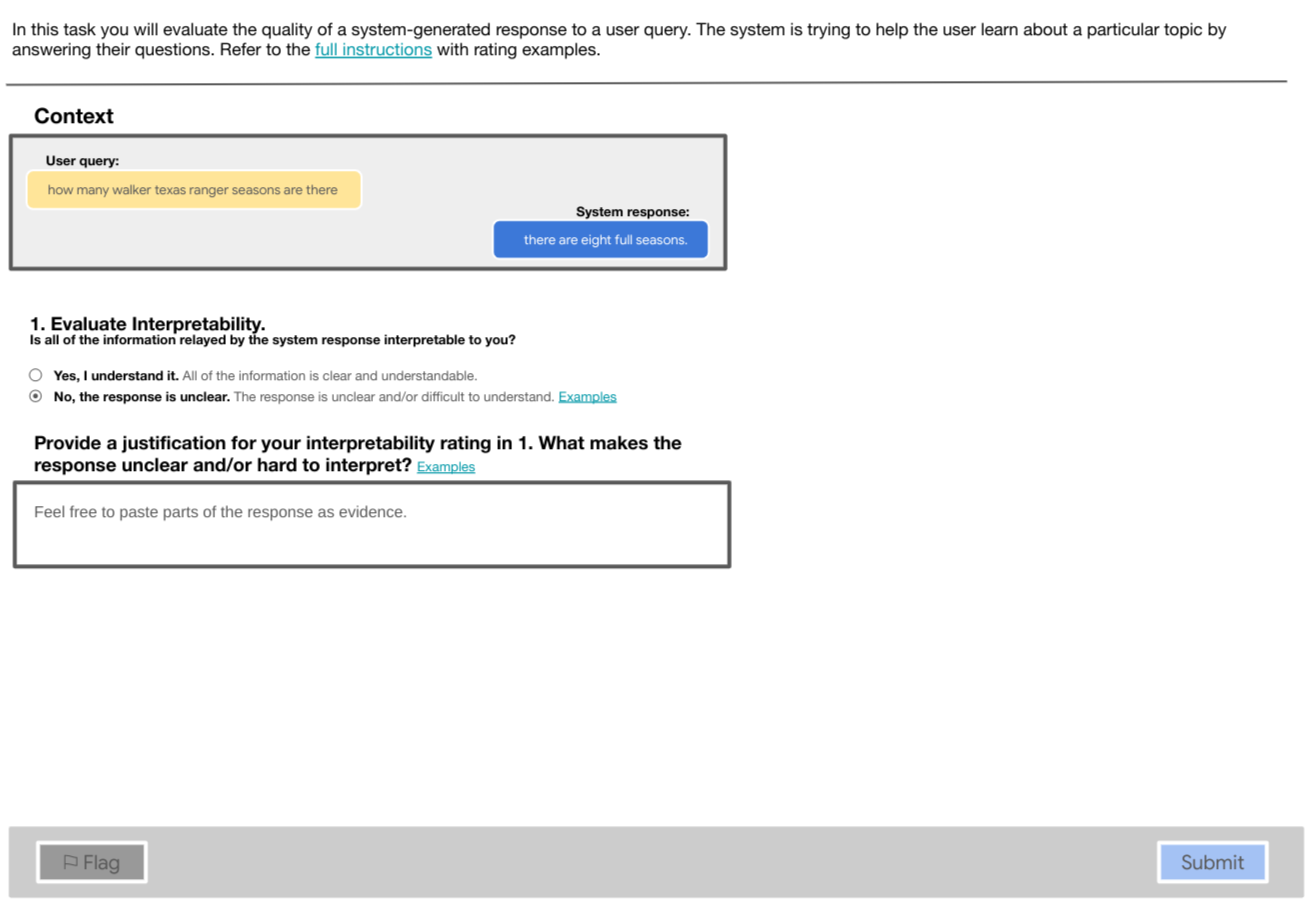
Figure 1: Interpretability stage. The source document is hidden. If the task is rated as not interpretable, the attribution stage is skipped and the annotator proceeds to the next task in the queue. During training and pilot, the justification element is shown only if the task is rated as not interpretable.
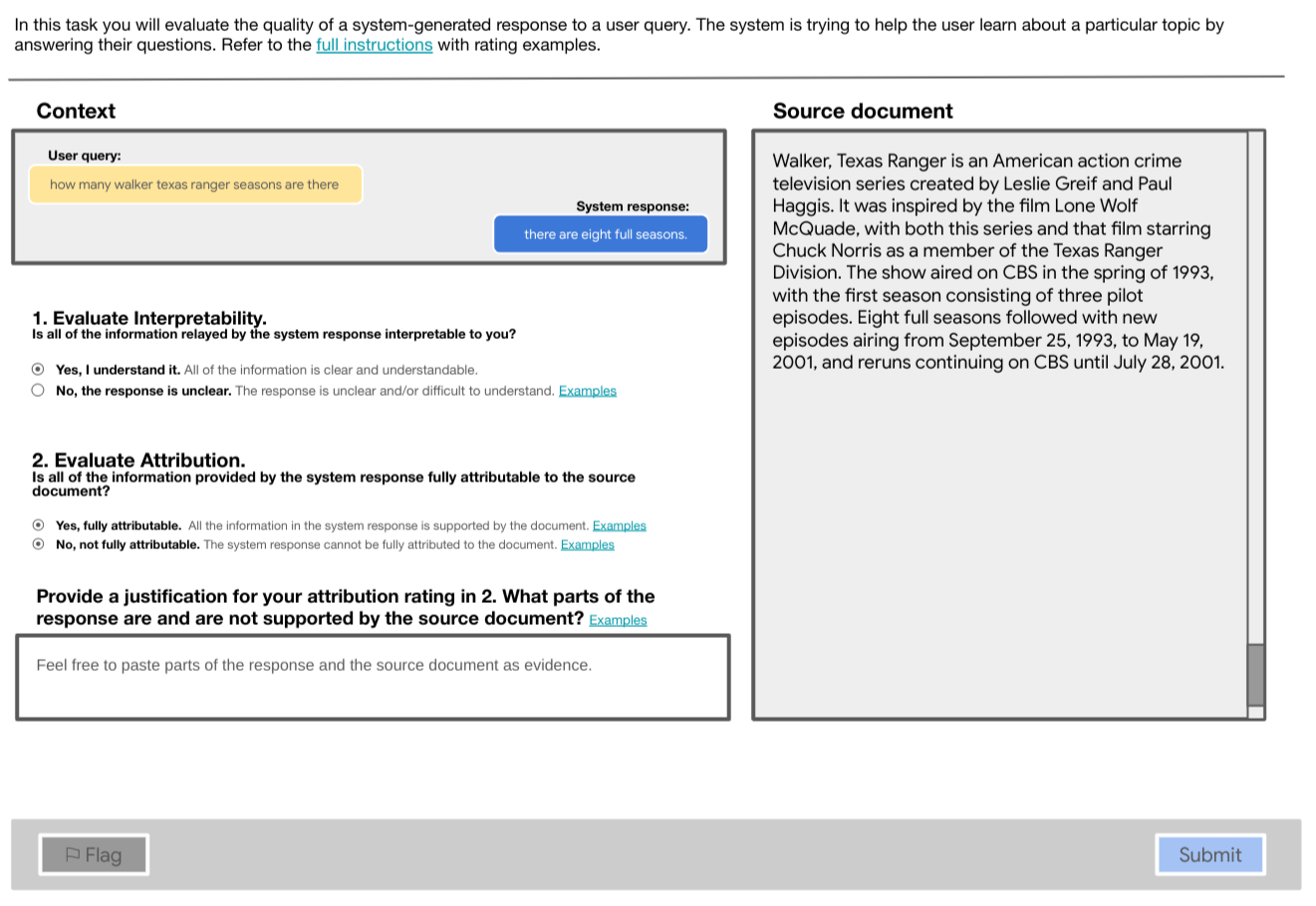
Figure 2: Attribution stage. The source document is shown. During training and pilot, the justification element is required for all ratings.
Challenges and Considerations
Several challenges arise in evaluating AIS, including the need for common sense reasoning, handling of implicit information, and annotator agreement. For example, multi-hop reasoning or cross-domain knowledge may be necessary to align generated text with references accurately. The study also acknowledges limitations, such as varying degrees of familiarity among annotators impacting agreement rates.
Implications and Future Directions
The paper highlights that establishing attribution is crucial for maintaining the reliability and trustworthiness of AI systems in real-world applications. The paper discusses the need for ongoing research to refine AIS evaluations further, particularly regarding improving automated attribution checks and expanding the AIS framework to include non-declarative texts or mixed-purpose outputs.
In conclusion, this paper presents AIS as a pioneering framework to systematically measure the attribution quality of NLG models, promising a standardized approach that can be adapted across various applications in the field of natural language processing.

