- The paper presents a detailed history of tokenization techniques, highlighting the transition from word-based methods to advanced subword modeling.
- It explains how methods such as BPE and Unigram models optimize vocabulary size and boost NLP performance in morphologically diverse languages.
- The study discusses practical implications and future prospects, including integrating linguistic and probabilistic approaches for improved model robustness.
A Brief History of Open-Vocabulary Modeling and Tokenization in NLP
Introduction to Tokenization in NLP
In the domain of NLP, tokenization refers to the process of splitting text into smaller units called tokens. Traditionally, this has been achieved by treating words as discrete and atomic units, closely aligned with linguistic constructs like word forms. However, the advent of byte-pair encoding (BPE) and subword tokenization has shifted the standard practice in NLP, allowing models to handle languages with open vocabularies more effectively. This shift emphasizes processing at subword levels, which balances vocabulary size and model inference speed.
Fundamental Concepts: Tokens and Subwords
Historically, NLP models tokenized text based on typographic units or pre-tokenizers, such as spaces in English text. This method, however, faced challenges in handling complex language phenomena such as contractions, compounds, and other linguistic nuances that deviate from simple space-separated word forms. Recent evolutions in tokenization advocate for the use of subword units that provide a better compromise between character-level processing and traditional word-based methods. These approaches have improved model robustness against rare and novel words by employing character information to enhance word embeddings and introduce open-vocabulary models without fixed-size vocabularies.
Evolution of Tokenization Techniques
Initially, NLP models relied heavily on deterministic tokenizers, such as those rooted in finite-state transducers and morphological analyzers. These tokenizers were developed to approximate linguistic units. However, the rise of subword tokenization methods, like BPE and WordPiece, marks a significant transition. BPE iteratively merges frequently co-occurring subword units to maintain model efficiency with a manageable vocabulary size.
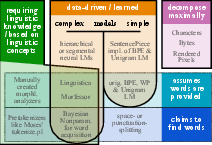
Figure 1: A taxonomy of segmentation and tokenization algorithms and research directions.
In addition, techniques such as Unigram LLMs have emerged, augmenting tokenization with probabilistic approaches that allow models to sample segmentations from a distribution, thereby enhancing linguistic diversity and transfer capabilities in multilingual settings.
Practical and Theoretical Implications
The theoretical implications of these tokenization advancements are profound, as they suggest that there is no singular optimal tokenization strategy for all NLP applications. Instead, tokenization must be carefully tailored to the task and domain, often requiring bespoke engineering efforts. Practically, these approaches have led to significant improvements in NLP tasks, including language modeling and machine translation, particularly for languages with rich morphological features or those lacking explicit word boundaries.
Future Prospects and Conclusion
The future developments in tokenization are likely to explore deeper integration of linguistic and statistical methods, potentially incorporating features like sub-character and visual tokenization, which utilize pixel-level representations for robustness against orthographic variations. Advances like CANINE and ByT5 demonstrate the feasibility of bypassing traditional tokenization altogether, although they still face challenges concerning computational efficiency and interpretability.
In conclusion, while tokenization remains an unresolved and complex facet of NLP, continuous research and innovation promise to refine and optimize these processes further, potentially revisiting linguistically informed methods when combined with modern computational techniques. As the field progresses, it is crucial to maintain a flexible approach that considers linguistic, computational, and practical aspects of tokenization.

