- The paper presents the Anchor-Captioner method that generates multiple diverse captions to better capture detailed textual and visual relationships.
- It employs a dual-step process with an Anchor Proposal Module for text token grouping and an Anchor Captioning Module to refine visual outputs.
- Experimental results on the TextCaps dataset show state-of-the-art improvements in CIDEr and BLEU scores over baseline methods.
"Towards Accurate Text-based Image Captioning with Content Diversity Exploration" (2105.03236) - An Expert Review
Introduction and Motivation
The paper addresses the challenge of text-based image captioning (TextCap), a task valuable for detailed machine understanding of complex scenes, especially where text is omnipresent. Traditional image captioning methods often generate a single global caption, which fails to capture complex text and visual interrelationships within images, making them less effective for comprehensive descriptions. The authors propose the Anchor-Captioner method to tackle these limitations by generating multiple, diverse captions, each focusing on different image segments. This approach thoughtfully addresses three core challenges: optimal text selection, understanding text relationships, and content diversity in caption generation.
Methodology: The Anchor-Captioner Approach
The Anchor-Captioner method is founded on two principal components: the Anchor Proposal Module (AnPM) and the Anchor Captioning Module (AnCM).
- Anchor Proposal Module (AnPM): AnPM begins with anchor prediction, where important text tokens are identified and assigned as anchors. Subsequently, a recurrent neural network (RNN) models relationships between these anchor tokens and forms anchor-centered graphs (ACGs), encapsulating relevant textual information for further captioning.
- Anchor Captioning Module (AnCM): This module employs a dual-step captioning process. First, a visual-captioner generates a global, visual-specific caption. Following this, a text-captioner refines these initial outputs by leveraging constructed ACGs to produce multiple refined captions containing more detailed text information. Such a hierarchical process ensures thorough exploration of multimodal information leading to more nuanced and diverse image descriptions.
The paper emphasizes an innovative solution to the problem by not only proposing the architectural novelty of Anchor-Captioner but showcasing its integration with existing OCR technology to foster detailed captioning capabilities.
Experimental Framework and Results
Extensive experiments were conducted using the TextCaps dataset, which contains complex images annotated with both visual and textual content. The evaluation reveals that Anchor-Captioner achieves state-of-the-art performance, marked by significant improvements in metrics like CIDEr and BLEU scores over baseline models like M4C-Captioner.
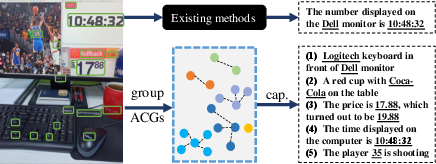
Figure 1: Comparison with existing methods. For a given image, existing methods tend to generate only one global caption. Unlike them, we first select and group texts to anchor-centred graphs (ACGs), and then decide which parts of the texts to copy or paraphrase.
The diversity and accuracy of the generated captions are underscored by better coverage of OCR tokens and the production of captions that align well with human interpretations. The visualizations provided in the paper further illustrate how this method can cover a broader range of content within images, offering multiple perspectives—a critical step towards comprehensive scene understanding.
Implications and Future Directions
The research has profound implications for tasks requiring detailed scene understanding, such as assisting visually impaired individuals or enhancing autonomous systems that operate in text-rich environments. By overcoming the limitations of single-caption models, the approach presents a case for revising current standards in image captioning tasks.
For future developments, the researchers suggest enhancing the OCR capabilities and considering hybrid models that could balance between global and instance-specific captions depending on scene complexity. Additionally, the authors note the potential scalability of their method to other domains such as video captioning, wherein temporal dynamics add another layer of complexity to the captioning task.
Conclusion
In conclusion, the paper presents a substantial advancement in the field of text-based image captioning through its Anchor-Captioner method, which effectively addresses the multi-faceted challenges of detailed text and image content description. The model's architecture, coupled with its promising results on TextCaps, sets a new benchmark for future research in developing more context-aware and content-diverse captioning systems.