- The paper introduces Rotary Position Embedding to integrate absolute and relative positional information directly into transformer self-attention.
- It employs a rotation matrix to encode positions, achieving decaying inter-token dependency and enabling variable sequence lengths.
- Experimental results show faster convergence and superior performance on long-sequence NLP tasks compared to standard positional encodings.
Introduction
The paper "RoFormer: Enhanced Transformer with Rotary Position Embedding" presents a novel method, Rotary Position Embedding (RoPE), for effectively integrating positional information into transformer-based LLMs. RoPE encodes absolute positions using a rotation matrix and simultaneously incorporates explicit relative position dependencies into the self-attention computation. This approach offers several advantages, such as flexibility in sequence length, decaying inter-token dependency with increasing relative distances, and compatibility with linear self-attention architectures.
Background
Transformers have revolutionized the field of NLP by employing self-attention mechanisms to capture long-range dependencies in sequences. While transformers are inherently position-agnostic, effectively encoding position information is crucial for many language tasks. Previous approaches, such as sinusoidal [Vaswani et al., 2017] and trainable position encodings, merely add position information to the context representations but fail to incorporate it directly into the attention mechanism—particularly in architectures designed for linear attention.
Rotary Position Embedding (RoPE)
RoPE is an innovative approach to positional encoding, offering several advantageous properties over traditional methods. It achieves this by:
- Encoding absolute positions with a rotation matrix that allows the integration of explicit relative position encoding into the self-attention mechanism.
- Facilitating sequence length flexibility, which permits variable-length inputs without the need for re-training model parameters.
- Implementing decaying inter-token dependency, which ensures that as the relative distance between tokens increases, their mutual contribution within the attention mechanism progressively decreases.
The implementation of RoPE is visualized in the following diagram:
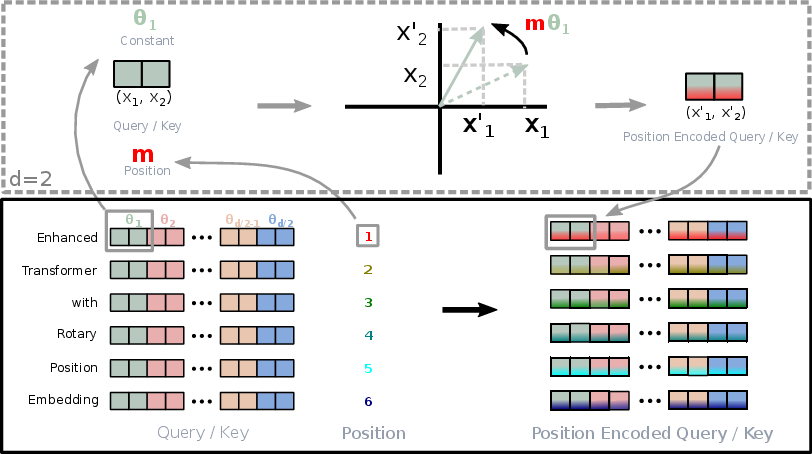
Figure 1: Implementation of Rotary Position Embedding (RoPE).
Properties and Theoretical Insights
Long-term Decay Property
RoPE exhibits a long-term decay property, ensuring that the influence of widely separated tokens in a sequence diminishes over distance. This mirrors the rationale that tokens with vast relative distances should exhibit weaker semantic connections. The exponent in the sinusoidal function yields this decay effect, highlighting RoPE's reflection of linguistic intuition.
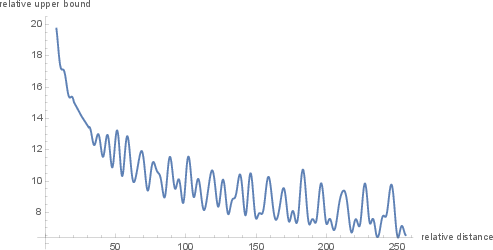
Figure 2: Long-term decay of RoPE.
Integration with Linear Attention
RoPE seamlessly integrates with linear attention mechanisms, such as those used in Performer models, allowing for efficient computation in transformer layers with linear complexity. This integration is accomplished by maintaining the rotational matrix multiplication, preserving the norm of embeddings and ensuring stable learning dynamics.
Experimental Evaluation
Language Modeling Pre-training
RoPE was evaluated in pre-training settings, replacing traditional sinusoidal encodings in BERT models. Results demonstrated faster convergence for RoFormer compared to vanilla BERT, due to RoPE's more effective positional representation.
(Figure 3 - Left)
Figure 3: Evaluation of RoPE in language modeling pre-training. Left: training loss for BERT and RoFormer.
RoFormer was further validated on several NLP tasks from the GLUE benchmark suite, exhibiting superior or comparable performance to BERT in tasks such as semantic equivalence detection and sentiment analysis. RoFormer's handling of longer sequences showed marked improvements, especially when sequence lengths exceeded 512 tokens.
Implications and Future Directions
RoFormer's architectural advancements prompt reconsideration of conventional positional encoding in transformers, enabling more efficient training and improved performance, especially in processing long sequences. Future research could extend RoPE's principles to other domains within machine learning, facilitate advancements in multimodal architectures, or inspire further optimizations in low-resource environments.
Conclusion
"RoFormer: Enhanced Transformer with Rotary Position Embedding" introduces a significant improvement to positional encoding in transformers, through RoPE. By integrating relative positional encoding into self-attention, RoPE enhances both the flexibility and performance of transformer-based models, particularly in handling longer contexts. This method not only ensures more robust pre-training and fine-tuning but also paves the way for scalable, large-scale LLM deployments.