- The paper introduces a scalable masked autoencoder framework that leverages Vision Transformers to efficiently learn feature representations via high masking.
- It employs an asymmetric encoder-decoder architecture where the encoder processes unmasked image patches while a lightweight decoder reconstructs full images.
- Experiments demonstrate state-of-the-art performance on ImageNet and competitive results in tasks like object detection and semantic segmentation.
Masked Autoencoders Are Scalable Vision Learners
The paper "Masked Autoencoders Are Scalable Vision Learners" (2111.06377) introduces Masked Autoencoders (MAE) as a scalable approach to self-supervised learning in computer vision. Leveraging the architectural strength of Vision Transformers (ViT), the paper covers technical strategies for impactful implementation and outlines the benefits of MAEs in vision tasks through empirical evaluations.
Asymmetric Encoder-Decoder Architecture
The proposed MAE framework employs an asymmetric encoder-decoder architecture. The encoder processes only a visible subset of unmasked image patches, avoiding the computational burden of handling masked tokens. This reduces the overall computational expense significantly for large datasets.
- Encoder: Utilizes a ViT that processes a fraction of the image patches, optimizing computational efficiency.
- Decoder: Reconstructs the image from the latent representation and mask tokens, applying fewer resources due to its lightweight design.
This architecture allows the encoder to focus on relevant information, yielding an efficient training process with up to 3x speedup while enabling scalability to substantial model sizes. The experimental results state that a high masking ratio (e.g., 75%) is optimal for the proposed MAE approach, providing challenging predictive tasks that enhance feature learning.
(Figure 1)
Figure 1: The MAE architecture involves masking a significant portion of image patches, with the encoder processing visible ones and a lightweight decoder reconstructing the complete input.
Image Reconstruction and Pre-Training
The methodology capitalizes on predicting missing pixel patches in the image space, distinguishing it from natural language processing tasks that rely on reconstructing tokens. This pixel-level reconstruction necessitates handling a diverse range of image structures.
- Masking Strategy: Randomly samples and masks 75% of image patches, significantly reducing spatial redundancy, thus improving the pre-training task's effectiveness.
- Optimization: The encoder solely processes unmasked patches, while the decoder predicts entire patches, resulting in efficient pre-training.
Key results include a pre-trained ViT-Huge that achieves 87.8% accuracy on ImageNet-1K, surpassing prior methods that only use this dataset. Additionally, the paper reports successful applications across tasks such as object detection and semantic segmentation, demonstrating competitive transfer learning results.
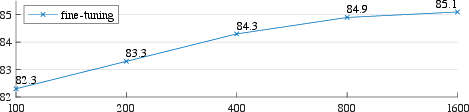
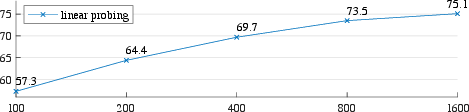
Figure 2: Training schedules for different MAE configurations show improvements with extended schedules, reflecting better pre-training outcomes.
Comparison with Existing Techniques
MAE is compared with other state-of-the-art self-supervised and supervised learning models, illustrating advantages like enhanced accuracy with increasing model sizes. This emphasizes the robustness and adaptability of MAE in scaling deep models, using datasets like COCO and ADE20K for validation.
- Performance Metrics: Superior performance in fine-tuning scenarios over supervised models.
- Benefits: The pixel-based reconstruction task shows simplicity yet effectiveness, outperforming more complex discrete tokenizations like those in BEiT.
The paper also explores novel partial fine-tuning configurations, enhancing understanding of MAE's robustness in varied learning contexts.
Robustness and Generalization
The paper evaluates robustness using several robustness benchmarks, outperforming previous top results significantly. It showcases the strength of the learned features across corrupted and distorted datasets.
Conclusion
The research on Masked Autoencoders opens up scalable pathways for self-supervised learning in computer vision, borrowing yet innovatively adapting concepts from the success story of NLP pre-training paradigms. By addressing the spatial redundancy in images through high masking ratios and focusing computational resources efficiently, the paper exhibits promise for MAEs as a cornerstone for future advancements in vision, both theoretically and practically.
