- The paper demonstrates a zero-shot approach where a 12B parameter autoregressive transformer generates images from text without task-specific training.
- It employs a discrete VAE to efficiently encode 256x256 images into a 32x32 grid, reducing computational load while preserving visual quality.
- Experiments reveal superior human-evaluated realism on MS-COCO with competitive FID scores, highlighting strong visual and semantic generalization.
Zero-Shot Text-to-Image Generation
The paper "Zero-Shot Text-to-Image Generation" introduces an approach based on a transformer model for generating images from text descriptions without the need for task-specific training data. The focus is on demonstrating competitive performance with existing models specifically trained on particular datasets, accomplishing tasks in a zero-shot manner using a large autoregressive transformer.
Methodology
The approach employed involves using a transformer model to autoregressively process combined data streams of text and image tokens. The core architecture leverages a 12-billion parameter transformer which models text and image pairs through training on a massive dataset of 250 million image-text pairs collected from the internet.
To handle high-resolution images efficiently, a discrete VAE (dVAE) is utilized. The VAE compresses each 256×256 RGB image into a 32×32 grid of image tokens, significantly reducing the computational demands on the transformer without severe loss of visual quality (Figure 1).

Figure 1: Comparison of original images (top) and reconstructions from the discrete VAE (bottom). The encoder downsamples the spatial resolution by a factor of 8.
Training Strategy
Training is conducted in two stages:
- Stage One: A discrete VAE encodes images into a latent space using a vocabulary of 8192 possible tokens.
- Stage Two: An autoregressive transformer is trained to model the joint distribution of text and image tokens.
The joint modeling uses evidence lower bound (ELB) maximization, effectively aligning the training objective with the system's generative capabilities, enabling the model to generalize to previously unseen tasks and data arrangements.
Data and Scale
The training dataset significantly surpasses standard benchmarks such as MS-COCO, both in size and variability, being specially curated to include Conceptual Captions and subsets from YFCC100M. This large-scale data provides the necessary semantic and visual diversity required to train a general-purpose model that can perform tasks zero-shot.
Experiments and Results
Image Quality and Human Evaluation
The system's performance is evaluated on zero-shot text-to-image synthesis tasks compared to prior models, demonstrating superior visual realism and diversity as judged by human evaluators. In tests against models like DF-GAN, the trained transformer outperformed in terms of quality on MS-COCO captions, with preferences from human evaluations favoring it 90% of the time (Figure 2).
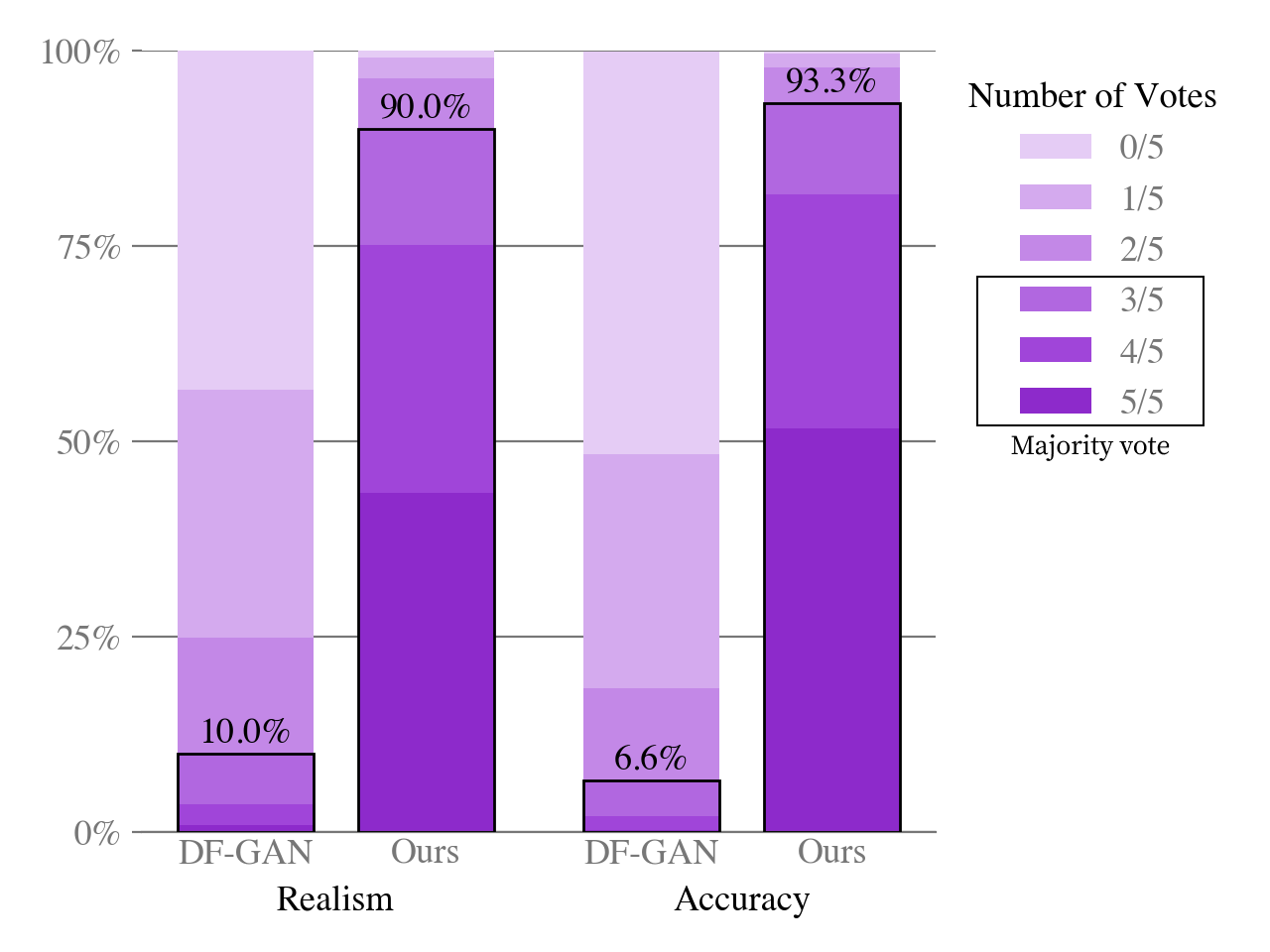
Figure 2: Human evaluation of our model vs prior work (DF-GAN) on captions from MS-COCO.
Quantitative Metrics
While the trained model achieves competitive Fréchet Inception Distance (FID) scores on MS-COCO, it trails on more specialized datasets like CUB (Figure 3). These results suggest constraints linked to the diversity of the training data and hint at areas for possible model improvement through fine-tuning.

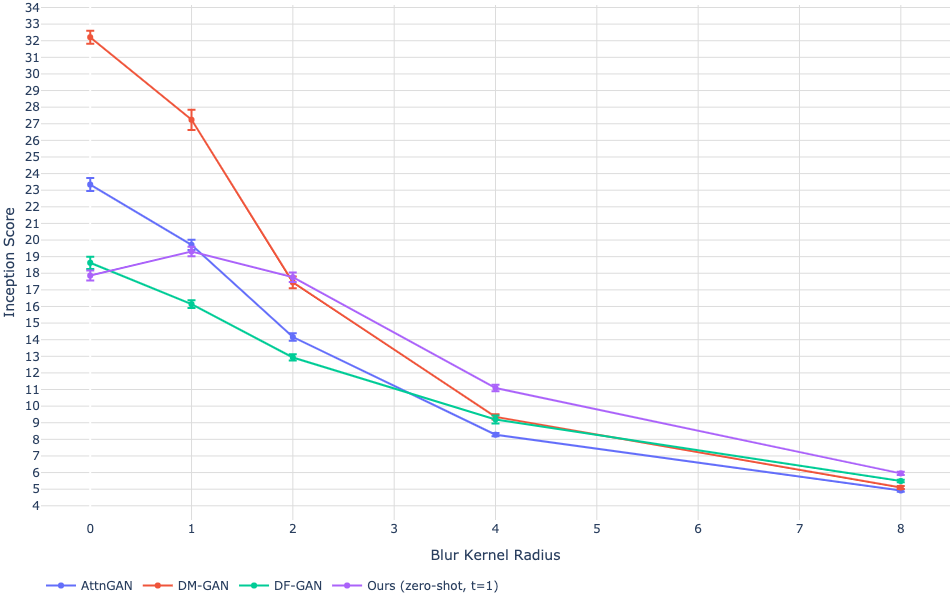
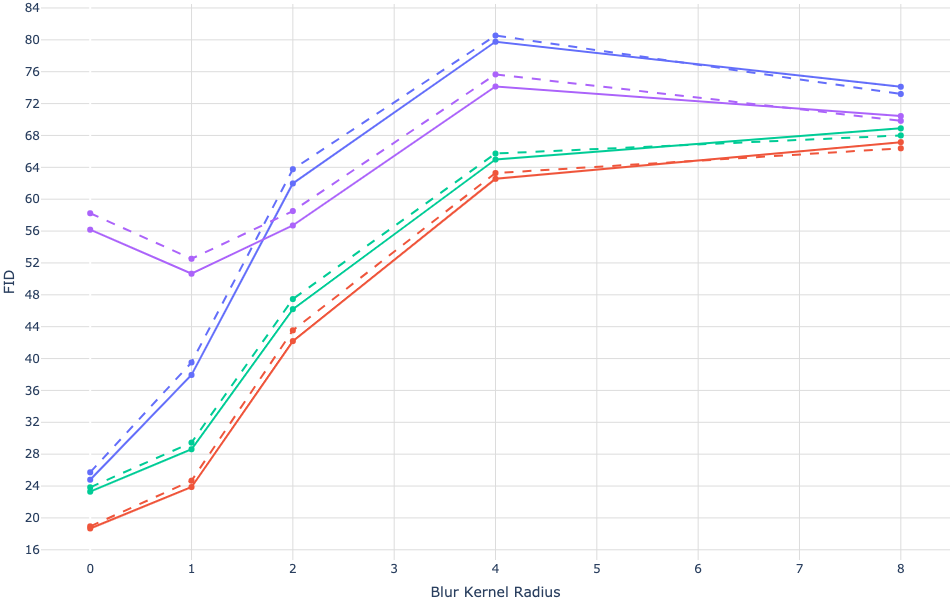
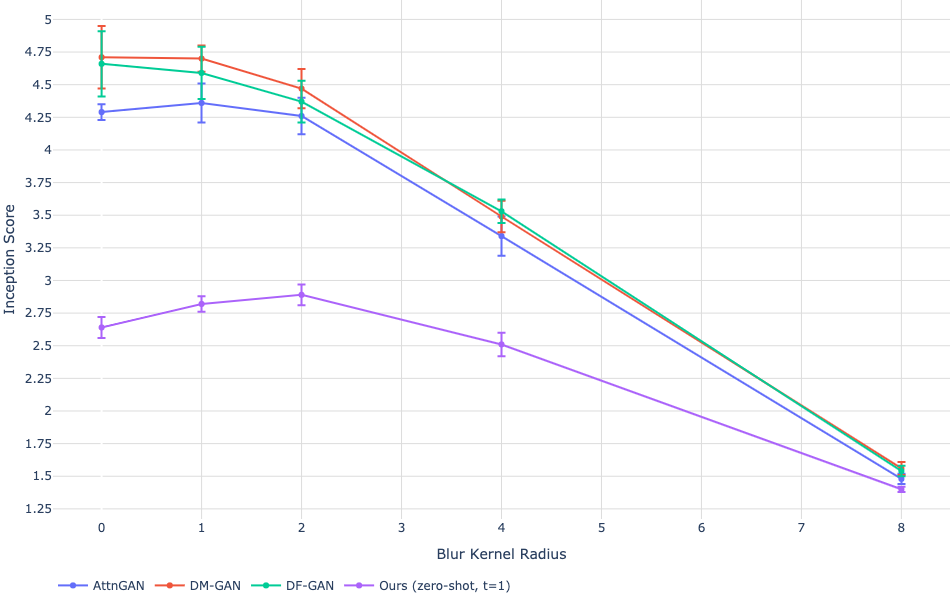
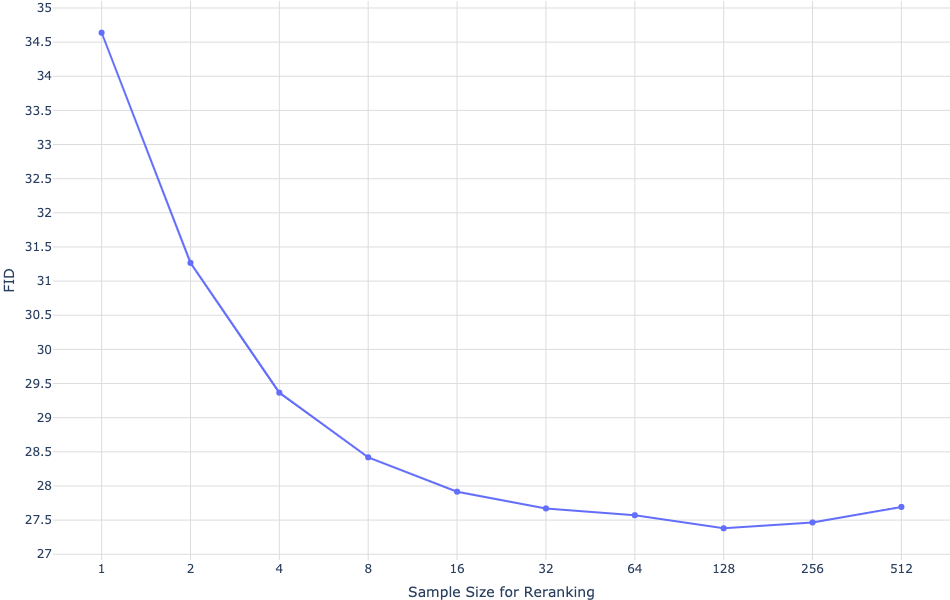
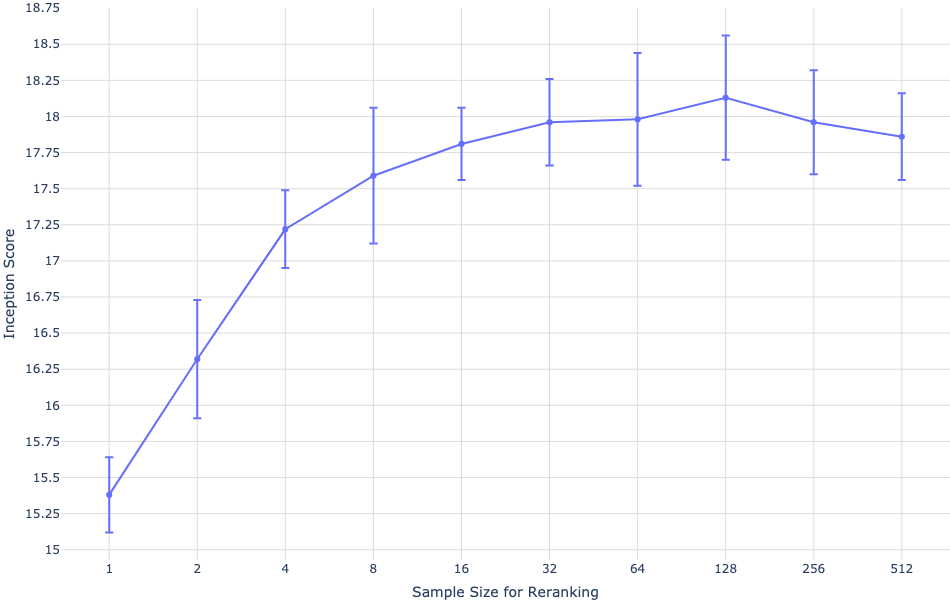
Figure 3: Quantitative results on MS-COCO and CUB.
Implementation Considerations
Computational Efficiency
Training such a large-scale model demands significant computational resources. The implementation employs per-resblock gradient scaling and smart parameter sharding to facilitate mixed-precision training, effectively managing memory and computational overhead across distributed systems (Figure 4).
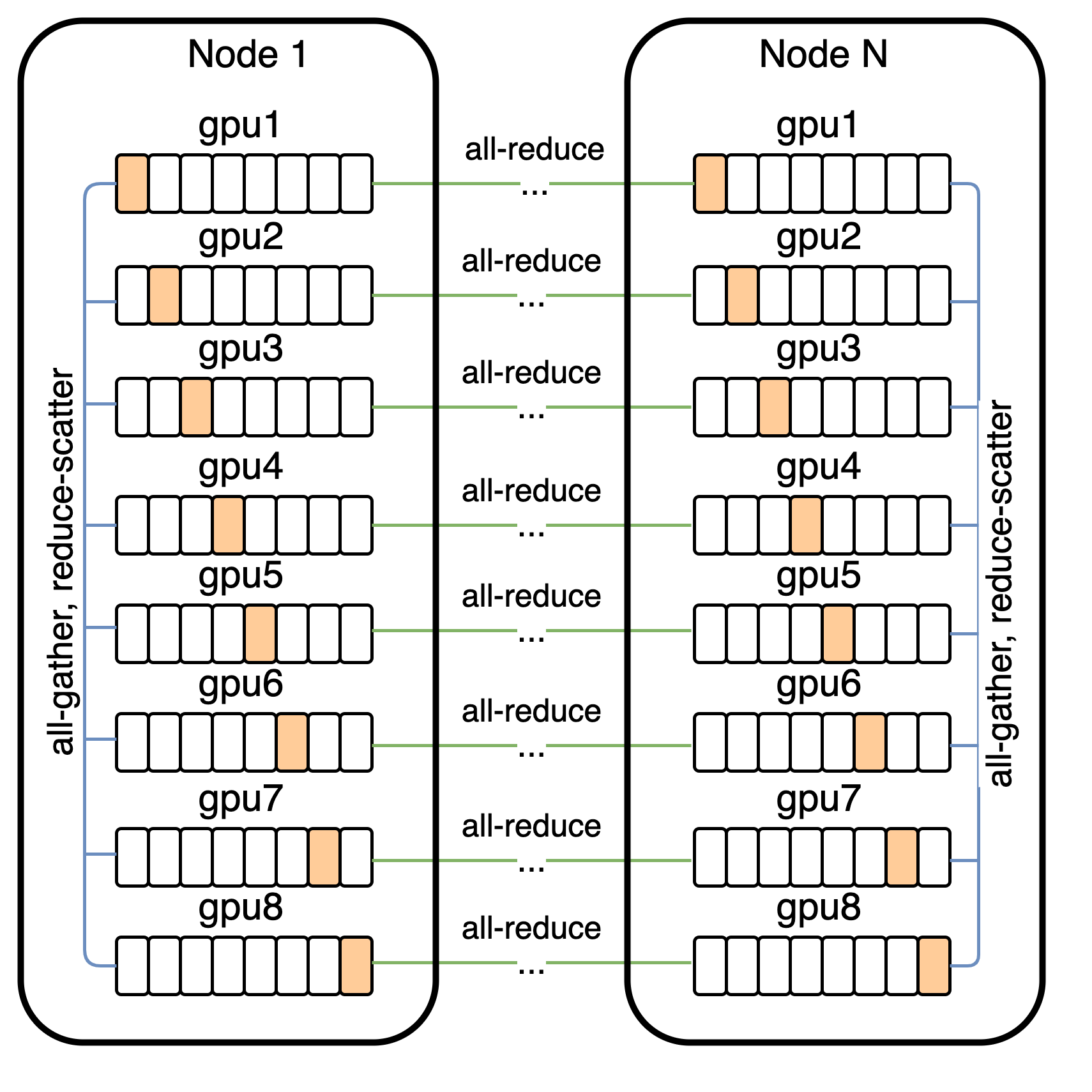
Figure 4: Communication patterns used for distributed training.
Technical Challenges
Handling underflow in gradient computations and training large transformers in 16-bit precision presented technical challenges that were solved through innovative techniques like PowerSGD for gradient compression without sacrificing model performance significantly. The robustness of the implementation to such issues can provide insights for future large-scale model deployments.
Conclusion
The paper illustrates how scaling both model size and data, combined with advanced tokenization and training strategies, can achieve zero-shot capabilities in text-to-image generation. The model's adaptability to perform new tasks without additional specific training paves the way for further research into foundational models that can generalize across a wide range of tasks and domains. Future directions could involve fine-tuning for better task-specific performance or refining data handling techniques to further boost the model's zero-shot generalization efficacy.