- The paper introduces a pure transformer-based U-shaped architecture that leverages hierarchical Swin Transformer blocks to overcome CNN limitations in capturing global context.
- It employs a novel patch expanding layer and optimized skip connections for efficient up-sampling, outperforming traditional interpolation methods.
- Experimental evaluations on Synapse and ACDC datasets show high Dice scores and improved edge prediction, validating its superior performance in medical segmentation.
Introduction
The paper presents Swin-Unet, a transformer-based U-shaped architecture designed for medical image segmentation. Traditional segmentation methods often rely on convolutional neural networks (CNNs) with U-shaped architectures due to their ability to learn discriminating features. However, these CNN architectures face challenges in capturing global context due to the intrinsic locality of convolution operations. Swin-Unet addresses this limitation by employing a purely transformer-based network, leveraging hierarchical Swin Transformers with shifted windows for both encoding and decoding the features for better semantic learning and segmentation accuracy.
Architecture Overview
Swin-Unet builds upon Swin Transformers and incorporates a U-shaped encoder-decoder architecture with skip connections, similar to the classical U-Net framework but without any convolution operations.
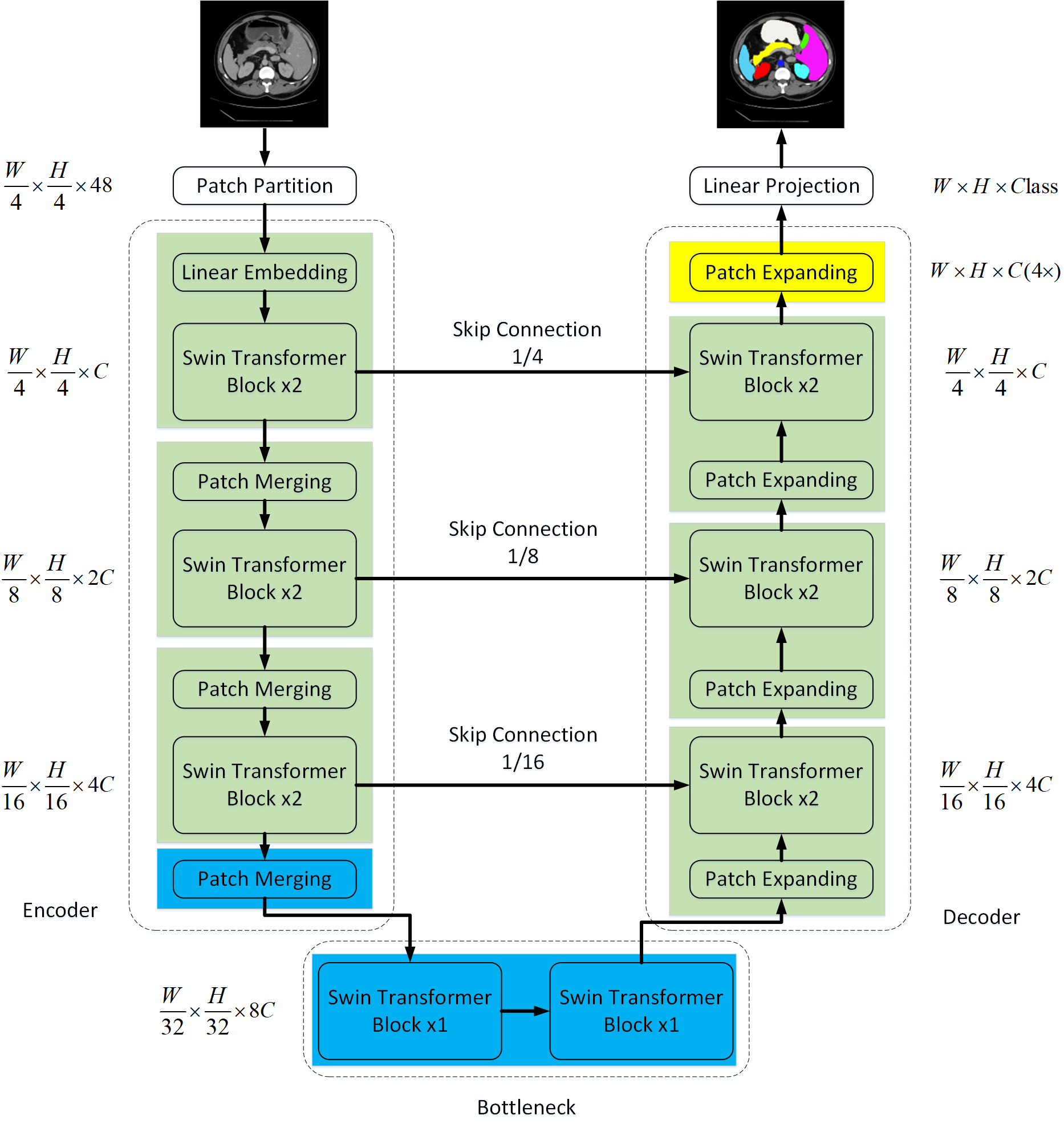
Figure 1: The architecture of Swin-Unet, consisting of encoder, bottleneck, decoder, and skip connections—constructed using Swin Transformer blocks.
The process begins with tokenizing the input images into non-overlapping patches, which are then processed through Swin Transformer blocks in the encoder to capture hierarchical feature representations. A novel patch expanding layer in the decoder is utilized for up-sampling, which enhances resolution by reshaping features without interpolation. The combined hierarchical learning with Swin Transformer blocks allows for efficient local-global feature learning.
A key component of this architecture is the Swin Transformer block, which adopts window-based multi-head self-attention (W-MSA) and shifted windowing (SW-MSA) mechanisms. This structure allows the network to compute self-attention efficiently across partitioned image patches, providing enhanced contextual and hierarchical feature extraction capabilities.
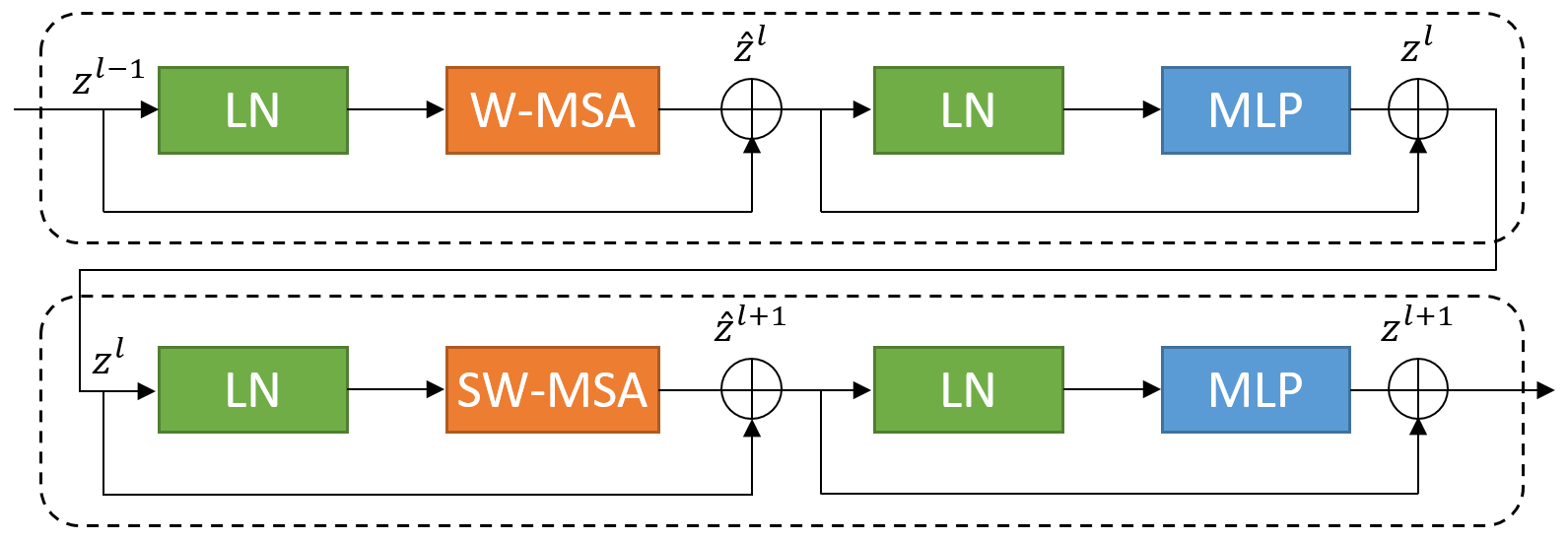
Figure 2: Swin Transformer block.
Experimental Evaluation
The benchmark evaluation of Swin-Unet was conducted on the Synapse multi-organ CT and ACDC datasets, demonstrating superior performance over existing methods. Swin-Unet achieved a Dice-Similarity Coefficient (DSC) of 79.13% and Hausdorff Distance (HD) of 21.55 on the Synapse dataset, with improved edge prediction accuracy reflected by the HD metric.
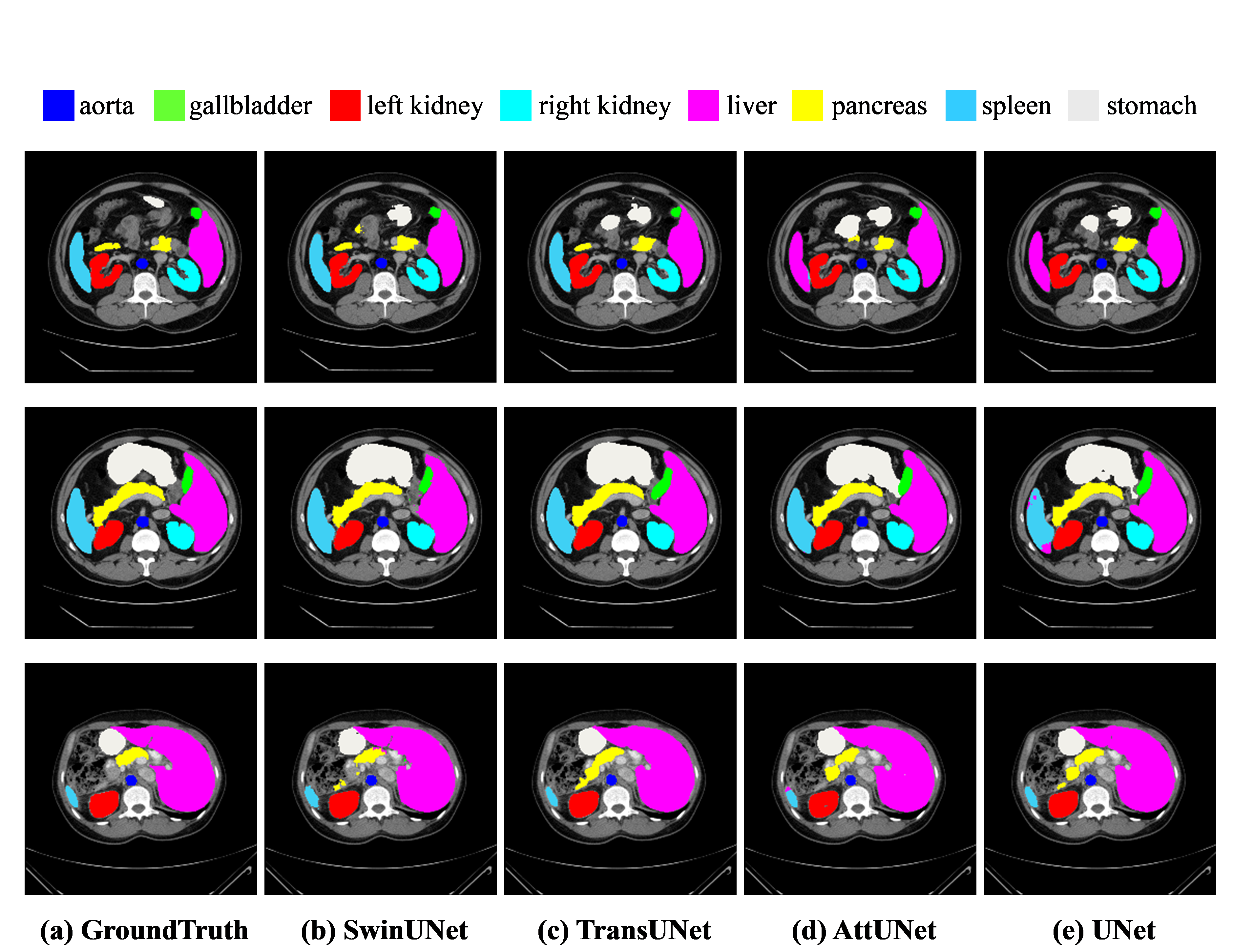
Figure 3: The segmentation results of different methods on the Synapse multi-organ CT dataset.
The architecture effectively mitigates over-segmentation common in CNN-based methods, underscoring Swin-Unet's capability in learning robust long-range semantic information.
Ablation Studies
Various ablation studies were performed to assess the impact of different design choices on the model's performance:
- Up-sampling Strategy: The patch expanding layer outperformed bilinear interpolation and transposed convolution in segmentation accuracy, highlighting its efficacy in feature resolution recovery.
- Number of Skip Connections: The best performance was observed with three skip connections, ensuring robust spatial information recovery across scales.
- Input Size and Model Scale: While increasing input resolution and model scale marginally improved accuracy, it significantly increased computational demands, leading to a trade-off between performance and efficiency.
Conclusion
Swin-Unet leverages the Swin Transformer for effective segmentation tasks, demonstrating that pure transformer architectures can surpass traditional convolution-based methods in medical image analysis. The integration of the hierarchical structure and attention mechanisms allows Swin-Unet to efficiently glean semantic information, establishing a promising approach for robust 2D medical image segmentation.
Future research may focus on adapting Swin-Unet for 3D medical image segmentation, and exploring pre-training strategies to further improve its applicability in medical imaging contexts.

