- The paper introduces the CrossNER dataset to overcome cross-domain NER limitations by incorporating domain-specific entity labels.
- It employs domain-adaptive pre-training with integrated corpora and span-level masking to boost model performance.
- Experimental results demonstrate improved few-shot F1-scores and superior transferability across politics, science, music, literature, and AI domains.
"CrossNER: Evaluating Cross-Domain Named Entity Recognition"
Introduction
This paper presents the "CrossNER" dataset, a significant contribution to the field of Named Entity Recognition (NER) by addressing cross-domain challenges. Traditionally, NER systems struggle to generalize across domains due to the scarcity of annotated samples in new domains. Current benchmarks often fail to capture domain-specific entities, limiting the efficacy of cross-domain evaluations. The authors introduce a new dataset with diverse domains, each exhibiting unique entity categories, to overcome these limitations. Additionally, the study explores domain-adaptive pre-training techniques to enhance model performance across multiple domains.
CrossNER Dataset
The CrossNER dataset includes labeled NER data across five domains: politics, natural science, music, literature, and AI. It is designed to include domain-specific entities, such as "politician" for politics and "musical artist" for music, providing a more comprehensive evaluation of cross-domain NER models. The dataset also includes unlabeled domain-related corpora, utilized for domain-adaptive pre-training (DAPT), enhancing the transferability of models to new domains with minimal annotated samples.
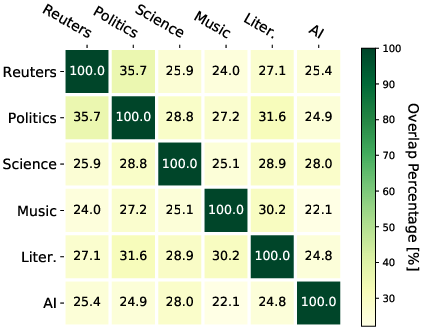
Figure 1: Vocabulary overlaps between domains (\%).
Domain-Adaptive Pre-training
The study employs BERT for domain-adaptive pre-training, examining corpus types and masking strategies to improve domain adaptation. Three corpus types are explored: domain-level, entity-level, and task-level. The integrated corpus, a combination of the latter two, proves most effective. Span-level masking, inspired by SpanBERT, is used to mask contiguous spans rather than individual tokens, providing a more challenging and beneficial pre-training task for domain adaptation.
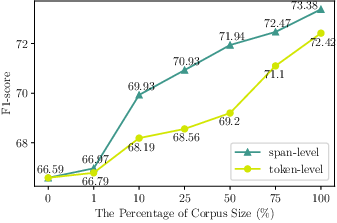
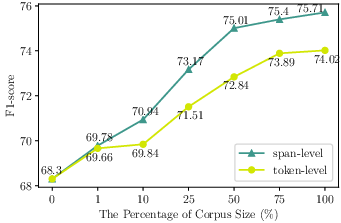
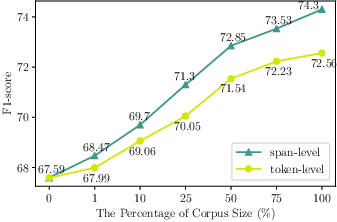
Figure 2: Directly Fine-tune.
Experimental Evaluation
The paper evaluates cross-domain NER models using the CrossNER dataset. Three adaptation strategies are explored: directly fine-tuning on the target domain, pre-training on the source domain before fine-tuning on the target domain, and joint training on both source and target domains. Pre-training using span-level masking with the integrated corpus achieves superior performance, illustrating the effectiveness of focused domain-specific pre-training.
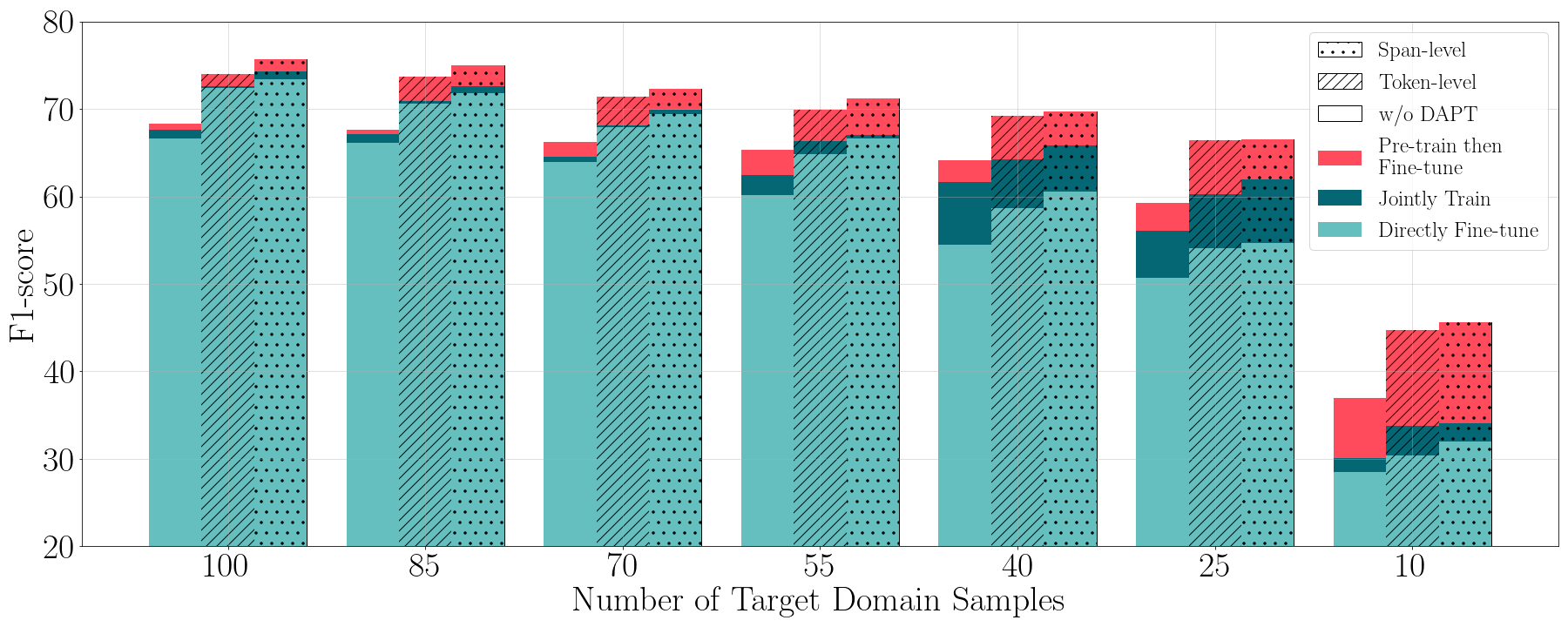
Figure 3: Few-shot F1-scores (averaged over three runs) in the music domain.
Results and Analysis
The results demonstrate the advantages of pre-training with task- and entity-focused corpora. Integrated corpora with span-level masking consistently outperform existing models across domains, with notable improvements in few-shot learning scenarios. The study highlights the complexity of hierarchical entity structures, which can lead to misclassifications, underscoring the challenges of cross-domain NER.
Conclusion
The introduction of the CrossNER dataset, coupled with robust domain-adaptive pre-training strategies, provides a new benchmark for evaluating cross-domain NER models. This work paves the way for further advancements in domain adaptation, particularly in resource-scarce settings. The dataset and insights offered by this paper are expected to stimulate ongoing research in NER domain adaptation, promoting the development of models capable of adapting quickly and effectively to diverse and specialized domains.

