Efficient Stepping Algorithms and Implementations for Parallel Shortest Paths
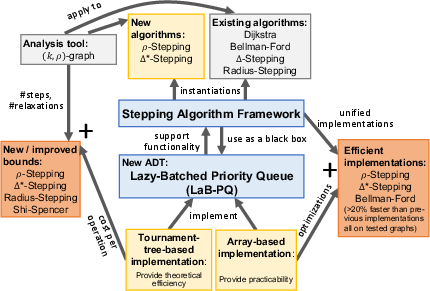
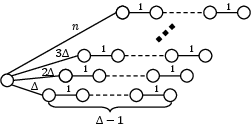
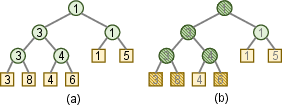
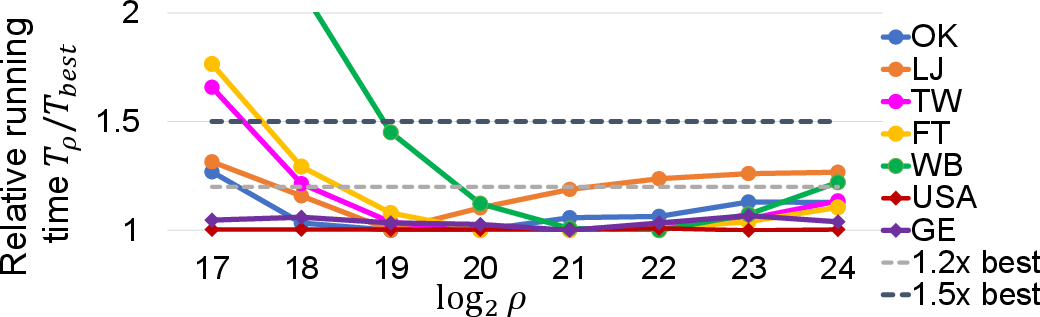
Abstract: In this paper, we study the single-source shortest-path (SSSP) problem with positive edge weights, which is a notoriously hard problem in the parallel context. In practice, the $\Delta$-stepping algorithm proposed by Meyer and Sanders has been widely adopted. However, $\Delta$-stepping has no known worst-case bounds for general graphs. The performance of $\Delta$-stepping also highly relies on the parameter $\Delta$. There have also been lots of algorithms with theoretical bounds, such as Radius-stepping, but they either have no implementations available or are much slower than $\Delta$-stepping in practice. We propose a stepping algorithm framework that generalizes existing algorithms such as $\Delta$-stepping and Radius-stepping. The framework allows for similar analysis and implementations of all stepping algorithms. We also propose a new ADT, lazy-batched priority queue (LaB-PQ), that abstracts the semantics of the priority queue needed by the stepping algorithms. We provide two data structures for LaB-PQ, focusing on theoretical and practical efficiency, respectively. Based on the new framework and LaB-PQ, we show two new stepping algorithms, $\rho$-stepping and $\Delta*$-stepping, that are simple, with non-trivial worst-case bounds, and fast in practice. The stepping algorithm framework also provides almost identical implementations for three algorithms: Bellman-Ford, $\Delta*$-stepping, and $\rho$-stepping. We compare our code with four state-of-the-art implementations. On five social and web graphs, $\rho$-stepping is 1.3--2.5x faster than all the existing implementations. On two road graphs, our $\Delta*$-stepping is at least 14\% faster than existing implementations, while $\rho$-stepping is also competitive. The almost identical implementations for stepping algorithms also allow for in-depth analyses and comparisons among the stepping algorithms in practice.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.