- The paper presents a state-associative learning method that uses synthetic returns to improve credit assignment for delayed rewards in reinforcement learning.
- It demonstrates that augmenting IMPALA with synthetic returns increases sample efficiency, achieving human-level performance 25 times faster on tasks like Atari Skiing.
- The study highlights future avenues for integrating synthetic returns with other RL methods while addressing challenges such as hyperparameter sensitivity and task generalization.
Synthetic Returns for Long-Term Credit Assignment
Introduction
The paper "Synthetic Returns for Long-Term Credit Assignment" (2102.12425) introduces a novel approach to address the challenges experienced by traditional temporal difference (TD) learning in long-term credit assignment problems in reinforcement learning (RL). The authors propose a method called State-Associative (SA) learning that utilizes synthetic returns (SRs) to provide more effective credit assignment, particularly in environments with delayed rewards and intervening non-reward events.
Methodology
SA learning enables direct association between actions and future rewards, irrespective of intervening unrelated events (Figure 1). This is achieved by learning state associations and using them to predict future rewards, termed as "synthetic returns". The key innovation is augmenting the agent's reward computation with these synthetic returns through a backward-looking reward prediction model, which learns the contribution of past states to future rewards.

Figure 1: Diagram illustrating the state-associative learning process, leveraging past state representations for direct credit assignment.
By integrating synthetic returns into existing deep-RL frameworks like IMPALA, the approach allows agents to achieve more efficient learning outcomes on tasks that are especially challenging for standard TD methods.
Experiments and Results
Atari Skiing
The IMPALA augmented with SRs achieves human-level performance 25 times more sample-efficiently compared to the previous state-of-the-art, Agent57 (Figure 2). This demonstration on Atari Skiing, a challenging credit assignment task due to its extended reward delay structure, highlights the practical benefits of synthetic returns.
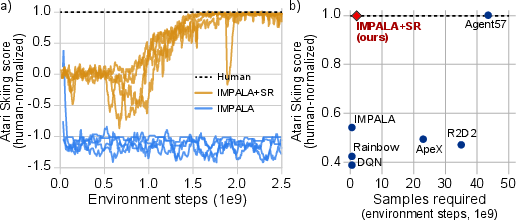
Figure 2: Performance on Atari Skiing, where SR-augmented agents achieve human-level performance significantly faster than previous methods.
Chain Task
In the Chain task, the SR-augmented agent successfully learns to reach the rewarding state by visiting the necessary trigger state, which the baseline IMPALA fails to achieve (Figure 3). This task illustrates the effectiveness of SA-learning in assigning direct credit despite delayed rewards.
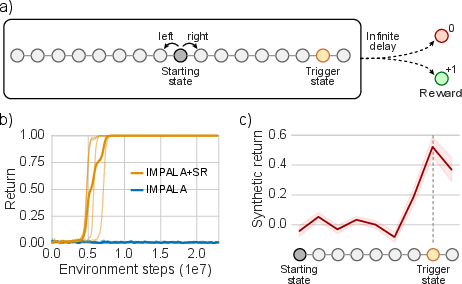
Figure 3: Chain task results showing successful learning by the SR-augmented agent, marked by spikes at the trigger state.
Catch with Delayed Rewards
The SR-augmented agent consistently solves the Catch with delayed rewards task, whereas the baseline struggles significantly (Figure 4). This task serves as a compelling demonstration of the ability to handle long-term credit assignment challenges effectively with SRs.
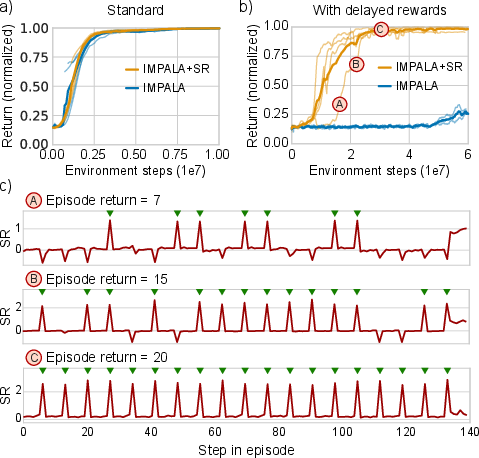
Figure 4: Delayed Rewards in Catch demonstrate successful resolution solely through SA-learning, as shown by aligned SR spikes with successful catches.
Key-to-Door Task
In the Key-to-Door task (Figure 5), only the SR-augmented agent consistently learns to complete all task phases and collect rewards by opening the door, proving SA's advantage in complex multi-phase tasks with distractors.
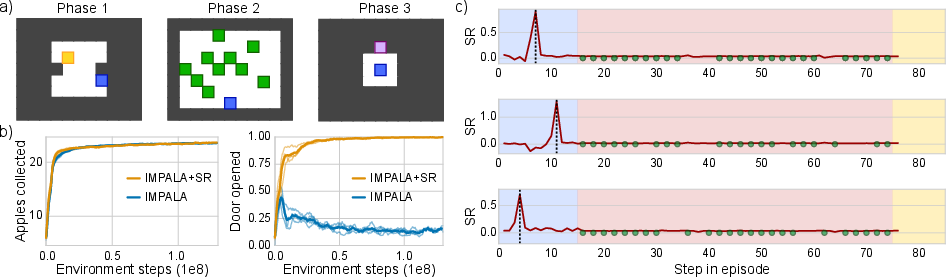
Figure 5: Successful completion of the Key-to-Door task by the SR-augmented agent, showing precise SR spikes aligned with key-collection events.
Implications and Future Work
The proposed SA-learning method has significant implications for enhancing RL agents' ability to solve tasks involving long delays between actions and rewards. While the method has shown promising results, challenges such as the sensitivity to hyperparameters and seed variance, as observed in Atari Skiing experiments (Figure 6), indicate areas for further research and refinement.
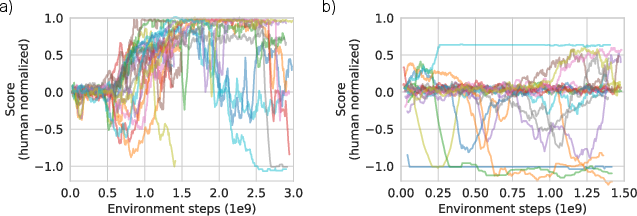
Figure 6: Hyperparameter sensitivity in Atari Skiing presents a challenge for consistency in performance.
Future work will explore extending the utility of synthetic returns to more general RL frameworks and possibly integrating with other advancements such as RUDDER or counterfactual-based methods. Improvements on algorithmic robustness and generalization to diverse task environments are also potential directions.
Conclusion
Synthetic Returns for Long-Term Credit Assignment provides a forward-thinking approach to overcome the limitations of temporal difference learning in environments with delayed rewards. By using state-associative learning to enhance traditional RL agents, this method offers a pathway to more effective and efficient learning in complex scenarios where long-term planning is crucial.

