- The paper introduces SPLADE, a sparse ranking model that leverages logarithmic activations to balance sparsity with document-query expansion.
- It employs a combined ranking and regularization loss, significantly reducing FLOPS while matching performance of dense models on benchmarks.
- Experiments on MS MARCO demonstrate SPLADE's competitive retrieval effectiveness and efficiency, setting a new standard for sparse IR methods.
SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking
Introduction
The development of large pre-trained LLMs such as BERT has significantly transformed NLP and IR domains. In the context of neural information retrieval, the primary challenge is to enhance the effectiveness of the initial retrieval stage. While dense retrieval using methods like approximate nearest neighbors has yielded impressive outcomes, it lacks the mechanism to precisely match term-level representations. This limitation has driven recent interest in sparse representation learning as a potential solution. The paper introduces SPLADE, a first-stage ranking model that focuses on balancing sparsity and document-query expansion while leveraging properties of BOW models, including efficiency and interpretability.
SPLADE Model Description
SPLADE utilizes a strategic combination of explicit sparsity regularization and a logarithmic activation function. By doing so, the model achieves highly sparse representations while maintaining competitive performance with state-of-the-art sparse and dense models. SPLADE is designed to be trained end-to-end in a single stage, thus simplifying the training complexity compared to other models that require multi-stage processes.
The SPLADE model introduces a logarithmic activation to control the saturation of term weights, preventing certain terms from dominating and naturally ensuring sparsity:
wj=i∈t∑log(1+ReLU(wij))
This approach contrasts with methods that apply a traditional ReLU activation, providing benefits in both effectiveness and efficiency.
Ranking and Regularization
SPLADE's ranking is guided by a loss function integrating both ranking objectives and regularization to ensure sparse embeddings:
L=Lrank−IBN+λqLregq+λdLregd
Where Lreg can be either ℓ1 regularization or the more balanced ℓFLOPS regularization. The latter enforces a more even distribution of active terms, which results in efficient index structures (Figure 1).
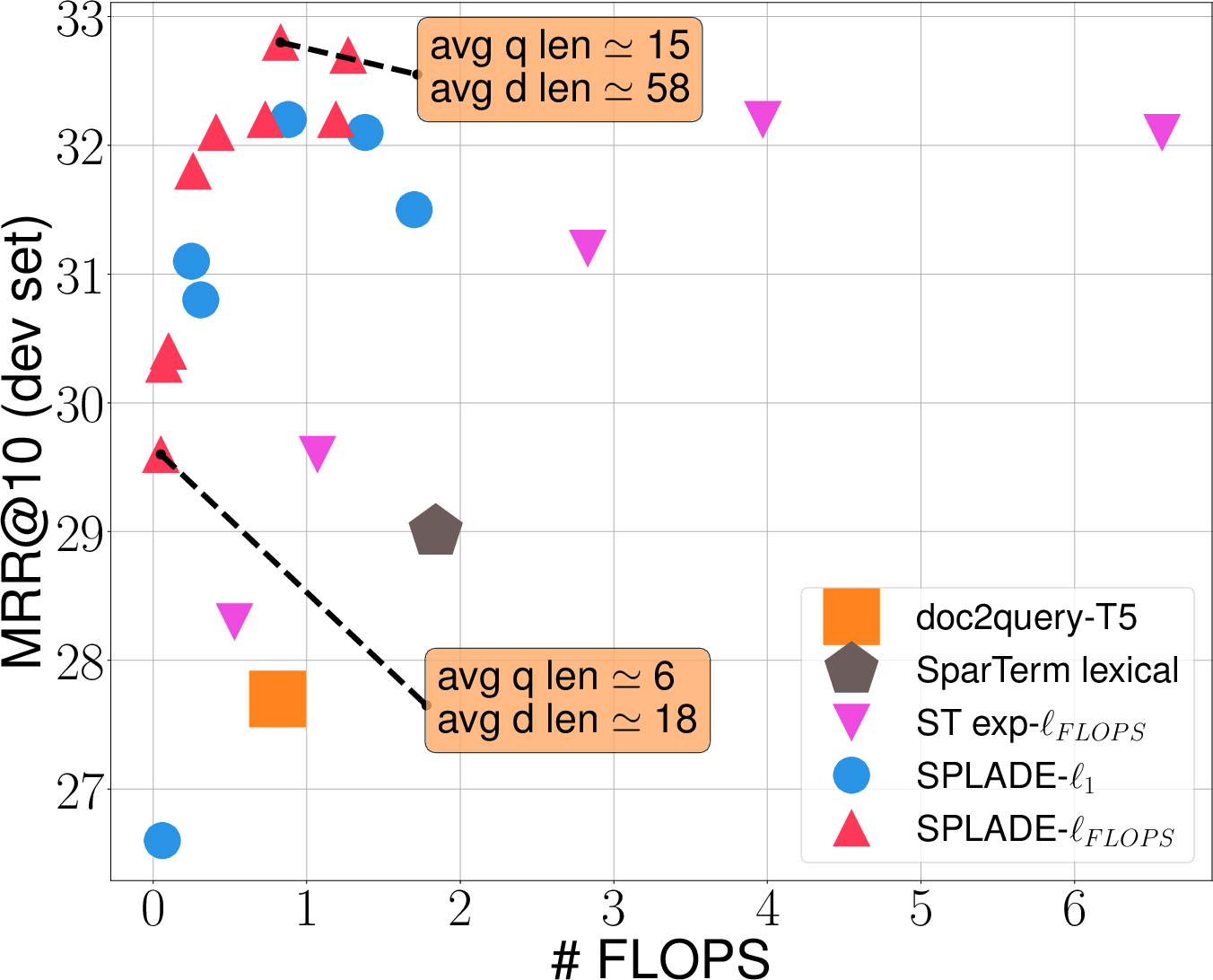
Figure 1: Performance vs FLOPS for SPLADE models trained with different regularization strength λ on MS MARCO.
Experimental Evaluation
Experiments have been performed utilizing the MS MARCO passage ranking dataset, yielding promising results. SPLADE surpassed other sparse retrieval methods—like DeepCT and doc2query-T5—and echoed the efficacy of dense models such as ANCE. Notably, SPLADE demonstrated a significant reduction in the average floating-point operations (FLOPS) required for a query-document pair, while maintaining competitive retrieval performance.
Comparison Between Dense and Sparse Retrieval
The results highlighted that SPLADE models offer a compelling trade-off between computational efficiency and retrieval effectiveness, overcoming the typical divisiveness observed between dense and sparse methods. The introduction of FLOPS regularization further facilitates the creation of indices that are not just efficient but also aligned with the sparsity of traditional lexical indices.
Future Implications and Conclusion
The approach SPLADE brings to sparse representation learning emphasizes on efficiency and straightforward training pipelines without sacrificing effectiveness. SPLADE stands as a promising candidate for initial retrieval tasks, holding potential for further refinement and application in a range of information retrieval contexts.
Future work can explore enhancements through hybrid indexing solutions or adaptations into more complex ranking architectures. SPLADE not only sets a precedent for sparse retrieval models but also opens avenues for continued research into efficient neural ranking mechanisms.