- The paper introduces BANMo, a framework for reconstructing animatable 3D models from casual videos without requiring advanced equipment.
- It employs a fusion of NeRF-based canonical shape modeling, neural blend skinning, and self-supervised canonical embeddings for pixel registration.
- Experimental results demonstrate improved 3D reconstruction fidelity and scalability compared to prior methods like Nerfies, with applications in motion retargeting.
Building Animatable 3D Neural Models from Many Casual Videos
Introduction
The paper "BANMo: Building Animatable 3D Neural Models from Many Casual Videos" addresses the challenge of reconstructing high-fidelity, articulated 3D models from sets of casual RGB videos without relying on specialized equipment or pre-defined templates. BANMo merges techniques from deformable shape models, canonical embeddings, and volumetric NeRFs to achieve this, enabling realistic rendering and animation from multiple casual video sources.
Method Overview
BANMo constructs 3D models using three primary components:
- Canonical Shape Model: Utilizing Neural Radiance Fields (NeRF), 3D points in a canonical space are predicted with properties like color, density, and embeddings. This framework handles appearance variations and establishes dense correspondences across multiple video sources.
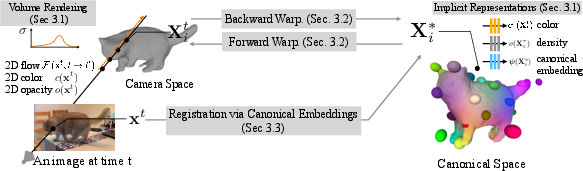
Figure 1: Method overview. BANMo optimizes a set of shape and deformation parameters that describe the video observations in pixel colors, silhouettes, optical flow, and higher-order feature descriptors, based on a differentiable volume rendering framework.
- Neural Blend Skinning Model: The deformation of the object is modeled through neural blend skinning. This method manages large-scale deformations without requiring predefined skeletons, effectively mapping and inverting between canonical and camera spaces.
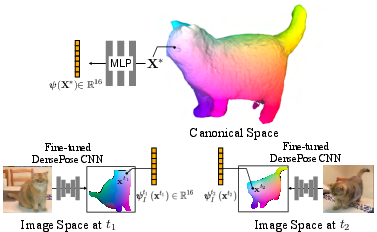
Figure 2: Canonical Embeddings. Jointly optimize an implicit function to produce canonical embeddings from 3D canonical points that match to the 2D DensePose CSE embeddings.
- Registration via Canonical Embeddings: BANMo leverages a feature-matching mechanism across 2D video frames to ensure coherent registration of pixels. This method achieves dense correspondence through self-supervised canonical embedding learning.
Losses and Optimization
The BANMo framework is trained by minimizing a comprehensive suite of losses:
- Reconstruction Losses: Compare rendered images to actual video observations, including RGB, silhouettes, and optical flow.
- Feature Registration Losses: Enforce consistency between feature matching and geometric warping.
- Cycle Consistency Losses: Regularize both 2D feature projections and 3D point transformations to maintain coherent reconstruction fidelity.
Experimental Results
Qualitative results show BANMo's superiority in reconstructing articulated shapes compared to ViSER and Nerfies, producing high-fidelity geometrical details like animal limbs and facial features. BANMo demonstrates improved scalability and accuracy with increased video input, unlike Nerfies, which struggles with large motion and registration.
Quantitative evaluations illustrate BANMo's efficacy in achieving lower 3D Chamfer distances and higher F-scores across diverse datasets, including the AMA dataset and various animated objects.

Figure 3: Qualitative comparison of our method with prior art.
Diagnostics and Ablation
BANMo's reliance on root pose initialization is critical for stabilization during optimization. Canonical embeddings significantly aid video registration, preventing artifacts such as ghosting without them. The neural blend skinning model proves essential for managing complex deformations, revealed through experiments with dynamic objects, such as eagles.
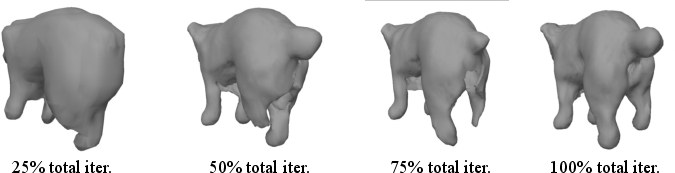
Figure 4: Compliance to topology changes in optimization. Improper reconstructions are automatically corrected via gradient updates.
Applications and Future Work
BANMo's capabilities extend to novel applications like motion retargeting, where pre-optimized models can mimic motions from unrelated video sources. The paper suggests the potential for general pipelines requiring further advancement in pose estimation completeness and computational efficiency.
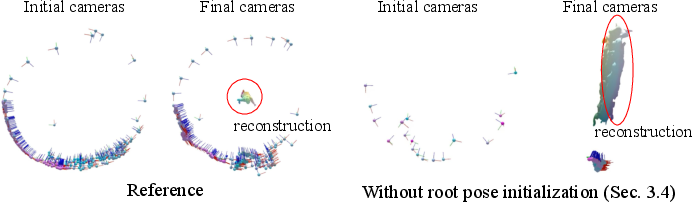
Figure 5: Motion re-targeting from a pre-optimized cat model to a tiger.
Conclusion
BANMo represents a significant advancement in the field of 3D model reconstruction from casual video sources, merging cutting-edge techniques for comprehensive high-fidelity, animatable models. While challenges in compute efficiency and reliance on pre-trained pose estimation models persist, BANMo establishes a promising foundation for future work in video-based 3D model generation.