- The paper proposes SMPPI by integrating input-lifting and an action cost to suppress chattering without external smoothing filters.
- It demonstrates superior performance over standard MPPI in both pendulum swing-up tasks and high-speed autonomous driving, achieving faster lap times and reduced sideslip.
- The method maintains MPPI’s theoretical foundations while enabling responsive, robust control in nonlinear, non-affine dynamic environments.
Smooth Model Predictive Path Integral Control without Smoothing
Overview
The paper "Smooth Model Predictive Path Integral Control without Smoothing" (2112.09988) presents an advanced methodology for generating smooth control inputs in nonlinear systems using a modified Model Predictive Path Integral (MPPI) framework. Unlike conventional approaches that address action chattering via external smoothing filters, this work integrates an input-lifting strategy and an action sequence cost directly into the MPPI optimization, circumventing the loss of optimality induced by post-hoc smoothing. The technique maintains the theoretical underpinnings of MPPI—particularly its information-theoretic interpretation and applicability to non-affine dynamics—while enabling both responsiveness to sharply changing environments and the reduction of high-frequency noise in actuator commands.
Limitations of Standard MPPI and Smoothing Algorithms
The inherent stochastic sampling process in MPPI often introduces considerable chattering in control commands, which proves detrimental for real-world robotic and autonomous systems requiring stability and actuator longevity. Traditional remedies include employing filters such as Savitzky-Golay, either on the noise sequence or after control sequence updating. However, these external smoothing procedures are decoupled from the control optimization process (Figure 1), risking constraint violations, phase distortion, delayed system response, and divergence, particularly when operating in rapidly changing dynamic regimes.
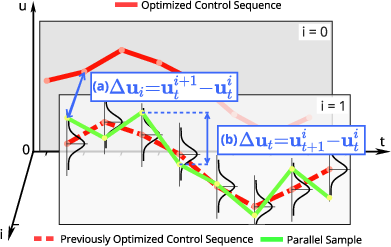
Figure 1: The MPPI optimization iteration highlights how sampled trajectories (green) exhibit abrupt control changes both between iterations (i-axis) and during rollouts (t-axis), challenging smoothness in the baseline algorithm.
The proposed Smooth Model Predictive Path Integral (SMPPI) control method fundamentally reparameterizes the control optimization problem. By lifting the control variables into their temporal derivatives, the action space and control space are decoupled. Sampling occurs over the higher-order control space, producing action sequences via integration, naturally suppressing chattering along both the optimization axis ("i-axis") and trajectory axis ("t-axis").
An additional action cost Ω(A) penalizes high variation in the control actions within the state cost, thereby discouraging erratic action profiles without violating MPPI's statistical foundations:
Ω(A)=t=1∑T−1(at−at−1)⊤ω(at−at−1)
The control update is thus realized as:
Uti+1=Uti+k=0∑K−1w(Ek)ϵtk
Ati+1=Ati+Uti+1Δt
This mechanism achieves bidirectional smoothing—responsivity remains unimpaired, while both discrete jumps in control commands within iterations and rollouts are penalized in a principled manner.
Empirical Evaluation: Pendulum and Autonomous Driving
Pendulum Swing-Up Task
In a neural network-modeled nonlinear pendulum, SMPPI was benchmarked against standard MPPI, variants with action cost smoothing, and externally filtered controllers. SMPPI consistently achieved stabilization for all initial velocities, demonstrating the unique capability to track rapidly shifting optimal distributions and deliver sufficient torque for swing-up (Figure 2). Competing methods failed to converge, primarily due to the inability to reconcile chattering and optimality.
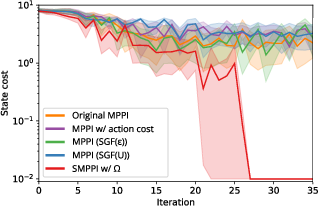
Figure 2: Log-scaled state cost trajectories reveal superior convergence of SMPPI versus unmodified or externally smoothed MPPI controllers.
Autonomous Vehicle Control
Vehicle Model and Training
A feedforward neural network (four hidden layers, ReLU activations) was trained on diverse driving maneuvers, featuring explicit modeling of frictional dynamics and automatic gear shifting (Figure 3). Validation RMSEs for vx, vy, and r were all below $0.03$, enabling model-based controllers to operate reliably in variable conditions.
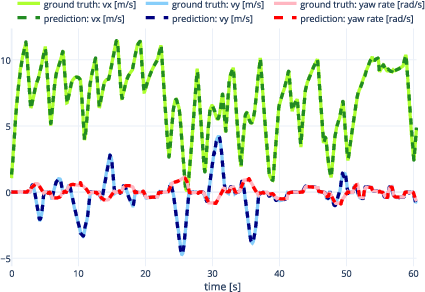
Figure 3: The neural network estimator accurately reproduces validation trajectories across modified friction coefficients.
High-Speed Maneuvering on Race Track
SMPPI was deployed in a simulated Volvo XC90, tasked with traversing a complex race track under variable friction coefficients at reference speeds up to $60$ km/h. Results indicated that standard MPPI, with or without external smoothing, failed catastrophically at sharp corners—either losing control or diverging, especially evident in trajectory visualizations (Figure 4).
In contrast, SMPPI, especially when equipped with an action cost Ω, completed all laps at higher speeds, exhibiting both lower lap times and reduced sideslip angles. This demonstrates robust, agile control with minimal chattering, outperforming the filtered baselines in noisy, unstable regimes.
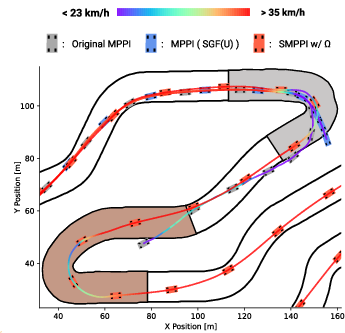
Figure 4: SMPPI achieves stable, high-speed trajectories (purple) in challenging corners where baseline controllers fail due to chattering and instability.
The effectiveness of SMPPI in suppressing chattering is further illustrated in steering command sequence analyses (Figure 5), where both noise and action integration profiles remain smooth without external intervention, and applied commands exhibit actuator-friendly transitions.
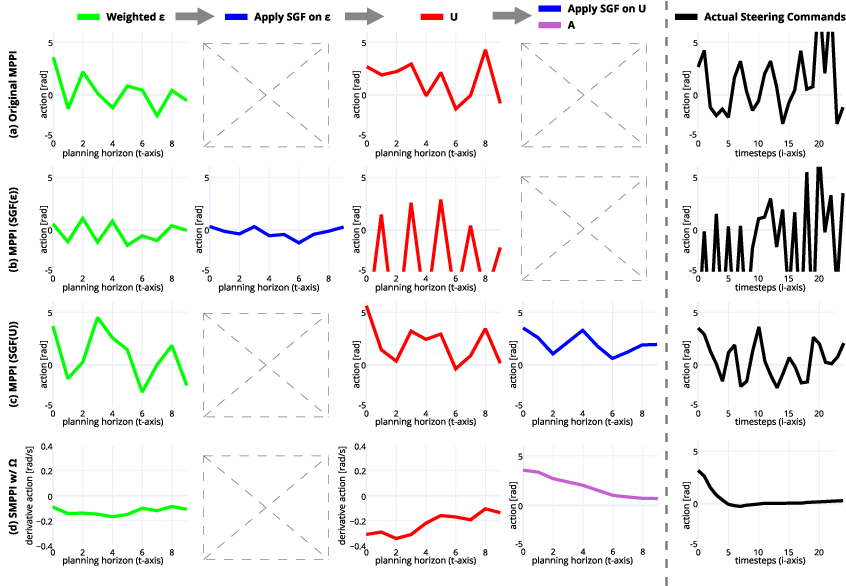
Figure 5: Controller command sequences after a sharp corner show SMPPI yielding smooth, phase-stable steering compared to divergent and delayed filtered MPPI baselines.
Implications and Future Directions
SMPPI offers a refined paradigm for sampling-based optimal control in real-world nonlinear systems. By lifting controls and integrating action variation costs within the optimization, it addresses the longstanding trade-off between agility and smoothness in MPPI algorithms, especially for systems with non-affine dynamics. The findings suggest immediate applicability for high-speed autonomous vehicle navigation, robotic manipulators, and complex field robots subject to actuator constraints.
Practical extensions include real-time implementation in embedded systems, online adaptation of smoothing weights, and further generalization to underactuated and hybrid dynamical models. The removal of post-processing filters is likely to facilitate hardware deployment and ease controller tuning, with broader theoretical implications for information-theoretic control and sampling-based planning.
Conclusion
This work formulates a comprehensive solution to chattering in MPPI by integrating control derivatives and action costs directly into the sampling and optimization paradigm. Extensive validation in both classical control and high-fidelity autonomous driving simulations demonstrates superior stability and agility, without recourse to external smoothing. SMPPI thus represents a significant contribution toward robust, smooth optimal control in dynamic, uncertain, and highly nonlinear environments.