- The paper demonstrates that the Bird's Eye probe quantifies how well BERT encodes complete linguistic graph structures using mutual information.
- It employs graph embeddings to transform syntactic and semantic structures into continuous spaces, revealing that syntactic features are more robustly captured than semantic ones.
- The probe's information-theoretic approach addresses inaccuracies of classifier-based methods, offering reliable insights into language model interpretability.
The paper introduces Bird's Eye, an information-theoretic probe designed to investigate the extent to which pretrained LLMs capture linguistic graph structures. This study leverages mutual information (MI) to elucidate the encoding of syntax and semantic information in models like BERT. By embedding linguistic graphs into continuous spaces, Bird's Eye estimates MI to evaluate the representation of entire linguistic graphs, such as dependency parsers and semantic graphs, in contextualized word embeddings.
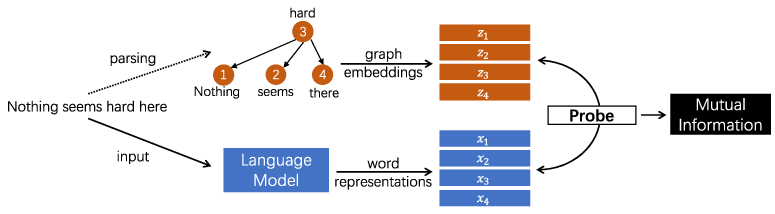
Figure 1: Methodology of Bird's Eye: To probe pretrained LLMs, linguistic graphs are embedded in a continuous space and the mutual information between graph embeddings and word representations is calculated.
Methodology
Bird's Eye moves away from traditional classifier-based probing, which suffers from randomness and potentially measures a model's ability to learn a task rather than its encoding of linguistic phenomena. Instead, Bird's Eye employs a mutual information-based approach that directly estimates the amount of linguistic structure information captured by a model.
To calculate MI, Bird's Eye embeds linguistic graphs into a continuous feature space and then evaluates the MI between these embeddings and word representations produced by the LLM. This evaluation focuses on determining how comprehensive the model's encoding of the graph is.
Bird's Eye is further extended into Worm's Eye to probe localized linguistic information by examining substructures within linguistic graphs, such as specific syntactic dependencies or semantic roles.
Graph Embedding and MI Estimation
The probe begins by transforming linguistic graphs into continuous embeddings using algorithms like DeepWalk. These embeddings provide a suitable basis for estimating MI with high-dimensional contextualized representations from models like BERT. The MI value is computed using a neural estimator, and this value is bounded by control functions to ensure robust interpretation across different graph types.
Experimental Setup
The study investigates the ability of BERT-base and BERT-large models to encode syntactic and semantic graphs. Using datasets such as the Penn Treebank and the AMR Bank, the Bird's Eye probe quantifies the extent to which these models capture entire graph structures.
Models are compared to non-contextual embeddings like GloVe and ELMo-0. Additionally, Worm's Eye analyzes the encoding of specific linguistic information, such as parts of speech and dependency relations.
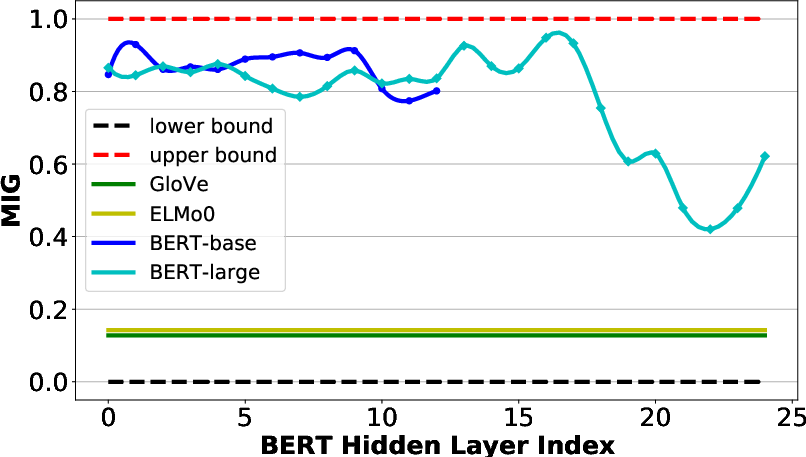
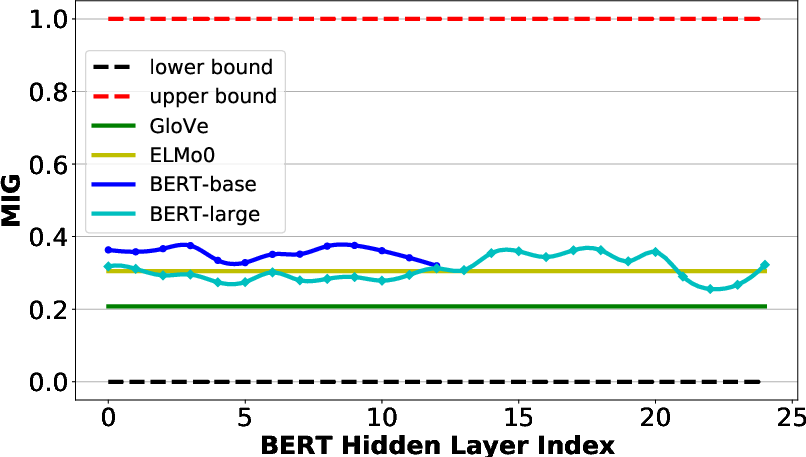
Figure 2: MIG scores with syntactic and semantic structures, respectively for word representations in BERT models (BERT-base with 12 layers and BERT-large with 24 layers). Note that results at the input layer are also reported, where the BERT Hidden Layer Index is 0.
Results and Discussion
Bird's Eye showed that BERT captures considerable syntactic information, especially in lower layers, while semantic information is less prevalent and spread throughout the model. The MIG scores indicated that pretrained models like BERT encode syntactic structures more robustly than semantic graphs, consistent with existing literature that highlights BERT's syntactic proficiency.
For localized information probing with Worm's Eye, specific syntactic structures, such as POS tags and dependencies, were effectively encoded in BERT representations, revealing varied levels of encoding strength.
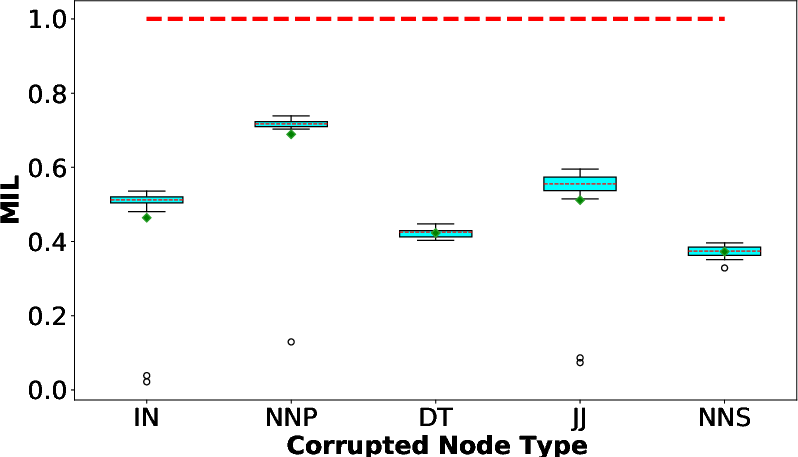
Figure 3: MIL scores of probing 5 types of POS tags (localized syntactic structure) for word representations in BERT-base (output layer). The local structure is decided by the POS tags attached on nodes.
Evaluation of Probing Techniques
The study critically evaluates the reliance on accuracy-based methods, illustrating how variations in model complexity lead to inconsistencies in probing results. This unreliability underscores the advantages of the information-theoretic approach, as it mitigates issues such as overfitting and task-solving tendencies inherent to conventional probes.
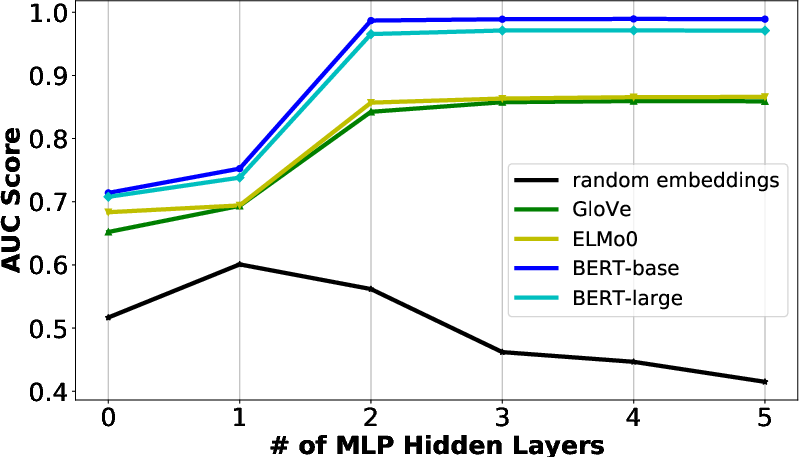
Figure 4: AUC scores of predicting syntactic trees by various word representations.
Conclusion
The Bird's Eye probe provides a robust framework for probing linguistic structures in contextualized representations using mutual information. This methodology advances the understanding of LLM interpretability by focusing on the intrinsic encoding of linguistic phenomena as opposed to task-specific learning. While the current instantiation uses BERT, future work could enhance graph embedding methods and explore other models, potentially unveiling deeper linguistic insights applicable to a broader range of NLP tasks.