- The paper introduces a self-training paradigm where randomly initialized learned optimizers evolve via population-based training, achieving notable performance gains over hand-designed methods.
- The methodology employs a three-layer framework combining gradient descent, meta-training, and evolutionary selection to refine optimizer parameters effectively.
- Experimental results demonstrate that iterative evolution of these learned optimizers leads to superior performance compared to fine-tuned Adam across various tasks.
Training Learned Optimizers with Randomly Initialized Learned Optimizers
Introduction
The paper presents a strategy for training neural-network-based learned optimizers without the reliance on pre-existing hand-designed optimizers, proposing an innovative approach wherein a population of randomly initialized learned optimizers are employed to train themselves. This work uses population-based training (PBT) to facilitate self-training, showcasing a positive feedback loop whereby optimizers improve iteratively through their application in meta-training tasks. This approach emphasizes the potential for constructing systems that optimize themselves, reducing manual intervention and potentially enhancing optimization performance beyond standard methods like Adam.
Methodology
The core methodology involves launching a set of neural-network-parameterized learned optimizers, initialized randomly, and evolving them through PBT. The hierarchy of training involves three nested layers: a base layer using gradient descent for the target model, a middle layer where learned optimizers enhance their parameters, and a final layer employing PBT to refine these optimizers. This paradigm allows for iterative, self-improving training cycles.
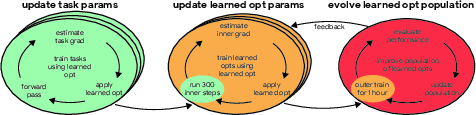
Figure 1: Schematic of the three nested layers of learning when training a learned optimizer.
In practice, a population of 10 learned optimizers is maintained, with each optimizer evaluated on a diverse set of problem types, including RNNs for language modeling and CNNs for image classification. PBT is executed by comparing optimizer performance over 100 tasks bi-hourly and selecting better-performing optimizers for continued training. The evolution involves integrating stochastic elements like random outer-optimizer selection or varying truncation lengths for gradient unrolling, supporting diverse evolution strategies.
Experimental Results
The experimentation validates the proposed approach by demonstrating effective self-training of learned optimizers. Initially, the optimizers’ performance was poor due to random initialization. Over time, the population significantly enhanced its performance, ultimately outperforming the hand-designed Adam optimizer fine-tuned for individual tasks.
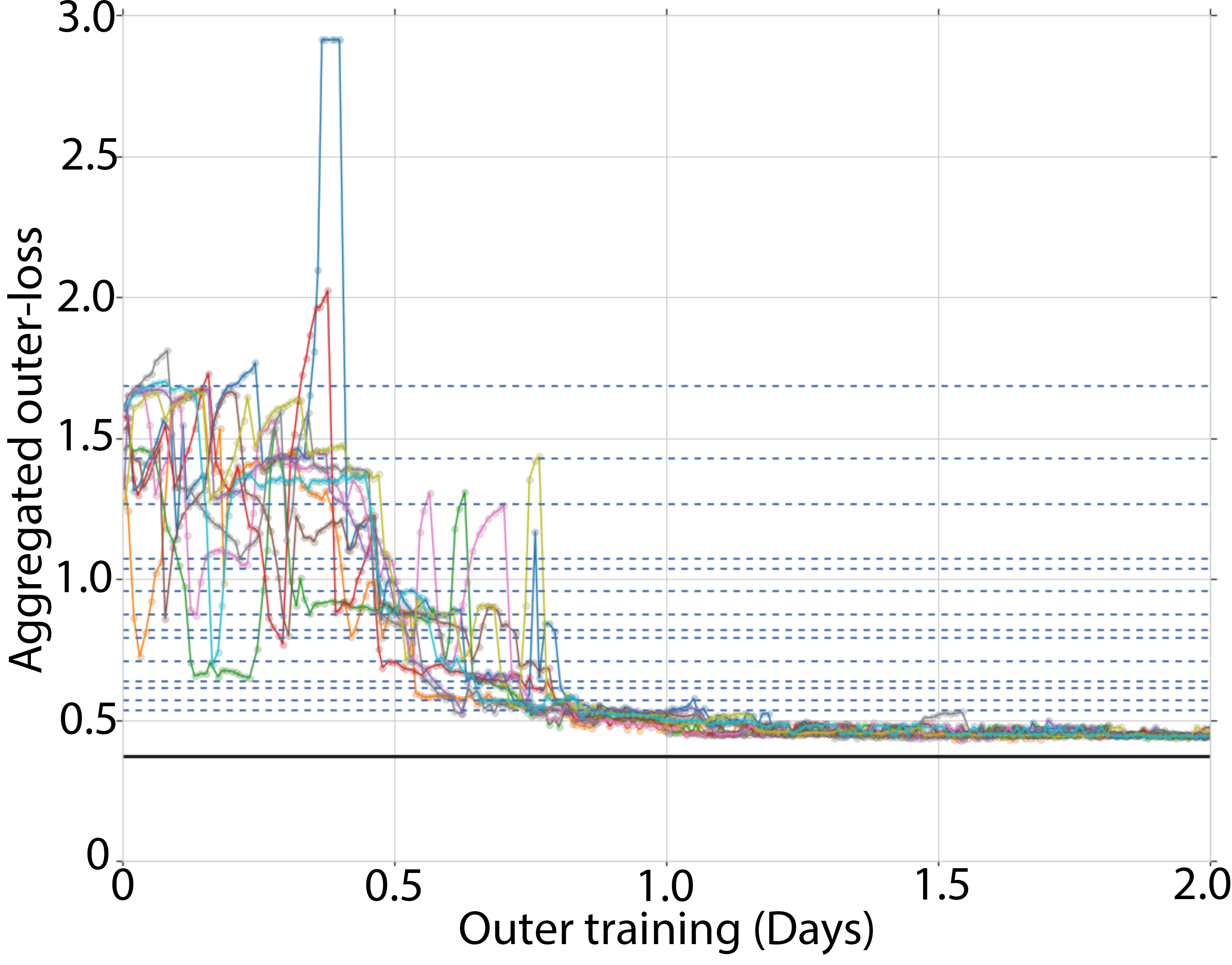
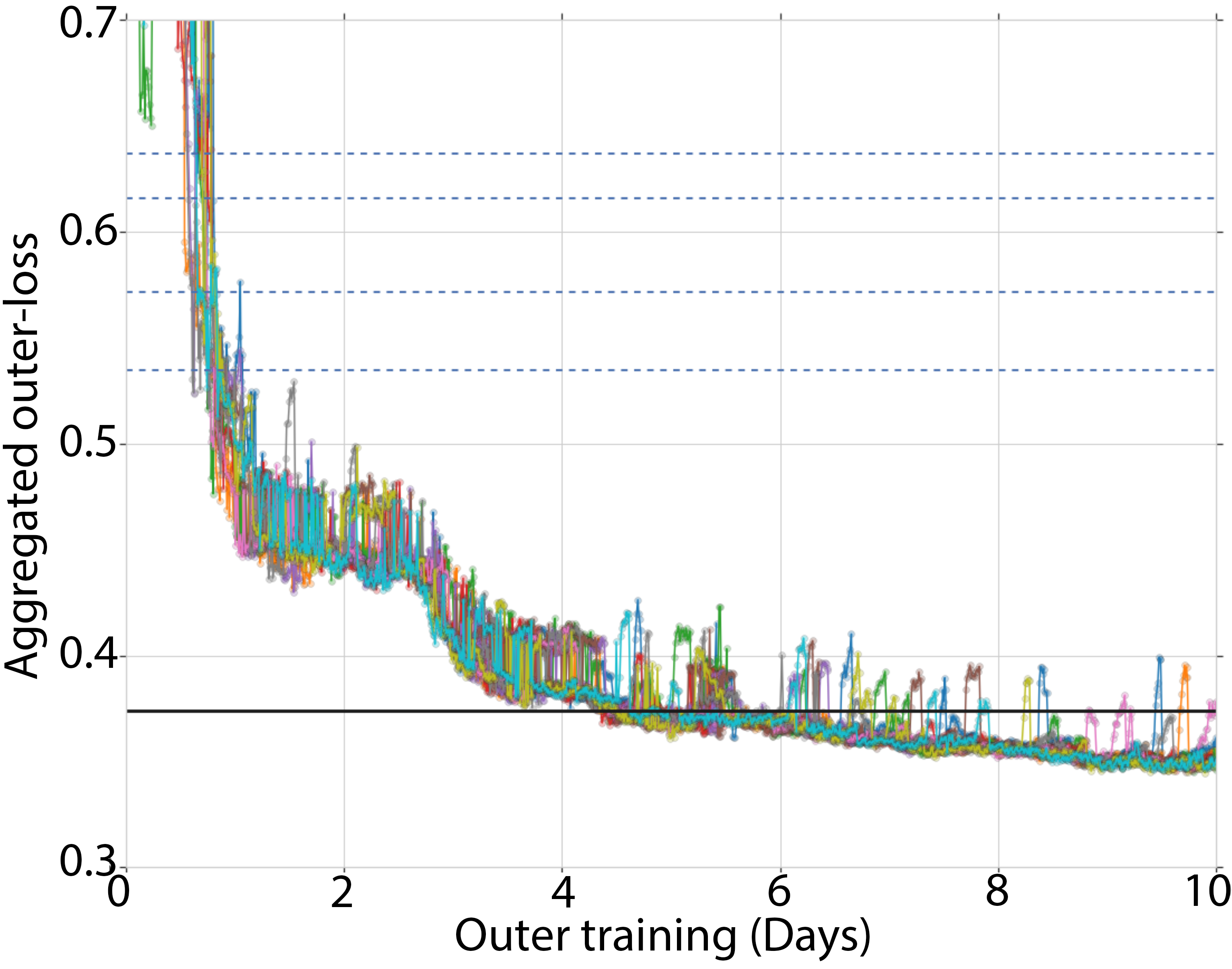
Figure 2: Training curves showing learned optimizer performance against Adam with various learning rates.
The training dynamics, as illustrated in Figure 2, reflect the growth from initial divergence to superior optimization capability, enabled by the positive reinforcement inherent in the self-optimizing strategy.
Critical literature situates this approach alongside other meta-learning and hyperparameter optimization techniques, such as gradient-based methods and other PBT applications. Unlike traditional methods that constrain learning to hyperparameter modifications, this framework broadens the learning scope to full algorithmic optimization, yielding more substantial performance gains.
Discussion and Future Implications
This investigation introduces a compelling trajectory in AI systems design where learning algorithms recursively improve their capabilities. Such feedback loops herald transformative implications for machine learning, particularly regarding scalability and efficiency in optimization tasks. As AI systems tackle increasingly complex challenges, frameworks incorporating self-reinforcing learning routes could facilitate reduced reliance on manual engineering and broad enhancements in methodological robustness.
Conclusion
The study presents a viable method for non-reliant, self-improving optimizer training, showcasing the potential for substantial performance advancements and reduced requisite engineering intervention. Future research could explore further scalability, reduction of initial computational overhead, and adaptation across broader optimization contexts, pushing the frontier of autonomous AI systems design.