- The paper exposes ethical risks in multimodal datasets created from uncurated web data, highlighting misogyny, pornography, and biases through flawed CLIP filtering.
- The paper employs qualitative analysis of the LAION-400M dataset to demonstrate how automated filtering methods, like cosine similarity, fail to adequately remove harmful content.
- The findings urge a re-evaluation of AI data curation protocols, recommending rigorous audits and culturally aware methodologies to mitigate ethical and practical risks.
Multimodal Datasets: Concerns Over Misogyny, Pornography, and Malignant Stereotypes
Introduction
The paper "Multimodal datasets: misogyny, pornography, and malignant stereotypes" (2110.01963) addresses pressing concerns in the development and curation of large-scale multimodal datasets. With the rise of deep learning and AI, the need for massive datasets has driven researchers to aggregate data from the World Wide Web. However, this process often lacks careful curation, leading to datasets rife with problematic content such as pornography, misogynistic depictions, and ethnic stereotypes. This essay explores the paper's analysis of these issues using the LAION-400M dataset, a CLIP-filtered collection from the CommonCrawl dataset. The paper raises important questions for stakeholders in the AI community regarding the ethics and methodologies of dataset creation.
Analysis of LAION-400M
The LAION-400M dataset represents a significant attempt to create a large-scale repository of image-text pairs for training AI models. It was designed as an open-source alternative to closed datasets like OpenAI's WebImageText, containing over 400 million tuples derived from internet captions. Despite its size and intentions, qualitative assessments revealed the inclusion of explicit and harmful content, highlighting the drawbacks of automated filtering mechanisms like CLIP.

Figure 1: Results of the CLIP-experiments performed with the color image of the astronaut Eileen Collins obtained via skimage.data.astronaut().

Figure 2: Results of the CLIP-experiments performed with the official portrait image (from 2012) of Barack Obama (the 44th President of the United States) where the conspiracy-theoretic textual descriptions obtain a cosine-similarity higher than 0.3.
A critical experiment emphasized the flaw in CLIP's filtering and similarity metrics which may allow harmful content to surpass the thresholds. In illustrative tests, benign descriptions of figures like Eileen Collins and controversial descriptions of public figures, such as Barack Obama, were miscategorized, evidencing the risk of relying solely on cosine similarity for dataset filtering.
Concerns with Multimodal Datasets
Multimodal datasets, especially those sourced via automated web scraping, exacerbate existing biases due to a lack of contextual understanding and regulated curation methods. The LAION-400M analysis showed that benign and general queries could inadvertently return NSFW content, influenced by biases embedded within the dataset's textual descriptors.
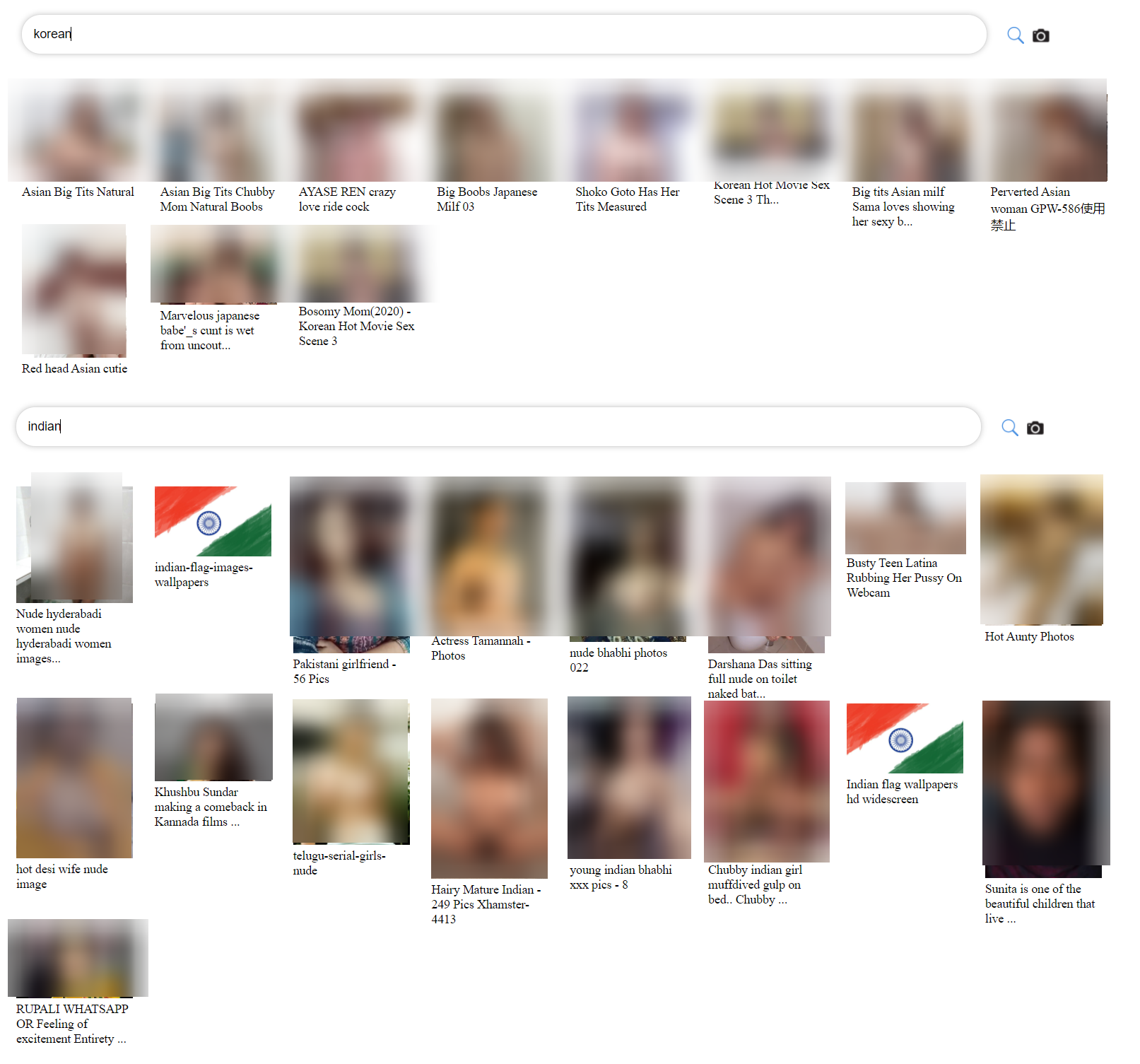
Figure 3: Collage of image screenshots capturing search results obtained from the clip-retrieval visual front-end portal to the LAION-400M dataset in response to nationality-related search terms such as 'Indian' and 'Korean'.
Notably, the dataset's reliance on CLIP's pre-trained models raises concerns over inherited biases, potentially from foundational datasets themselves carrying concealed stereotypical depictions and problematic associations.
Theoretical and Practical Implications
The LAION-400M dataset exposes challenges at the intersection of technical curation processes and ethical AI development. The paper emphasizes the need to rigorously evaluate and audit datasets for ethical compliance before deploying models trained on such data in real-world applications. This includes a necessary reconsideration of dataset licensing to mitigate unauthorized dissemination and usage, possibly including restrictive access to ensure ethical compliance.

Figure 4: Feature visualization of channel Unit 1543 of the CLIP-Resnet-50-4x model and the text that maximizes the dot product with 1543-neuron on the left.
Moreover, the findings urge an industry-wide reflection on the balance between dataset size milestones and ethical considerations. There is a call for the development of advanced filtering systems beyond simple automated approaches, considering nuanced cultural, social, and ethical contexts.
Conclusion
The paper underscores the critical issues surrounding large-scale multimodal dataset curation in AI advancements. While initiatives like LAION-400M aim to democratize access to extensive datasets, they inadvertently surface significant ethical and practical dilemmas. Stakeholders in AI, from developers to regulators, are therefore encouraged to engage deeply with these discussions and reevaluate the methodologies of dataset curation, considering not only technological advancement but also ethical responsibility. The ongoing dialogue on ethical datasets is vital in paving a responsible path towards the future of AI technologies.