- The paper introduces DF-Conformer, a novel model integrating Conv-TasNet and Conformer via linear complexity self-attention for improved speech enhancement.
- It leverages FAVOR+ and dilated depthwise convolutions to boost denoising performance and computational efficiency.
- Experimental results show superior SI-SNRi and ESTOI improvements over existing models, validating its scalability and real-world applicability.
The paper "DF-Conformer: Integrated architecture of Conv-TasNet and Conformer using linear complexity self-attention for speech enhancement" (2106.15813) presents a novel single-channel speech enhancement framework that improves both denoising performance and computational efficiency. The study leverages the strengths of Conv-TasNet and Conformer architectures, incorporating linear complexity self-attention mechanisms to address inherent computational challenges.
Introduction to Speech Enhancement Frameworks
Single-channel speech enhancement (SE) is tasked with extracting clean speech signals from noisy inputs, with applications ranging from telecommunication systems to automated speech recognition (ASR). Traditional SE frameworks like Conv-TasNet utilize trainable analysis/synthesis filterbanks combined with mask prediction networks to achieve this goal. However, enhancing sequential modeling capabilities remains a critical area of research, driving improvements in both performance and computational efficiency.
The Conformer architecture, with its roots in Transformer-based models, employs depthwise convolution layers to augment sequential modeling, proving effective across various audio processing domains including ASR, sound event detection, and speaker diarization. In this paper, Conformer layers are integrated with the Conv-TasNet framework to form a new mask prediction network—DF-Conformer—which tackles computational complexity without compromising accuracy.
Architectural Design and Computational Solutions
The integration of Conformer with Conv-TasNet introduces two primary challenges: (1) High computational cost due to multi-head self-attention (MHSA) modules with quadratic time complexity, exacerbated by the dense frame rate in Conv-TasNet; (2) Insufficient receptive fields for sequence modeling due to small hop sizes in trainable filterbanks, affecting local sequential analysis.
To address these issues, DF-Conformer employs fast attention via positive orthogonal random features (FAVOR+), a linear complexity attention mechanism in lieu of traditional MHSA. Moreover, 1-D dilated depthwise convolution layers replace standard convolution layers, enhancing local sequential modeling capacity.
The dilated FAVOR Conformer (DF-Conformer) architecture incorporates these solutions, utilizing stacked Conformer blocks with FAVOR+ self-attention and dilated convolutions, facilitating efficient and scalable speech enhancement. The pseudo-code structure showcases this integration, achieving proportional time complexity of O(LN).
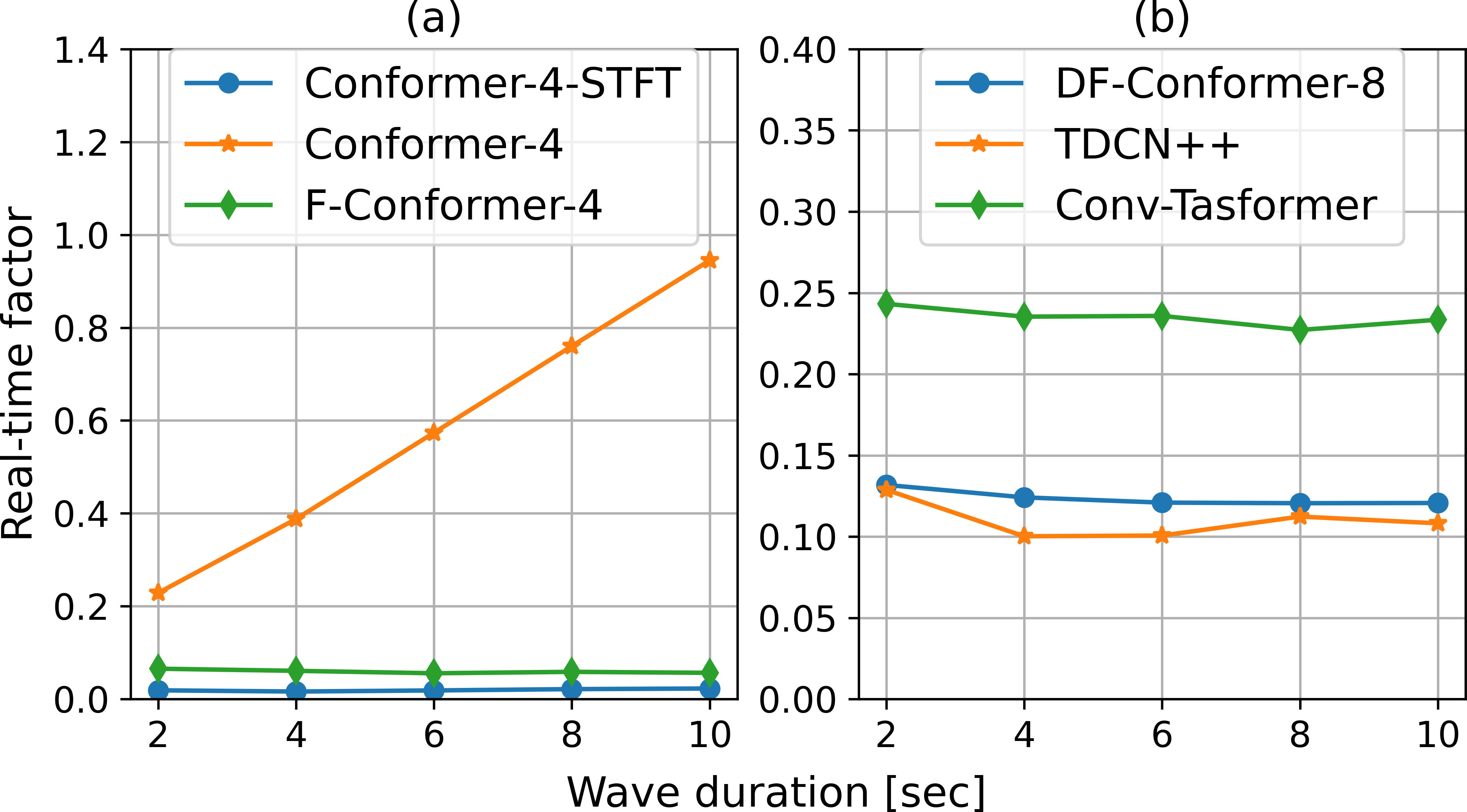
Figure 1: Comparison of RTF. (a) RTF of Conformer-4 increases as duration of input waveform increases, whereas that of F-Conformer-4 becomes constant. (b) RTFs of DF-Conformer-8 and TDCN++ are comparable, whereas that of Conv-Tasformer is larger than others due to additional MHSA-FAVOR-block.
Experimental Evaluation
Evaluation of Favor+
Experiments conducted on a dataset comprising 3,396 hours of noisy speech demonstrate FAVOR+'s impact on computational efficiency. Without increasing computational complexity, F-Conformer significantly reduces real-time factor (RTF), solving the scalability issues prevalent in traditional MHSA approaches.
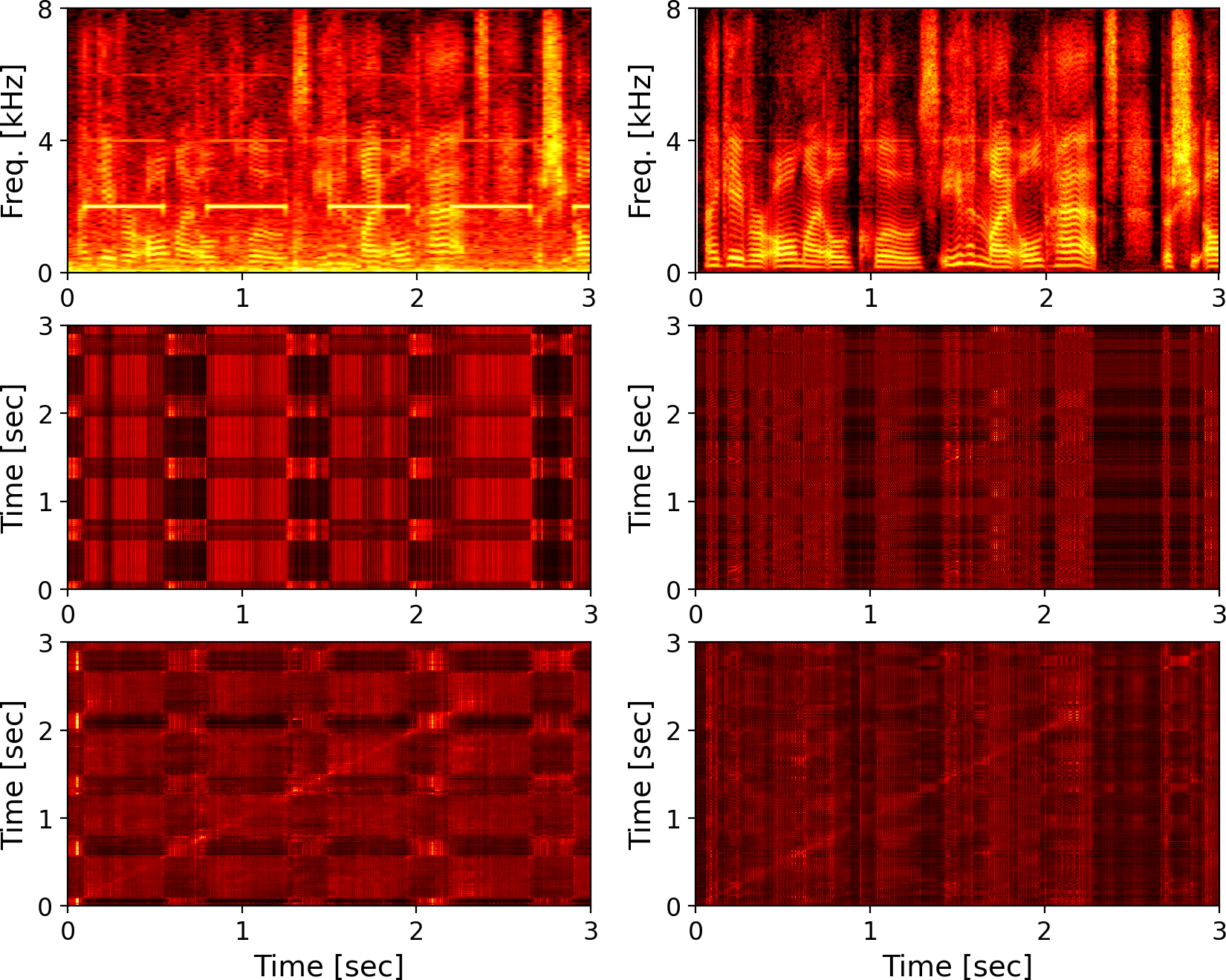
Figure 2: Examples of attention matrices in DF-Conformer-8. Spectrograms of noisy input and enhanced output (top row), and attention matrices for first and third (middle row) and last (bottom row) Conformer blocks calculated by D−1ϕ(Q)ϕ(K)⊤. The x and y axes of attention matrices denote the key and query, respectively.
DF-Conformer surpasses existing models like TDCN++ in scale-invariant signal-to-noise ratio improvement (SI-SNRi) and extended short-time objective intelligibility measure (ESTOI), attesting to its efficacy in speech enhancement. Iterative model extensions further elevate performance metrics, demonstrating DF-Conformer's scalability and adaptability.
Conclusion
This study introduces DF-Conformer, a computationally feasible, Conformer-based architecture for speech enhancement. By integrating linear complexity self-attention and dilated convolutions, DF-Conformer effectively balances performance demands with computational constraints. Future directions include iterative DF-Conformer models for larger datasets and comprehensive comparisons with dual-path architectures, enhancing real-world applicability in advanced speech processing systems.

