- The paper introduces SkiLD, which extracts versatile skill representations from offline data to enhance demonstration-guided reinforcement learning.
- It leverages hierarchical policies and KL regularization to guide exploration and efficiently tackle complex tasks like maze navigation and robotic manipulation.
- Experimental and ablation studies show significant efficiency gains and robust adaptability, reducing the need for extensive task-specific demonstrations.
Demonstration-Guided Reinforcement Learning with Learned Skills
Introduction
The paper presents Skill-based Learning with Demonstrations (SkiLD), a reinforcement learning approach that enhances demonstration-guided RL by utilizing skills extracted from task-agnostic offline datasets. This method addresses inefficiencies in prior RL strategies which attempt to mimic demonstrations without considering reusable subtask structures. SkiLD extracts skills from vast prior experiences and employs them, rather than primitive action sequences, to efficiently learn new tasks, validated on maze navigation and complex robotic manipulation challenges.
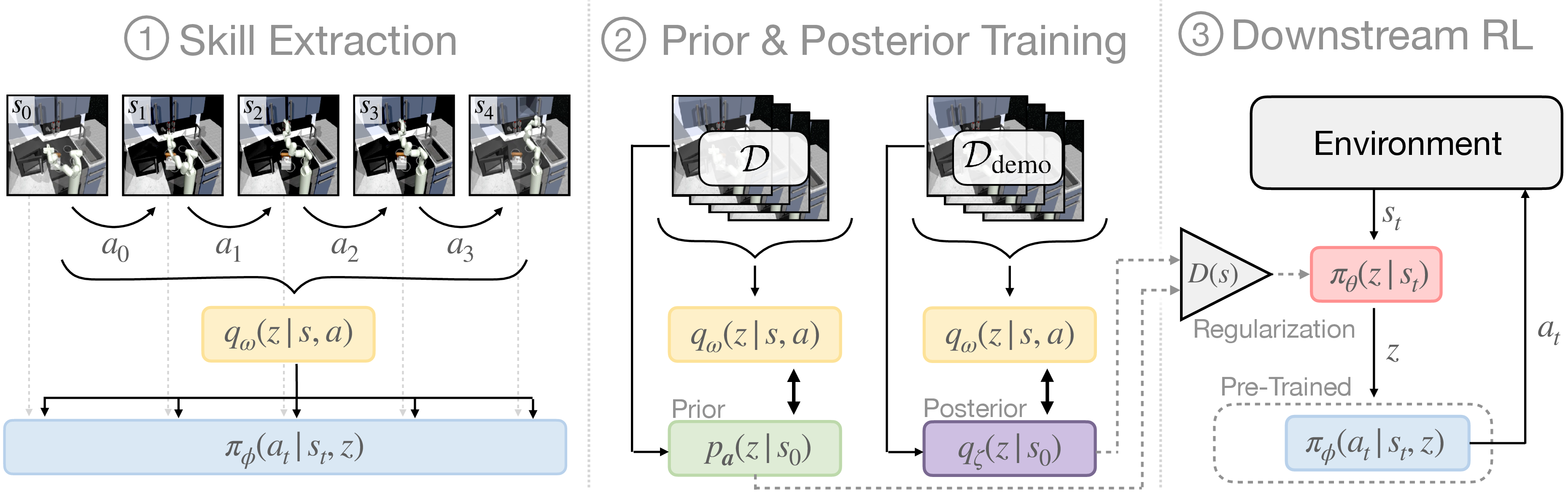
Figure 1: Our approach, SkiLD, combines task-agnostic experience and task-specific demonstrations to efficiently learn target tasks in three steps: (1)~extract skill representation from task-agnostic offline data, (2)~learn task-agnostic skill prior from task-agnostic data and task-specific skill posterior from demonstrations, and (3)~learn a high-level skill policy for the target task using prior knowledge from both task-agnostic offline data and task-specific demonstrations.
Methodology
SkiLD exploits task-agnostic offline datasets to learn robust skills and leverages target-specific demonstrations to guide policy learning for new tasks. The process involves:
- Learning skill representations from task-agnostic data using a closed-loop policy model.
- Extracting a skill prior and posterior to guide exploration during downstream learning.
- Formulating a three-part RL objective that balances between skill prior, task-specific skill posterior, and demonstration matching through a discriminator.
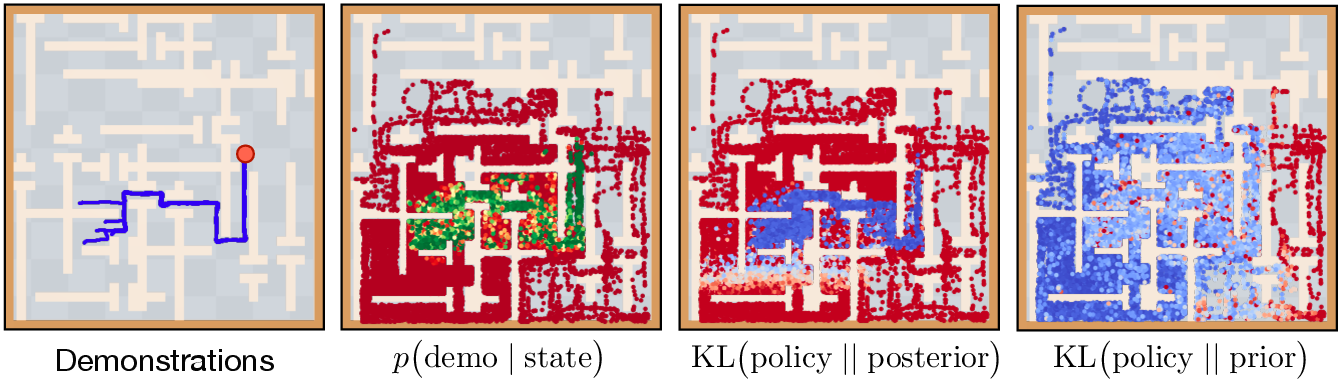
Figure 2: Visualization of our approach on the maze navigation task (% visualization states collected by rolling out the skill prior). Left: the given demonstration trajectories; Middle left: output of the demonstration discriminator D(s) (the \textcolor[HTML]{00A86B
SkiLD uses a hierarchical learning architecture with a high-level policy for skill sequencing. This policy is regularized with a KL-divergence term, drawing from both skill prior and posterior, encouraging exploration that aligns with successful task execution as inferred from demonstrations.
Experimental Results
Empirical validation shows that SkiLD markedly outperforms prior RL approaches, especially on tasks with sparse rewards or requiring long-horizon strategies. Key findings include:
- Efficient task solving in maze navigation with a limited number of demonstrations compared to baseline methods.
- Significant improvements in robotic manipulation tasks, showcasing complex skill compositions achievable by SkiLD through its skill-based structure.
- Enhanced learning efficiency even when task-agnostic data and target task are misaligned, demonstrating robust adaptability.

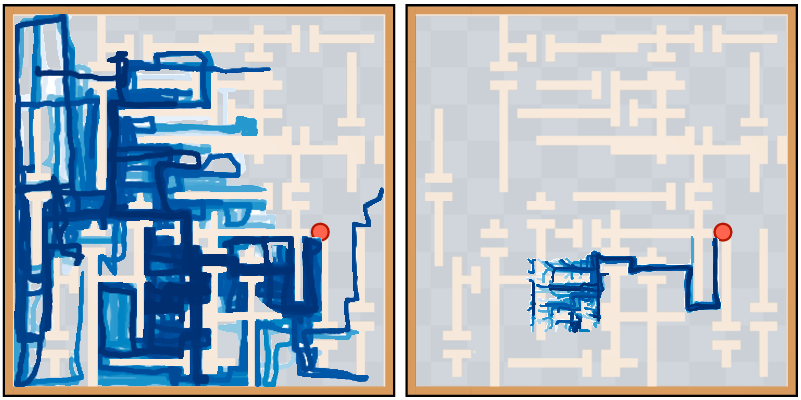
Figure 3: Qualitative results for GAIL+RL on maze navigation. Even though it makes progress towards the goal (red), it fails to ever obtain the sparse goal reaching reward.
Ablation Studies
A number of ablation studies highlight the pivotal role of integrated skill priors and posteriors. Removing the reward bonus or posterior guidance detracts from performance, emphasizing the need for discriminator-based skill refinement. Results support the conclusion that skilled demonstration coupling with prior experience yields substantial gains in efficiency.
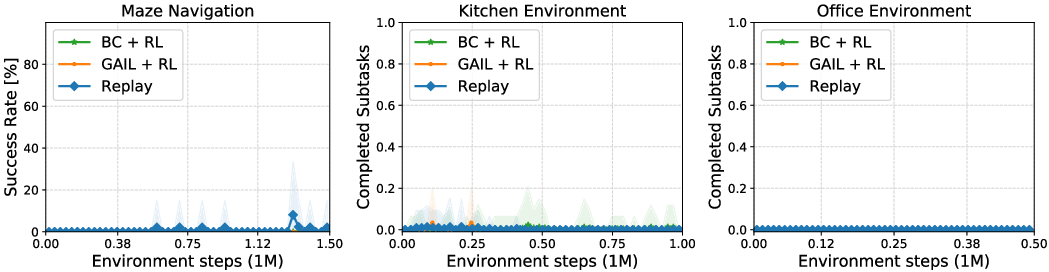
Figure 4: Downstream task performance for prior demonstration-guided RL approaches with combined task-agnostic and task-specific data. All prior approaches are unable to leverage the task-agnostic data, showing a performance decrease when attempting to use it.
Implications and Future Work
This research substantiates the argument for using large-scale task-agnostic datasets to bootstrap demonstration-guided RL, presenting a feasible method to reduce dependency on extensive task-specific demonstrations. The implications extend towards scalable deployment in real-world scenarios where collecting exhaustive demonstrations is infeasible. Future work could address further integration strategies for skill-based learning that navigates highly dynamic environments, potentially extending to adaptive learning frameworks involving real-time data curation.
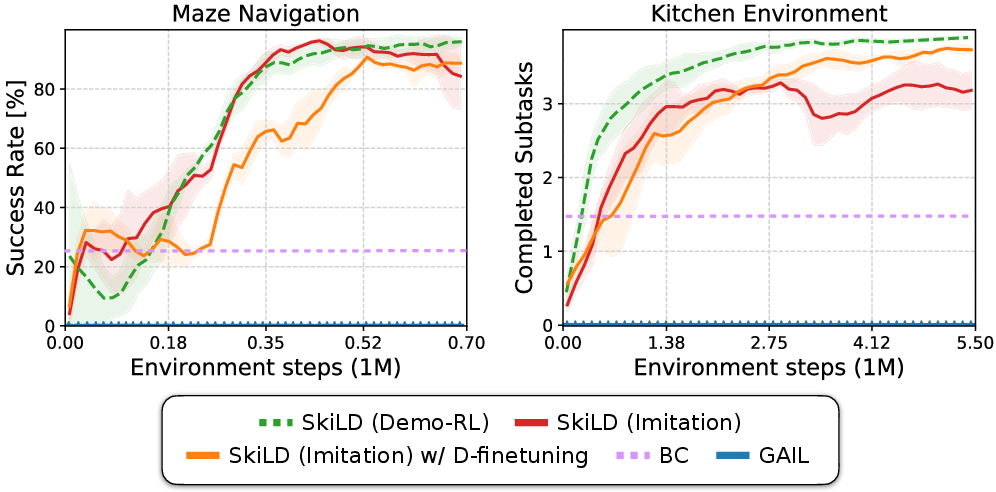
Figure 5: Imitation learning performance on maze navigation and kitchen tasks. Compared to prior imitation learning methods, SkiLD can leverage prior experience to enable the imitation of complex, long-horizon behaviors. Finetuning the pre-trained discriminator D(s) further improves performance on more challenging control tasks like in the kitchen environment.
Conclusion
SkiLD offers a compelling solution to enhance RL efficiency by strategically integrating demonstration guidance with skill-based learning derived from heterogeneous datasets. The approach proves effective in diverse setups, ensuring robust policy development capable of tackling complex, high-dimensional tasks with less dependence on task-specific supervision.

