- The paper introduces feature adapters that enhance vision-language models through a bottleneck architecture, proving especially effective in few-shot learning.
- It employs a residual-blending technique that integrates pretrained zero-shot features with new, fine-tuned representations.
- Empirical evaluations across 11 datasets demonstrate significant accuracy improvements over traditional prompt tuning, reducing overfitting in low-data regimes.
CLIP-Adapter: Enhanced Vision-LLMs Through Feature Adaptation
The "CLIP-Adapter: Better Vision-LLMs with Feature Adapters" (2110.04544) paper investigates an innovative approach to improving vision-LLMs by integrating feature adapters, contrasting the predominant reliance on prompt tuning. This technique enhances the performance of vision-language tasks by marrying feature adaptation with fine-tuning mechanisms, thereby sidestepping the conventional pitfalls of prompt engineering.
Introduction to Vision-LLM Improvements
The research highlights the limitations inherent in traditional vision-language systems trained using fixed sets of discrete labels. Leveraging the paradigm introduced in CLIP models [Radford et al., 2021], which align images with raw text data, this paper advances the domain through the introduction of CLIP-Adapter—an approach that enriches the feature adaptation process rather than focusing solely on textual prompt tuning. The unique contribution of CLIP-Adapter lies in its adoption of a bottleneck architecture for feature learning, which is particularly advantageous in tasks lacking substantial data, such as few-shot learning scenarios.
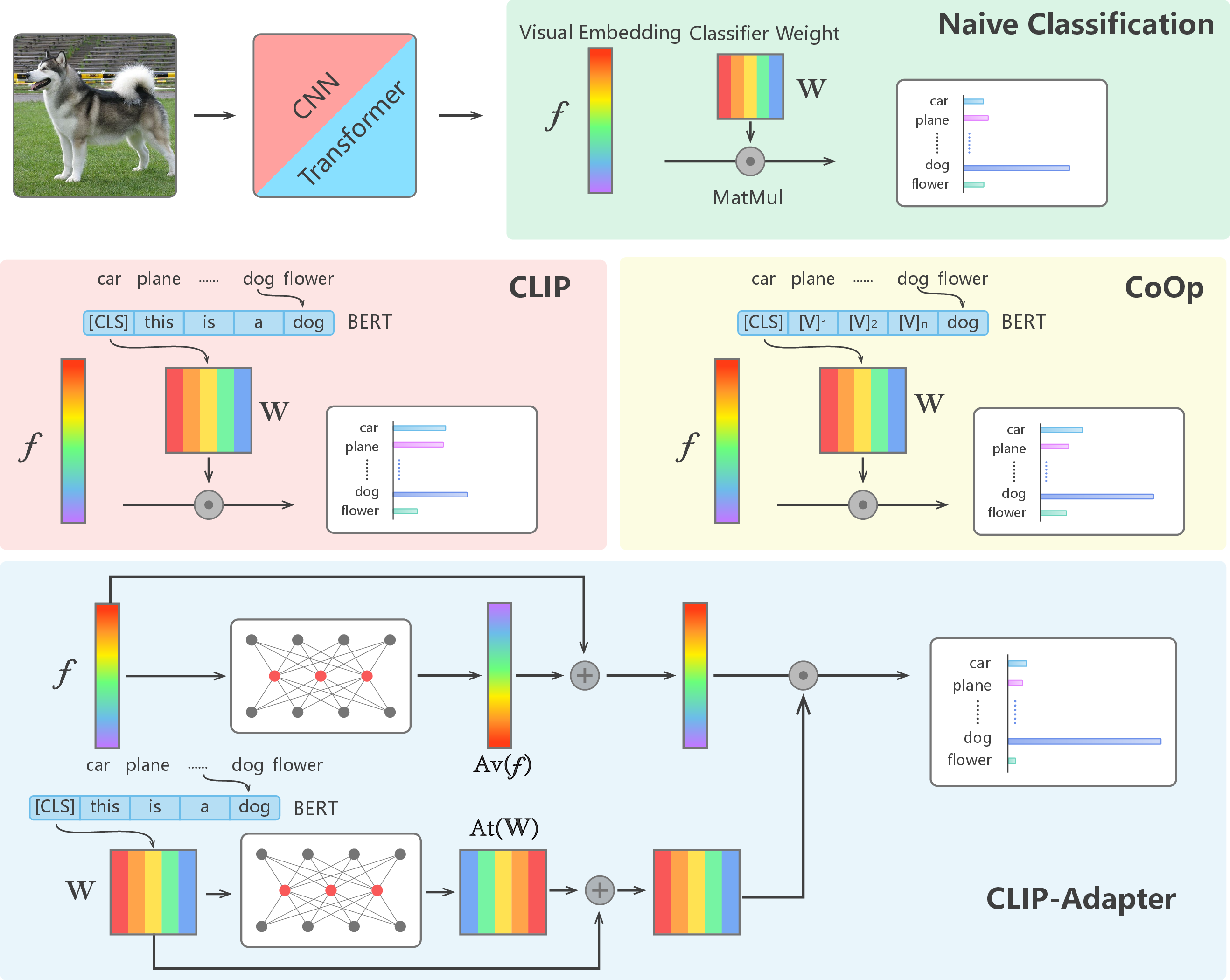
Figure 1: Comparison of different visual classification architectures. The image in the top row with a green region shows the naive pipeline for image classification.
Proposed Method: CLIP-Adapter
Unlike prompt tuning approaches that optimize textual inputs, CLIP-Adapter introduces fine-tuning via feature adapters, enabling a more dynamic adaptation process that incorporates knowledge from pretrained models like CLIP. This method is particularly advantageous for reducing overfitting—a common issue in data-scarce environments. Leveraging a lightweight bottleneck layer enables the method to selectively incorporate pretrained and newly learned features (Figure 2).
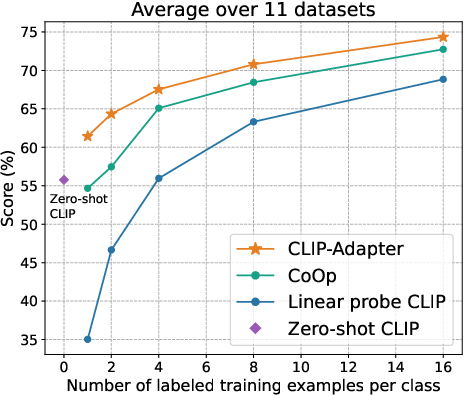
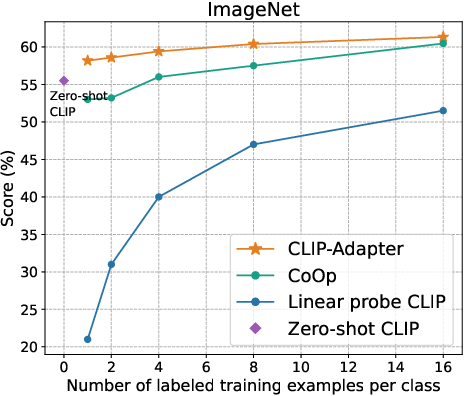
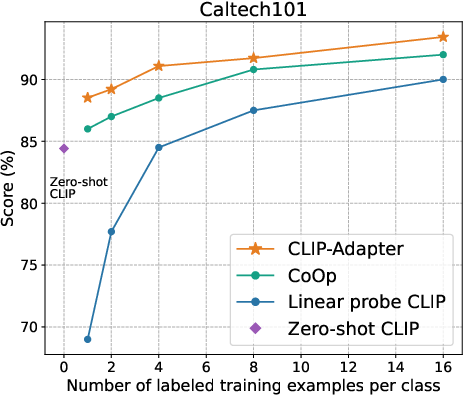
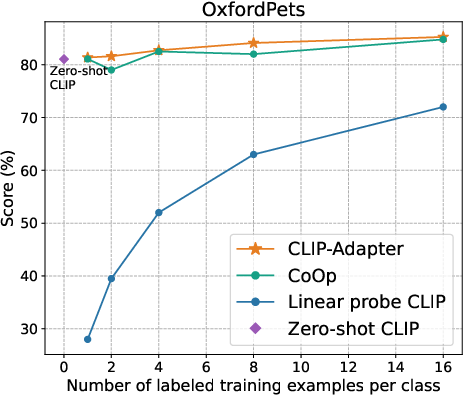
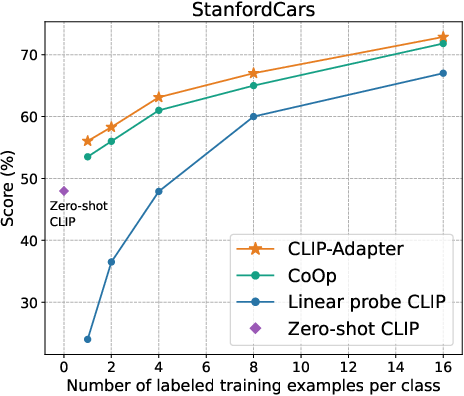
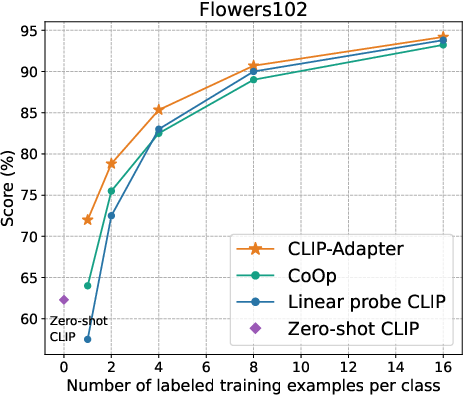
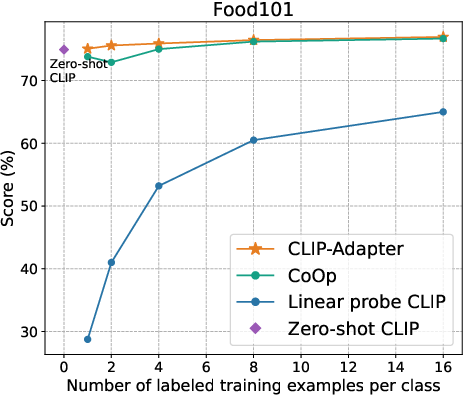
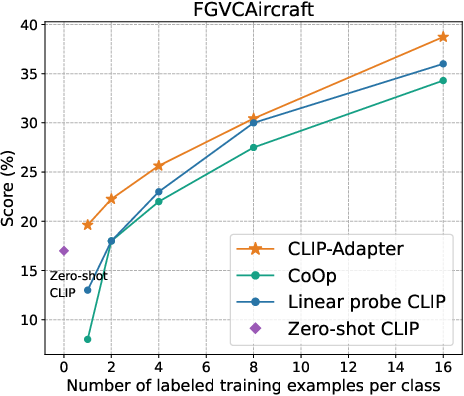
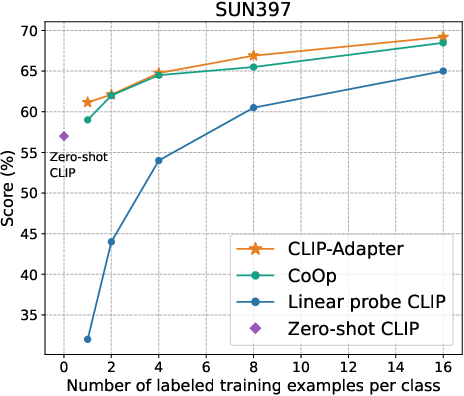
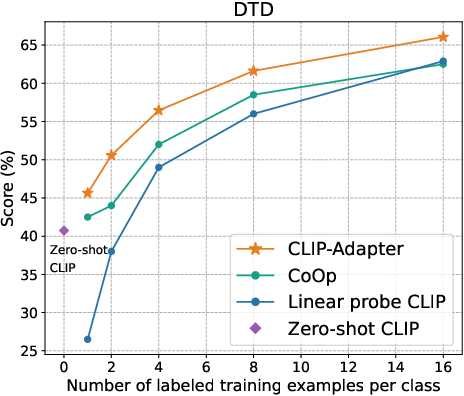
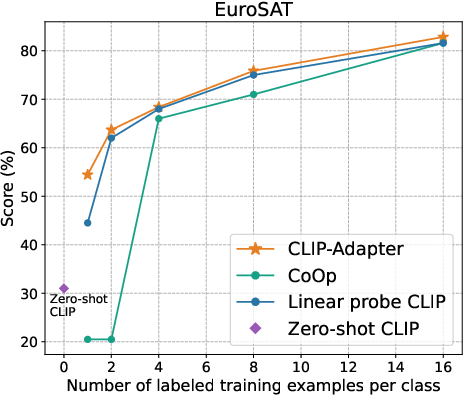
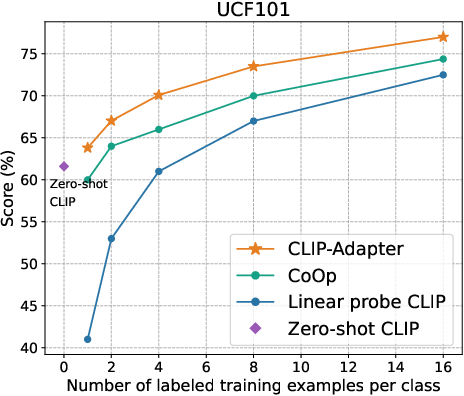
Figure 2: Main results of few-shot learning on 11 datasets. CLIP-Adapter consistently shows better performance over previous baselines across different training shots.
Through a residual-style blending mechanism, CLIP-Adapter effectively combines the robust capabilities of zero-shot features with the nuanced adaptations specific to few-shot training data. This dual-layer linear transformation, encapsulated in visual and text adapters, facilitates a comprehensive refinement of model capabilities without necessitating extensive computational resources.
Evaluation and Comparative Analysis
The empirical evaluation of CLIP-Adapter against baseline models such as Zero-shot CLIP, Linear probe CLIP, and CoOp demonstrates its superior adaptative performance across 11 classification datasets. Notably, the model excels in low-data regimes, achieving significant accuracy improvements especially pronounced in one-shot or two-shot training scenarios (Figure 3).
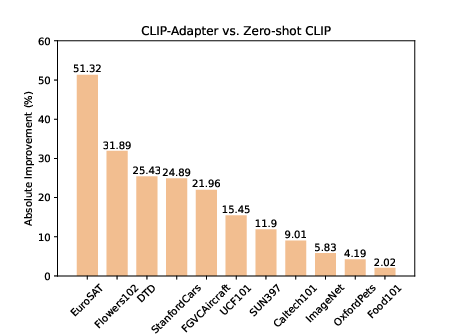
Figure 3: Absolute performance gain of CLIP-Adapter against hand-crafted prompts on different datasets.
Extensive ablation studies reveal that the optimal residual ratio, a critical hyperparameter of the model, varies with dataset characteristics. This adaptability is indicative of the model's ability to dynamically adjust its learning focus based on the semantic content of the data, enhancing its generalization across diverse visual tasks.
Visualization and Understanding of Feature Manifolds
Visual representations of feature manifolds, as explored in the paper through t-SNE visualizations, further substantiate the efficacy of CLIP-Adapter in learning distinct, well-separated feature spaces. This is instrumental in differentiating between closely related visual categories, thereby enhancing model accuracy in complex classification tasks (Figure 4).
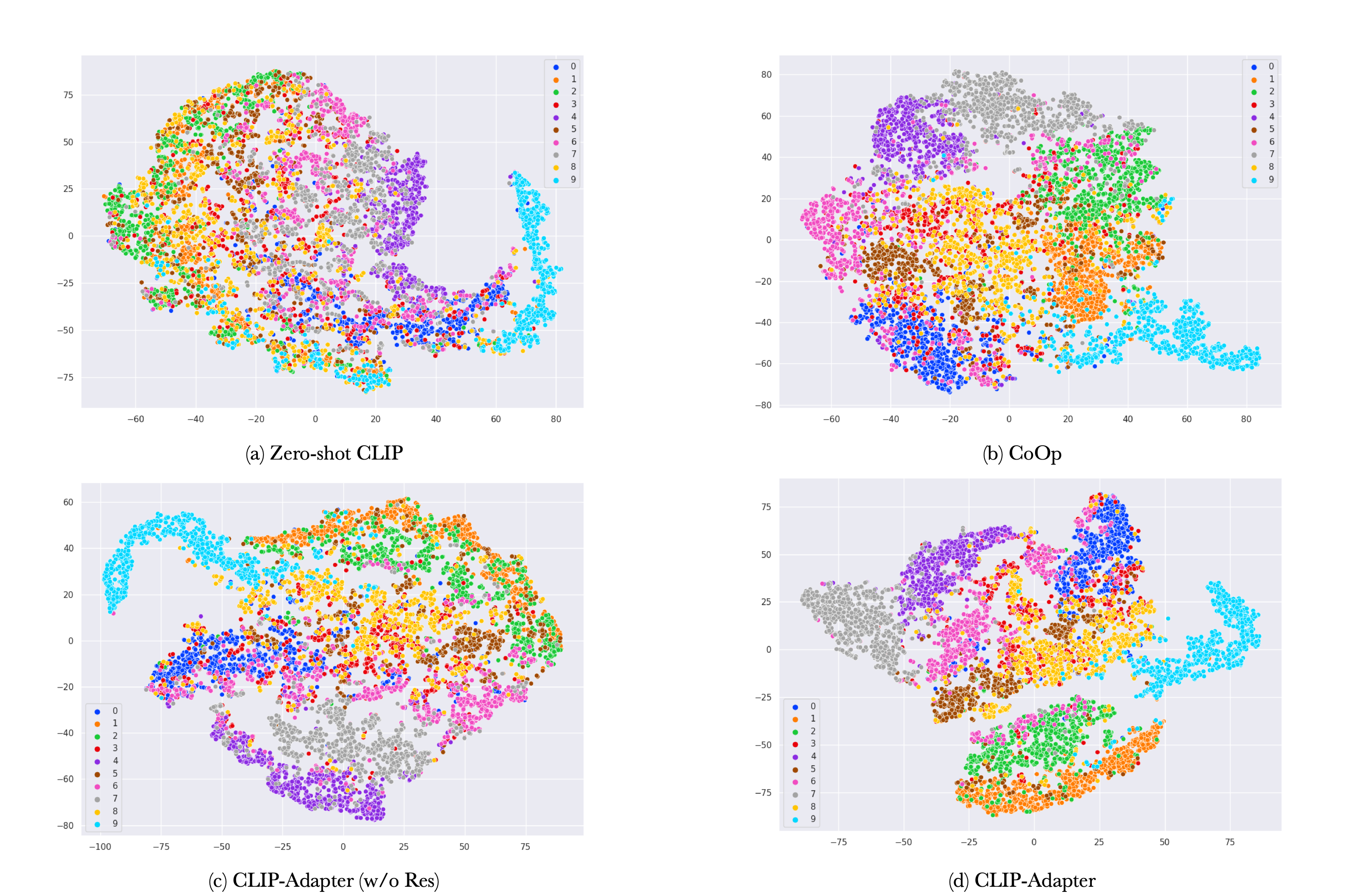
Figure 4: Visualization of different learned feature manifolds via t-SNE.
Conclusion
CLIP-Adapter represents a significant stride towards the advancement of vision-LLMs by shifting the focus from prompt tuning to adaptive feature learning. Its success can guide future research towards more versatile tuning methodologies that balance computational efficiency with model performance. The confluence of residual blending and selective feature transformation observed in CLIP-Adapter provides a roadmap for deploying adaptive models in varied AI applications, promising new frontiers in machine understanding of multimodal data. Future work may explore the integration of CLIP-Adapter with prompt tuning techniques to harness the full potential of pretrained vision-language backbones in scenarios demanding nuanced linguistic and visual understanding.