- The paper introduces DocSynth, a framework that uses layout guidance and adversarial learning to generate realistic synthetic document images from predefined layouts.
- It employs a dual adversarial network architecture, integrating a generator with discriminators and a conv-LSTM based spatial reasoning module for layout consistency.
- Quantitative results on PubLayNet, including an FID of 33.75 and a Diversity Score of 0.197, demonstrate its effectiveness in augmenting training datasets.
DocSynth: A Layout Guided Approach for Controllable Document Image Synthesis
The paper "DocSynth: A Layout Guided Approach for Controllable Document Image Synthesis" introduces a novel framework for the synthesis of document images based on predefined layouts. This work addresses the challenge of generating document images with complex object layouts, offering a solution that constructs realistic and diverse synthetic documents by employing a deep generative model.
Introduction
The ability to automatically generate document images based on specified layouts offers significant advancements in the field of Document Analysis and Recognition. The viability of document synthesis facilitates the augmentation of training datasets for machine learning tasks, beneficial for domains with limited data and privacy concerns. Traditional approaches in computer graphics and vision have faced challenges in generating documents with complex layouts while maintaining visual and logical consistency. The introduction of neural rendering, particularly GANs, provides an avenue to achieve controllable image generation of document layouts. The DocSynth framework stands as a pioneering effort to generate synthetic document images with user-defined layout properties.
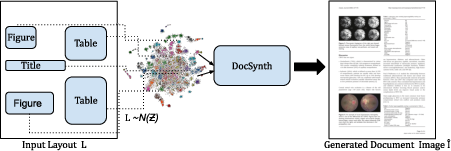
Figure 1: Illustration of the Task: Given an input document layout with object bounding boxes and categories configured in an image lattice, our model samples the semantic and spatial attributes of every layout object from a normal distribution, and generate multiple plausible document images as required by the user.
Methodology
The problem is defined as generating a document image I~ from a layout L consisting of object categories and bounding boxes, along with a latent estimation Zobj sampled from a normal distribution. The mapping follows the function I~=G(L,Zobj;ΘG), where ΘG are trainable parameters capturing the data distribution aligned with the spatial configurations of document layout objects.
Model Architecture
The DocSynth architecture comprises two primary adversarial networks: the generator G and two discriminators (Dimg and Dobj). The generator is equipped with a conditioned image generator H, global layout encoder C, and an image decoder K. It incorporates object and layout encoding to generate realistic document images.
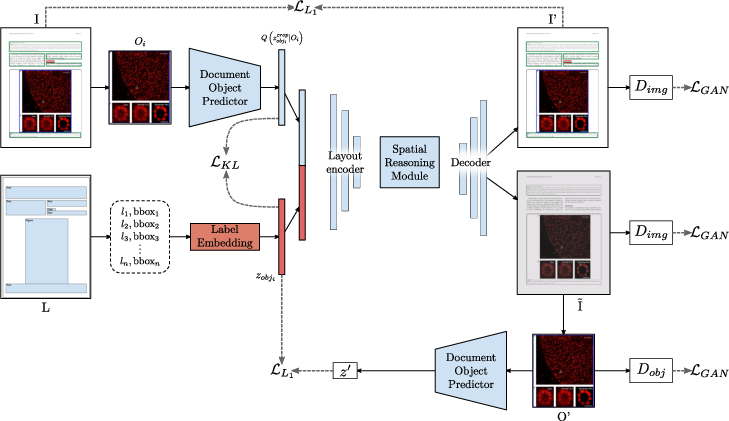
Figure 2: Overview of our DocSynth Framework: The model has been trained adversarially against a pair of discriminators and a set of learning objectives as depicted.
Spatial Reasoning Module
A convolutional LSTM (conv-LSTM) network is employed for effective spatial reasoning. This network translates the object feature maps Fi into a hidden layout feature map h, preserving both local and global spatial features crucial for synthetic document synthesis.
Experimental Validation
Qualitative Results
The DocSynth model demonstrates competency in creating diverse and realistic document images, shown through a comprehensive t-SNE visualization and examples of synthesized documents. The model effectively maintains layout consistency while generating variable object appearances.

Figure 3: t-SNE visualization of the generated synthetic document images.

Figure 4: Examples of diverse synthesized documents generated from the same layout: Given an input document layout with object bounding boxes and categories, our model samples 3 images sharing the same layout structure, but different in style and appearance.

Figure 5: Examples of synthesized document images by adding or removing bounding boxes based on previous layout: There are 2 groups of images (a)-(c) and (d)-(f) in the order of adding or removing objects.
Quantitative Results
The performance of DocSynth, measured via FID and Diversity Scores on the PubLayNet dataset, underscores its capacity to generate images that closely mimic real documents. The benchmark evaluation reveals an FID of 33.75 and a Diversity Score of 0.197 for 128x128 images, indicating strong alignment with real-world dataset structures.
Conclusion
DocSynth offers a substantial contribution to the field of document image synthesis by introducing a framework that delivers on generating diverse, layout-guided synthetic documents. The integration of complex interactions between layout objects and preserved document structure paves the way for further research into high-resolution synthesis and auxiliary applications such as document classification and layout analysis. Potential future work includes extending the resolution capabilities of the framework and exploring broader applications within document analytics and data augmentation strategies.