- The paper introduces a U-shaped Transformer architecture that integrates LeWin blocks and a multi-scale modulator to capture both local and global dependencies.
- The method achieves superior performance in denoising, deblurring, and deraining tasks, with measurable PSNR gains over state-of-the-art models.
- This study sets new benchmarks in image restoration quality, demonstrating practical improvements across multiple real-world datasets.
Abstract
The paper introduces Uformer, a Transformer-based architecture designed for image restoration tasks such as denoising, motion deblurring, defocus deblurring, and deraining. Utilizing a hierarchical encoder-decoder structure with novel Locally-enhanced Window (LeWin) Transformer blocks and a multi-scale restoration modulator, Uformer efficiently captures both local and global dependencies in image data, outperforming state-of-the-art methods across various datasets.
Introduction
Emerging camera technologies and the proliferation of multimedia applications have escalated the demand for efficient image restoration. Traditional solutions rely on ConvNet architectures, which struggle to capture long-range dependencies due to computational limitations in self-attention layers. Uformer addresses this with a U-shaped Transformer architecture, integrating hierarchical feature maps and efficient self-attention mechanisms to restore image details across diverse resolutions.
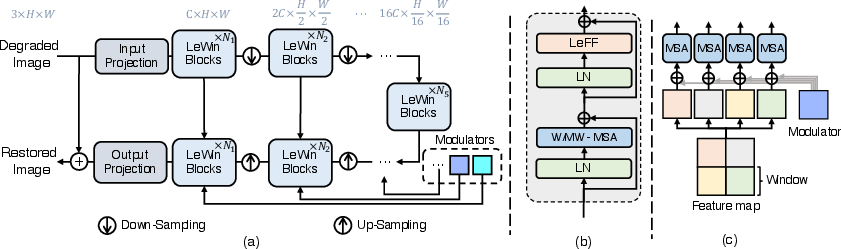
Figure 1: An overview of the Uformer structure including the LeWin Transformer block and modulation mechanism.
Window-based Multi-head Self-Attention (W-MSA)
Uformer employs non-overlapping window-based self-attention rather than global self-attention, significantly reducing computational costs. Transforming feature maps into smaller, manageable subsets, the W-MSA captures essential local dependencies while maintaining computational efficiency, scaled by window size M×M. This method mitigates quadratic complexity in high-resolution maps, enabling long-range dependency learning in hierarchical architectures.
Locally-enhanced Feed-Forward Network (LeFF)
To enhance local context capture, the Feed-Forward Network includes depth-wise convolutions within a Transformer block. This approach has been validated by recent studies for improved performance on low-level tasks, reinforcing local dependency modeling, essential for high-fidelity restoration.
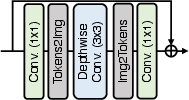
Figure 2: Locally-enhanced feed-forward network with convolutional augmentation to capture local contexts.
Multi-Scale Restoration Modulator
The modulator, a learnable spatial bias operating across feature layers, allows dynamic adjustment of features within each LeWin block, adapting to varied degradation patterns. This component introduces marginal computational overhead while substantially improving restoration quality, particularly in scenarios demanding fine detail recovery.






Figure 3: Comparative visual results highlighting improvements with the multi-scale restoration modulator.
Experiments and Results
Uformer outperformed benchmark models in comprehensive tests across image restoration tasks:
Real Noise Removal
Using the SIDD and DND datasets, Uformer achieved superior denoising performances with PSNR gains of 0.14 dB and 0.09 dB respectively over previous best methods like NBNet.


Figure 4: Visual comparison demonstrating Uformer’s effectiveness in denoising real-world noisy images.
Motion Blur and Defocus Blur Removal
On datasets such as GoPro, HIDE, and RealBlur, Uformer exceeded existing architectures, achieving notable improvements in PSNR scores across synthetic and real-world tests, reflecting strong deblurring capabilities.
Deraining
Uformer set new benchmarks on the SPAD dataset, enhancing image quality by 3.74 dB over SPAIR, demonstrating its robust generalization to diverse weather conditions.


Figure 5: Visual comparisons with state-of-the-art methods on the SPAD dataset for rain removal.
Conclusion
Uformer introduces a paradigm shift in image restoration with its efficient architecture, leveraging state-of-the-art Transformer capabilities. Its design choices including window-based self-attention and multi-scale modulation effectively address computational and dependency challenges characteristic of image restoration tasks. Future work may extend Uformer's application to more complex image manipulations, strengthening its utility in advanced vision applications.