- The paper demonstrates direct training of SNNs for semantic segmentation by redesigning FCN and DeepLab architectures.
- The study leverages surrogate gradient learning to address non-differentiability issues in spiking neural networks.
- Experimental results reveal over 2× energy efficiency and improved noise robustness compared to traditional ANNs.
Beyond Classification: Directly Training Spiking Neural Networks for Semantic Segmentation
Introduction
The paper "Beyond Classification: Directly Training Spiking Neural Networks for Semantic Segmentation" (2110.07742) introduces an alternative method to artificial neural networks (ANNs) by implementing spiking neural networks (SNNs) for semantic segmentation tasks. SNNs are recognized for their asynchronous, event-driven processing, which significantly lowers power consumption compared to ANNs. This characteristic makes SNNs ideal for deployment in resource-constrained environments such as autonomous vehicles. The paper addresses the challenges associated with the non-differentiability and complex dynamics of SNNs that have traditionally limited their application to image recognition. The authors propose a solution by redesigning two fundamental ANN segmentation architectures, Fully Convolutional Networks (FCN) and DeepLab, for direct training using SNNs.
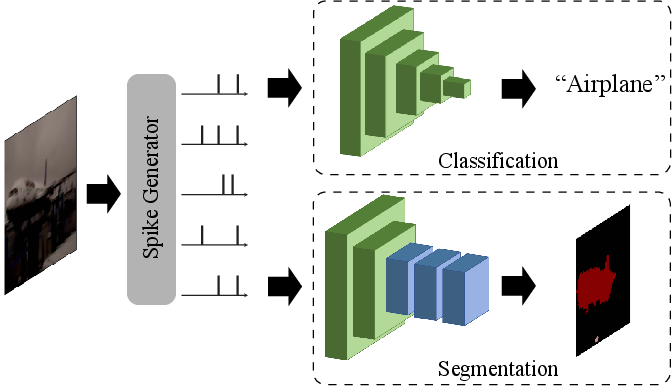
Figure 1: The concept of image classification and semantic segmentation. For a given image, the classification network provides a class prediction, while the semantic segmentation network assigns every pixel in the image its own class, resulting in a two-dimensional prediction map.
Methodology
The paper explores two representative methods for optimizing SNNs: ANN-SNN conversion and surrogate gradient learning. In the ANN-SNN conversion, pre-trained ANN models are transformed into SNNs by replacing ReLU activation neurons with Integrate-and-Fire (IF) neurons. However, this approach faces limitations in capturing temporal spike information, resulting in high latency and degraded performance, particularly with tasks beyond basic image classification. In contrast, surrogate gradient learning directly trains SNNs using approximated gradient functions, leading to lower latency and improved performance.
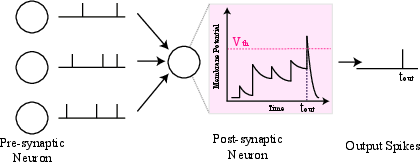
Figure 2: The neuronal dynamics of SNNs, illustrating the spike train transmission and membrane potential dynamics within neurons.
To enhance performance, the authors introduce redesigned architectures of FCN and DeepLab tailored for the SNN domain. Spiking-FCN comprises a downsampling and upsampling network with skip connections, while Spiking-DeepLab employs dilated convolutions and bilinear interpolation. These modifications focus on maintaining high spatial resolution and increasing receptive fields in deep network layers to achieve effective semantic segmentation.
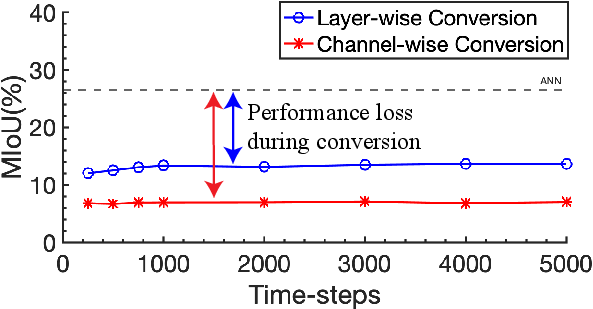
Figure 3: Performance of converted SNNs with respect to the number of time-steps, indicating degraded performance due to large activation variance.
Experimental Setup
The paper provides extensive experimental evaluation using the PASCAL VOC2012 and DDD17 datasets. The PASCAL VOC2012 dataset consists of static image data, which is processed using Poisson rate coding to convert images into spike trains. DDD17 features event-based data captured by dynamic vision sensors (DVS), which naturally provides spike streams allowing direct training without the need for additional coding schemes. Evaluations of the Spiking-FCN and Spiking-DeepLab architectures demonstrate the feasibility of SNNs for semantic segmentation, with enhanced robustness to noise and energy efficiency compared to ANNs.
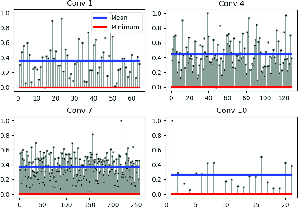
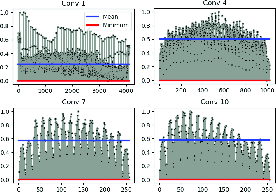
Figure 4: Illustration of normalized maximum activations across channel and spatial axes in DeepLab architecture.
Results and Analysis
Quantitative results indicate that while ANN counterparts achieve slightly superior performance, the advantages of SNNs are evident in areas of robustness and energy-efficiency. The Spiking-DeepLab and Spiking-FCN architectures deliver robust performance against Gaussian noise due to their spike-based input encoding. Energy consumption analysis highlights that SNN architectures offer more than 2× energy efficiency compared to standard ANNs, particularly when processing static image datasets.

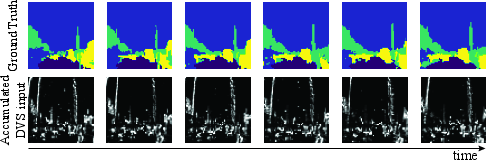
Figure 5: Examples of input representations, showcasing the conversion of static images into Poisson spikes and the accumulation of spikes in event-based camera input.
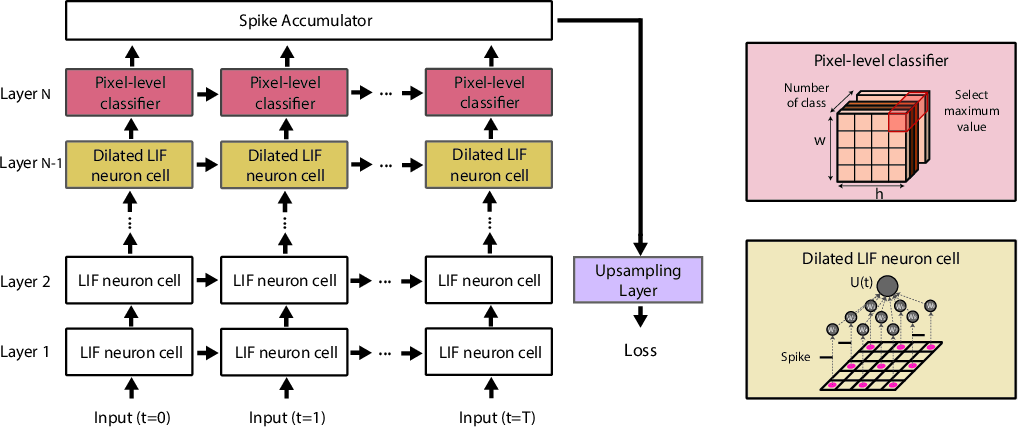
Figure 6: Spiking-DeepLab architecture unrolled over multiple time-steps, detailing neuron dynamics and spike accumulation in dilated layers.
Conclusion
The paper successfully expands the application of SNNs from image recognition to semantic segmentation, presenting Spiking-FCN and Spiking-DeepLab as viable, energy-efficient alternatives to traditional ANN models. While gaps remain in performance, the inherent robustness and efficiency of SNNs highlight their potential for deployment in constrained environments and future scene-understanding tasks. This foundational research opens doors for further development of SNN-centric learning mechanisms to bridge current performance discrepancies and optimize SNN capabilities for complex vision applications.